Weeks
- Week 1: Understanding the Challenge
- Week 2: Understanding the Action Space
- Week 3 - 4: Understanding the Observation Space
- Week 5: Understanding the Reward
- Week 6 - 8: General Techniques of RL
- Week 9 - 10: Unorthodox Approaches
Background
The AI for Prosthetics challenge is one of NIPS 2018 Competition tracks. In this challenge, the participants seek to build an agent that can make a 3D human model with prosthetics run.
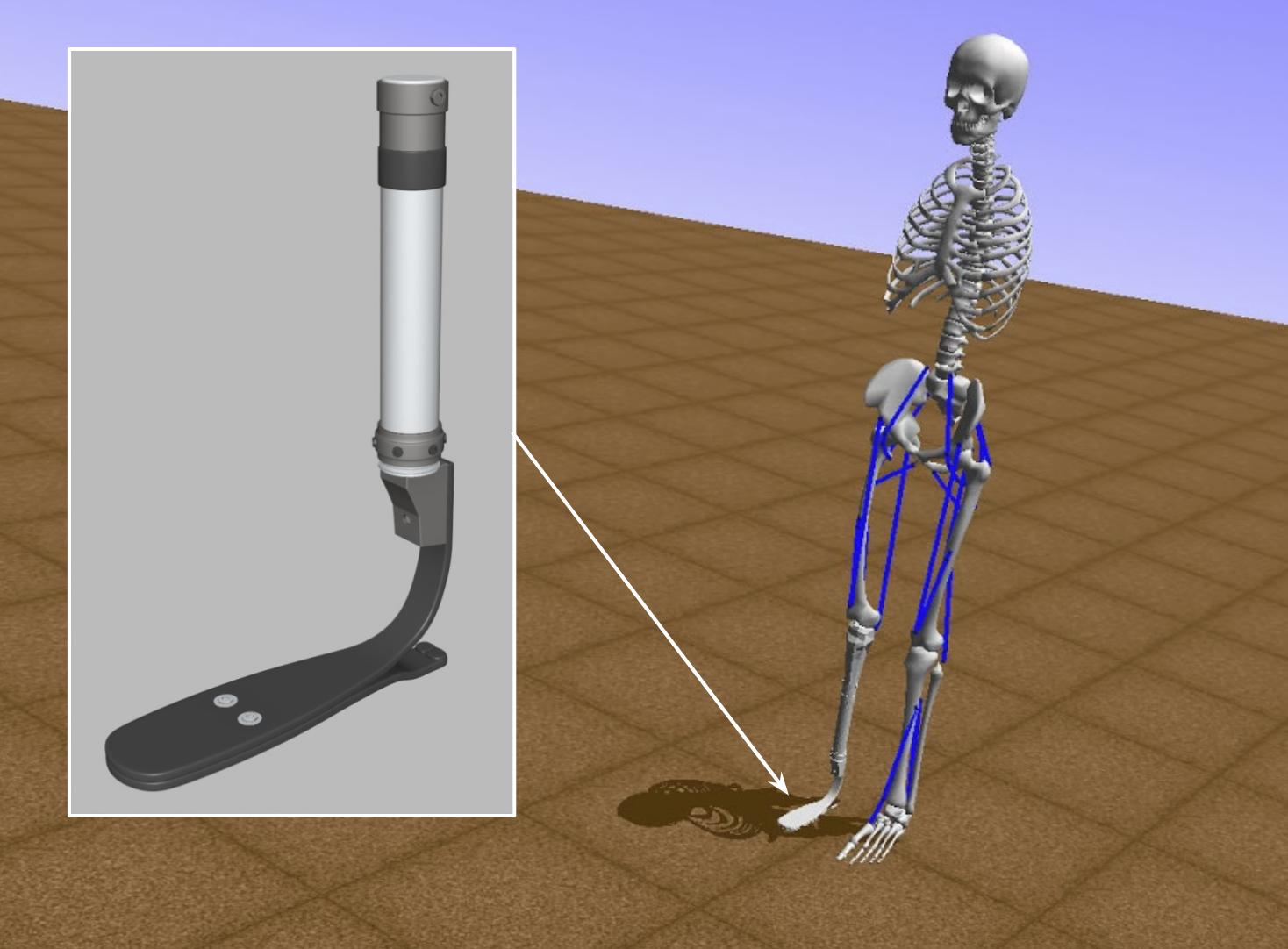
This challenge is a continuation of the Learning to Run challenge (shown below) that was part of NIPS 2017 Competition Track. The challenge was enhanced in three ways:
- Experimental data is allowed
- The model can fall sideways (2D to 3D: Added $z$-axis)
- A model has a prosthetic leg

Installation
To start the challenge, you first need to install few packages with Anaconda.
conda create -n opensim-rl -c kidzik opensim python=3.6.1
source activate opensim-rl
conda install -c conda-forge lapack git
pip install git+https://github.com/stanfordnmbl/osim-rl.git
If everything was installed correctly, the following command should exit without any output or error:
python3 -c "import osim"
If you encounter any error during the installation process, try checking out the official FAQ for solutions to common errors.
Environment
from osim.env import ProstheticsEnv
env = ProstheticsEnv()
The environment is provided in the osim-rl package and follows the conventions of OpenAI Gym. In other words, we can use helpful functions and attributes like env.reset(), env.step(), env.observation_space and env.action_space to understand the environment better.
To create an agent, we should understand what its inputs and outputs are. The input is the observation given by the environment, and the output is the action chosen by the agent, so let’s look at the observation space and action space.
Observation Space
print(env.observation_space) # Returns `Box(158,)`
The observation space has a type of gym.spaces.Box. If you are unfamiliar with OpenAI Gym, you can just think of each observation as a list of 158 features. (Read more about Box() here.)
observation = env.reset(project=False)
observation, _, _, _ = env.step(action, project=False)
To learn more about the observation, we can also pass project=False to env.reset() or env.step(). When project=True (the default), the observation is a list of length 158. However, with project=False, the observation is returned as a dictionary with key strings explaining the meaning behind each number.
{ 'body_acc': { 'calcn_l': [ 1253.6888287987226,
453.41172562050133,
-462.8844724817433],
'femur_l': [ 3552.7596723666484,
102.32773696018944,
-24.145907744606134],
'femur_r': [ 3577.239291929728,
97.25560037366972,
-24.145907744606134],
...
Action Space
print(env.action_space) # Returns `Box(19,)`
print(env.action_space.low) # Returns list of 19 zeroes
print(env.action_space.high) # Returns list of 19 ones
print(env.action_space.sample()) # Returns a random action
The action space is also formatted with gym.spaces.Box. A valid action is a list of length 19, with each element being a number in the interval $[0, 1]$. The actions indicate the amount of force to apply to each muscle.
osim-rl-helper
I created a public GitHub repository with starter code for the competition. If you are unsure about where to start, I recommend checking it out!.
Agent
I like trying multiple ideas before converging to one, and I like to keep track of every changes I have made. Thus, I created an Agent class that will act as a template for all agents to keep track of my failed endeavors. The functions in each agent class will differ greatly by their methods, but they will have 2 things in common: they have to be run locally and they had to be submitted to server. Thus, I implemented two functions Agent.test() and Agent.submit() that uses the unimplemented Agent.act() function to retrieve an action from the agent.
However, when I tried to submit the agent, I repeatedly faced two errors:
- The default
env_idfor client was wrong: I needed to setenv_id='ProstheticsEnv'. env.step()could not takeactionwith NumPy types.
I continued to make this mistake later in the week, so I decided to create a Agent.sanity_check() function that is run before Agent.test() or Agent.submit().
def sanity_check(self):
"""
Check if the agent's actions are legal.
"""
observation = [0] * 158
action = self.act(observation)
if type(action) is not list:
return (True, 'Action should be a list: are you using NumPy?')
if not is_jsonable(action):
return (True, 'Action should be jsonable: are you using NumPy?')
return (False, '')
Baselines
After I finished creating the basic Agent class, I decided to create a few baseline agents. First, I created a RandomAgent that always chooses a random action. This is same as the example given in osim-rl repository.
class RandomAgent(Agent):
def __init__(self, env):
self.env = env
def act(self, observation):
return self.env.action_space.sample().tolist()
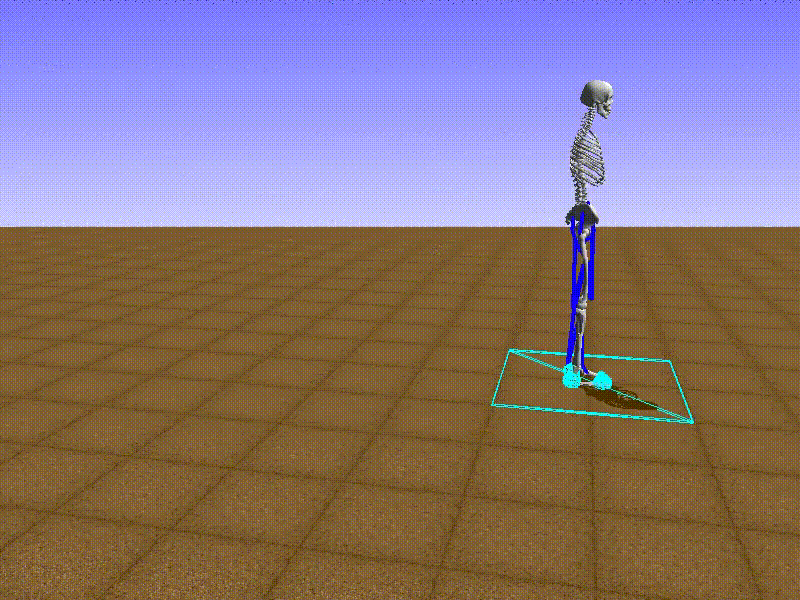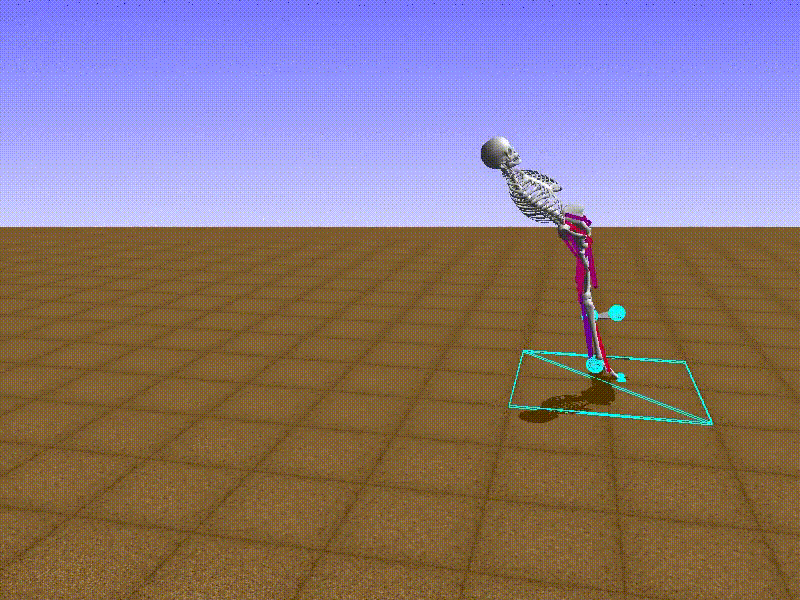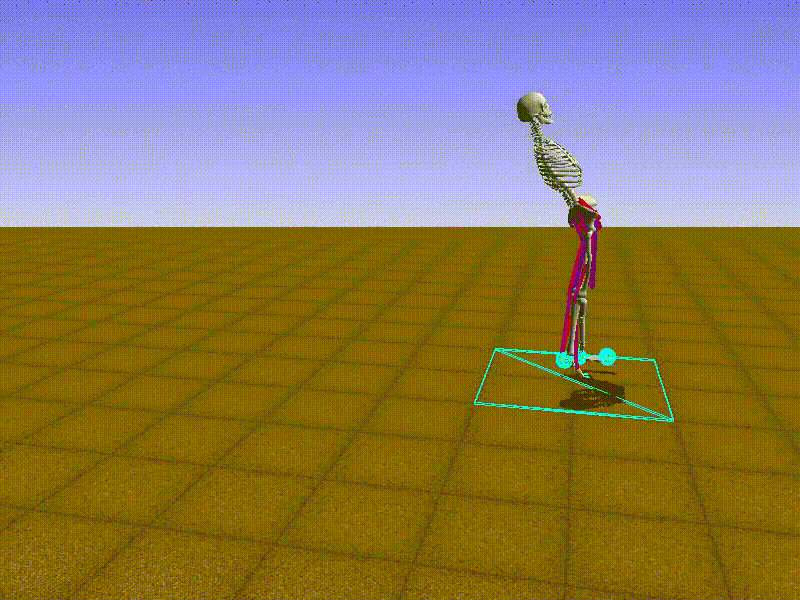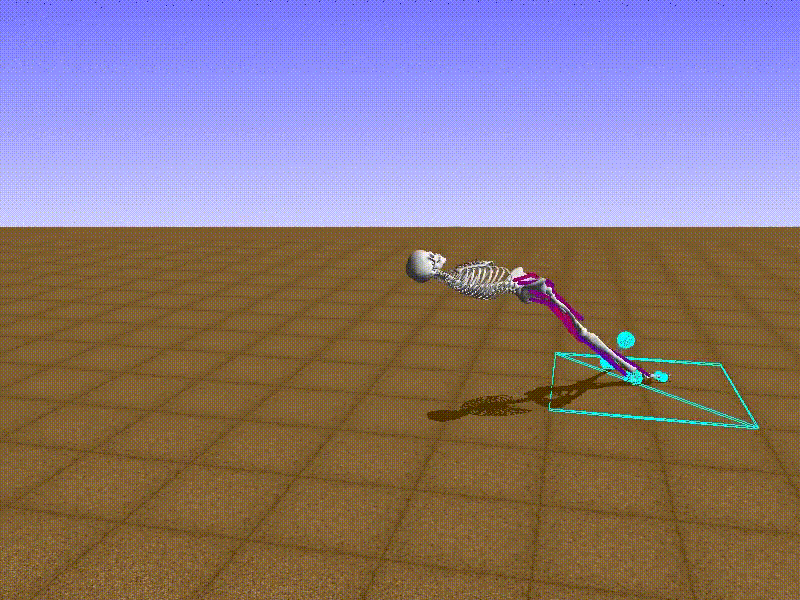
I also created a FixedActionAgent that always chooses the same action.
class FixedActionAgent(Agent):
"""
An agent that choose one fixed action at every timestep.
"""
def __init__(self, env):
self.action = [0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0]
def act(self, observation):
return self.action
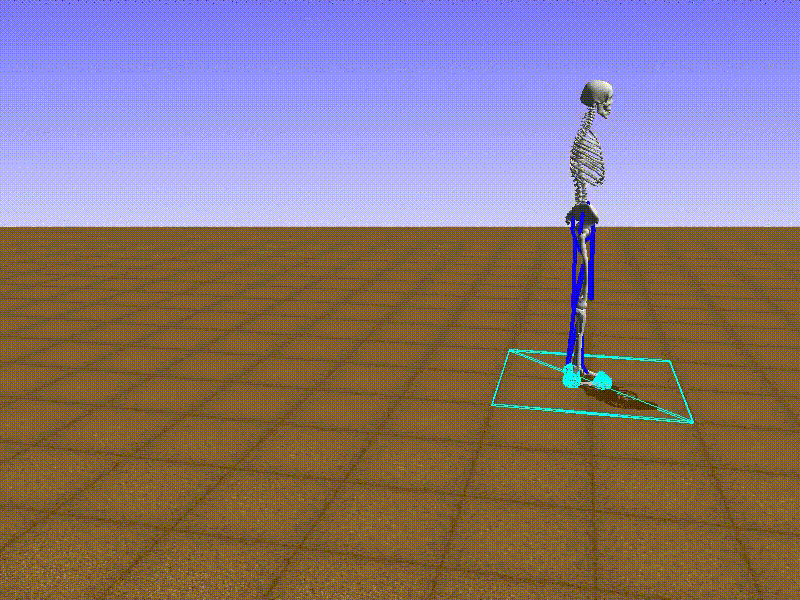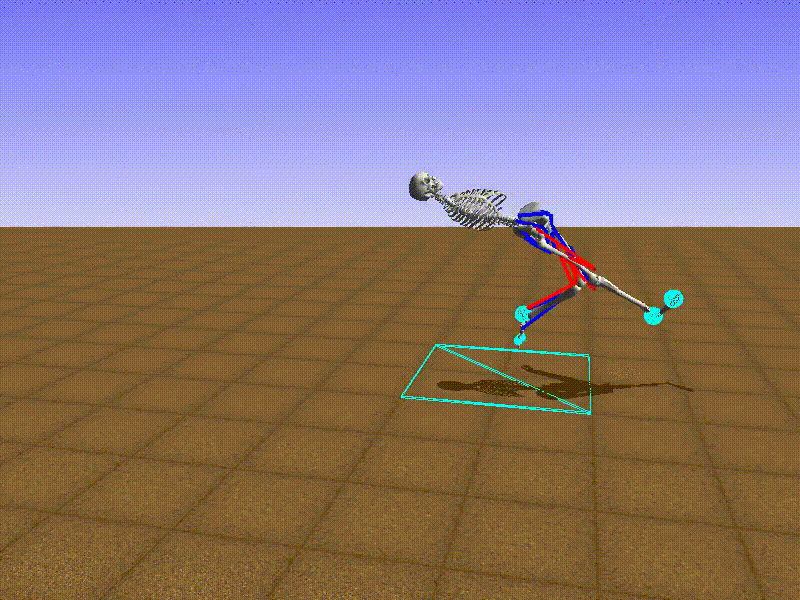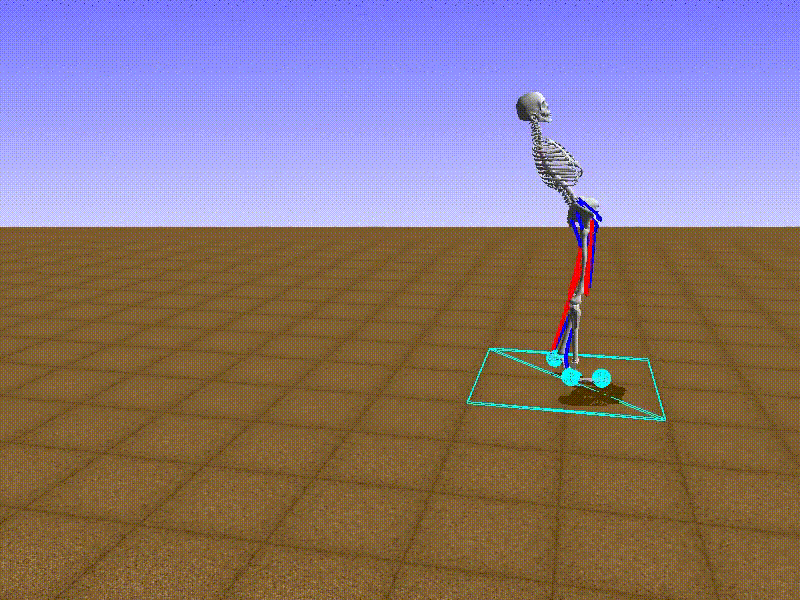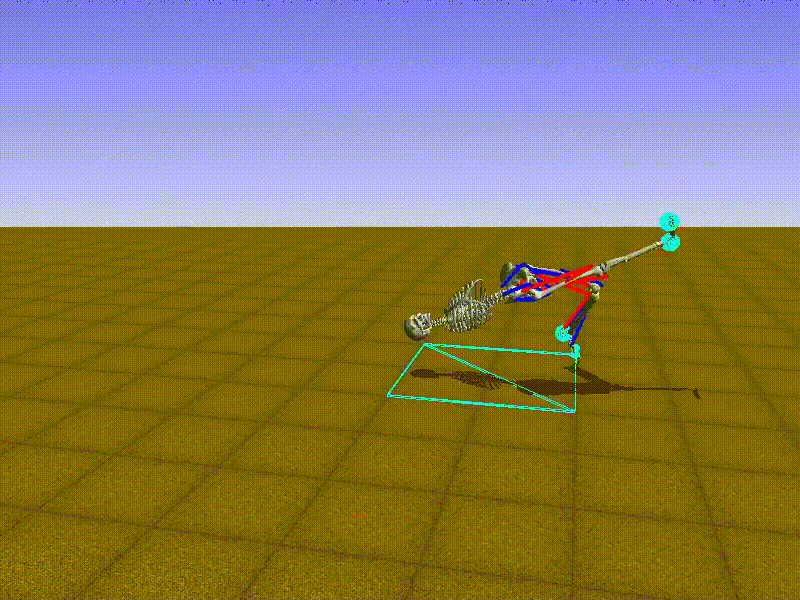
Local Visualization
You can test the agent locally using the run.py script.
./run.py FixedActionAgent
To visualize the agent, use the -v/--visualize tag.
./run.py FixedActionAgent -v
Submission
You can also submit with osim-rl-helper using the run.py script. First, open the helper/CONFIG.py file and add your crowdAI API token. You can find your API token in https://www.crowdai.org/participants/[username].
remote_base = 'http://grader.crowdai.org:1729'
crowdai_token = ''
Then, you can submit the FixedActionAgent by adding the -s/--submit flag:
./run.py RandomAgent -s
I will regularly upload more agents and helpful scripts throughout the competition, so if you’re interested, please watch or star the repository on GitHub!
What’s Next?
Neither RandomAgent nor FixedActionAgent is a reinforcement learning agent: it chooses an action regardless of the observation it receives. I will try to implement a basic learning agent that uses the observation provided by the environment.
Also, although we can simply plug the observations into some Policy Gradient algorithm and train it, it is very likely that knowing more about the observation and the actions could allow us to perform feature engineering. Thus, we will also explore the two spaces deeper in the next few weeks.