Weeks
- Week 1: Understanding the Challenge
- Week 2: Understanding the Action Space
- Week 3 - 4: Understanding the Observation Space
- Week 5: Understanding the Reward
- Week 6 - 8: General Techniques of RL
- Week 9 - 10: Unorthodox Approaches
Muscles
Last week, we saw how a valid action has 19 numbers, each between 0 and 1. The 19 numbers represented the amount of force to put to each muscle. I know barely anything about muscles, so I decided to manually go through all the muscles to gain some intuition about the effects of each muscle.
Index 0
Index 1

Index 2
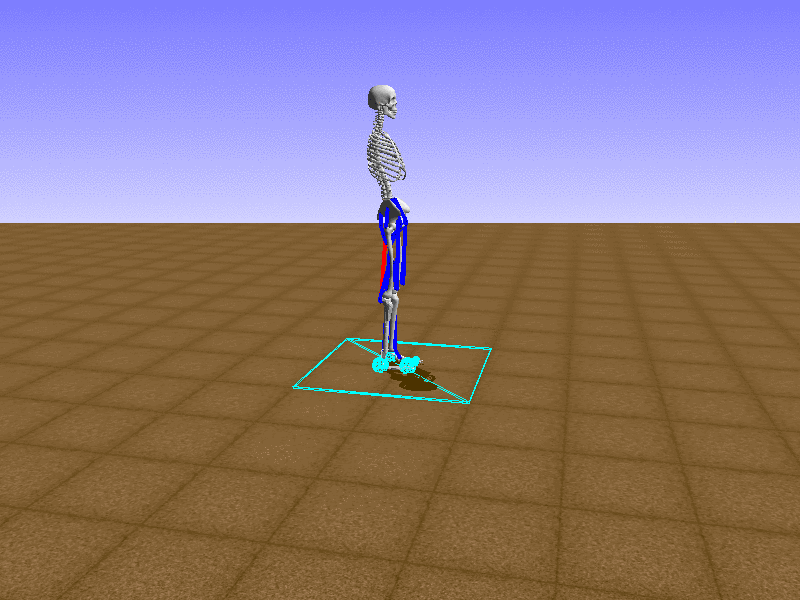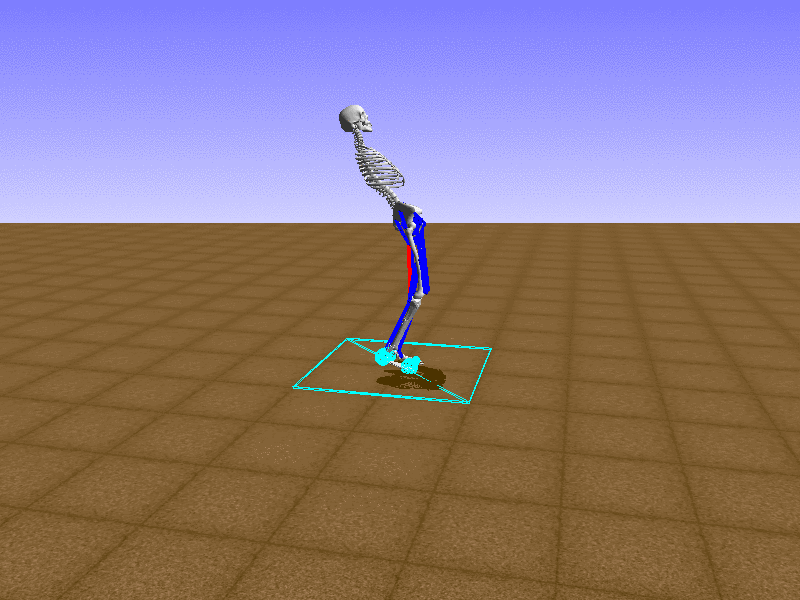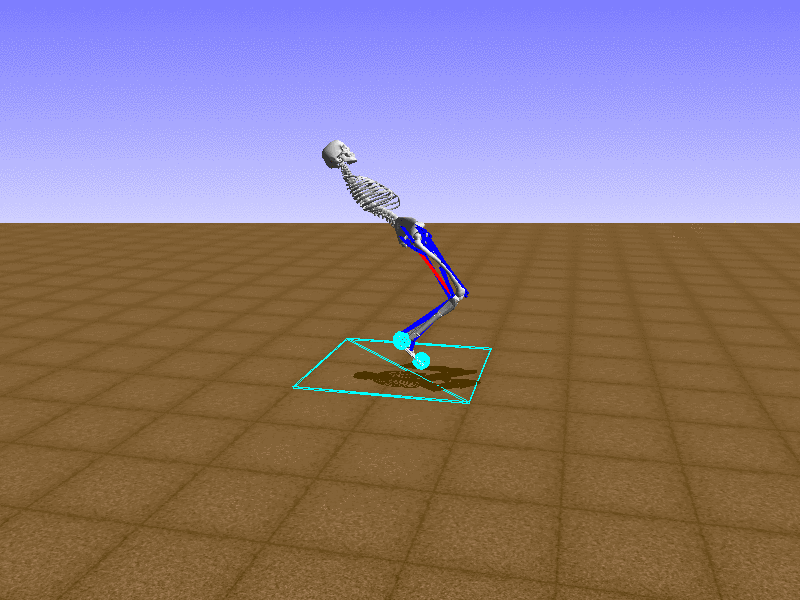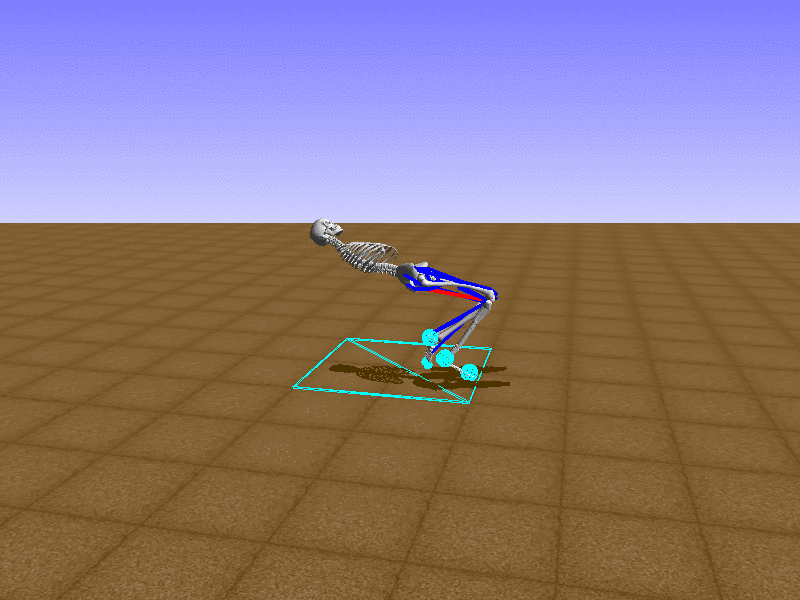
Index 3

Index 4
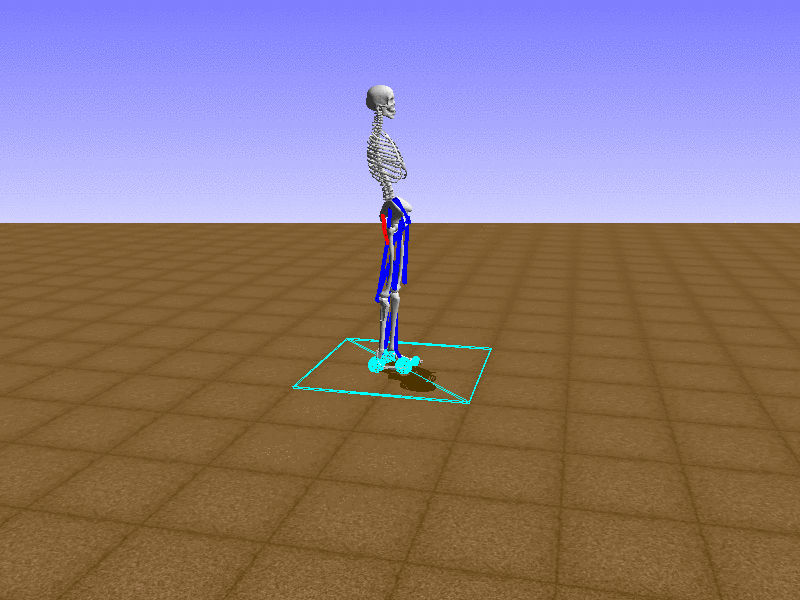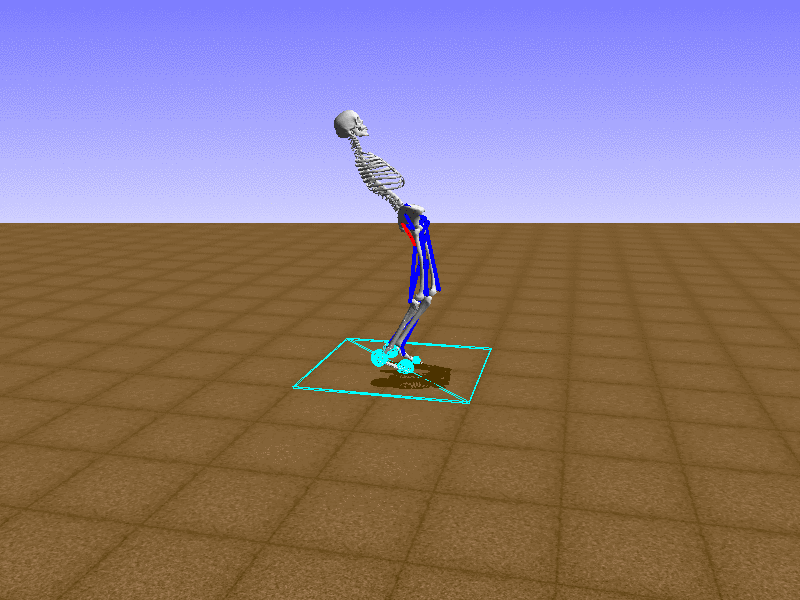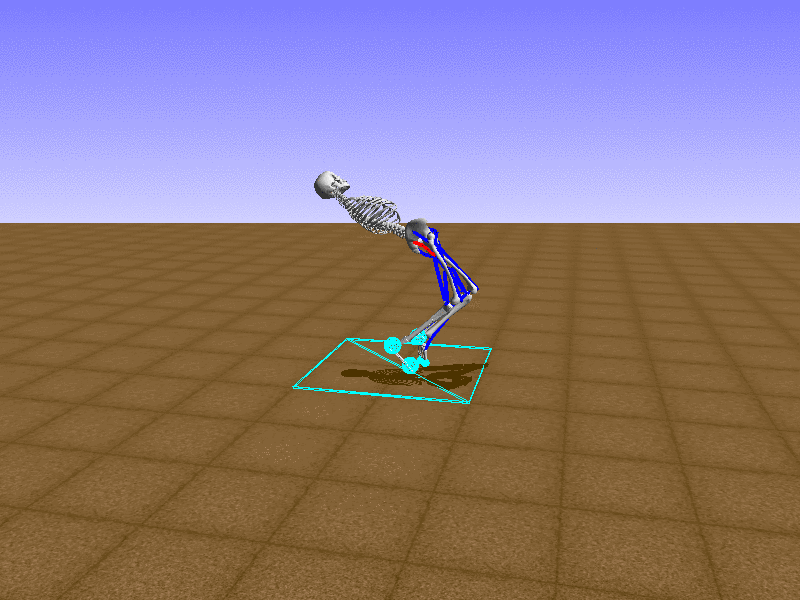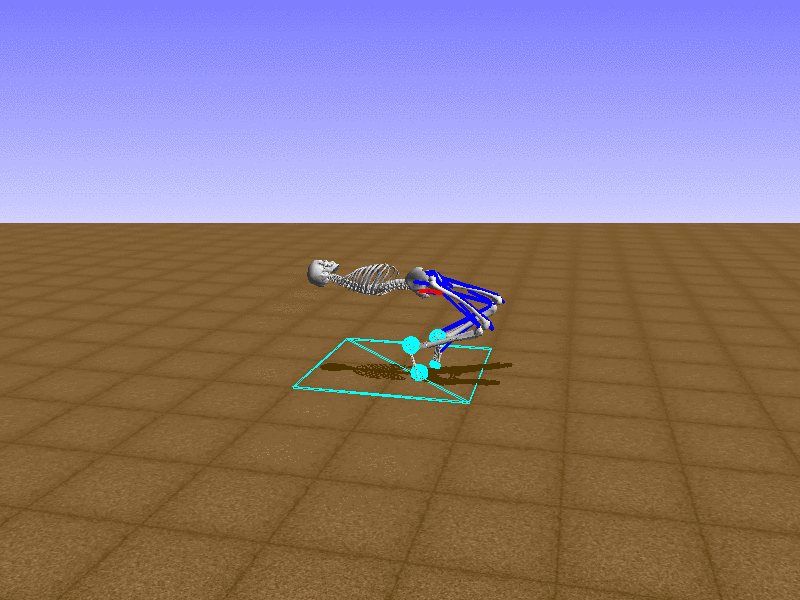
Index 5
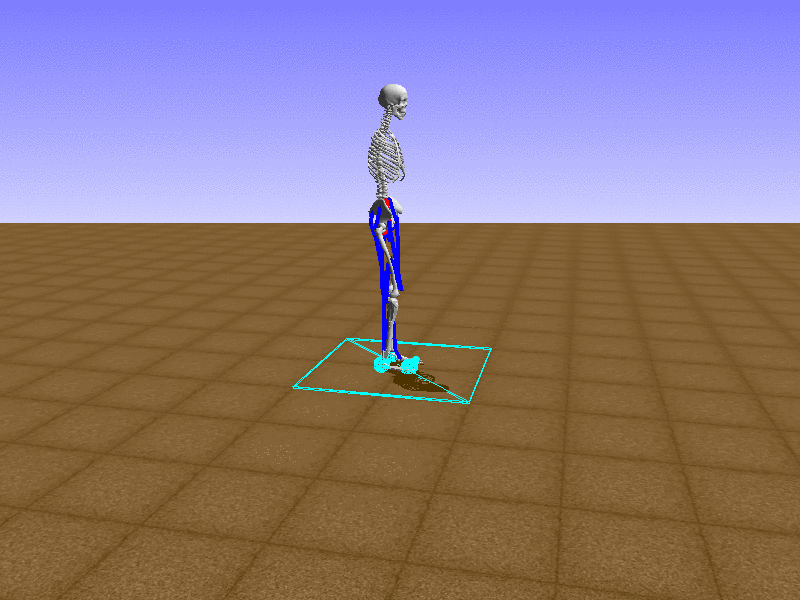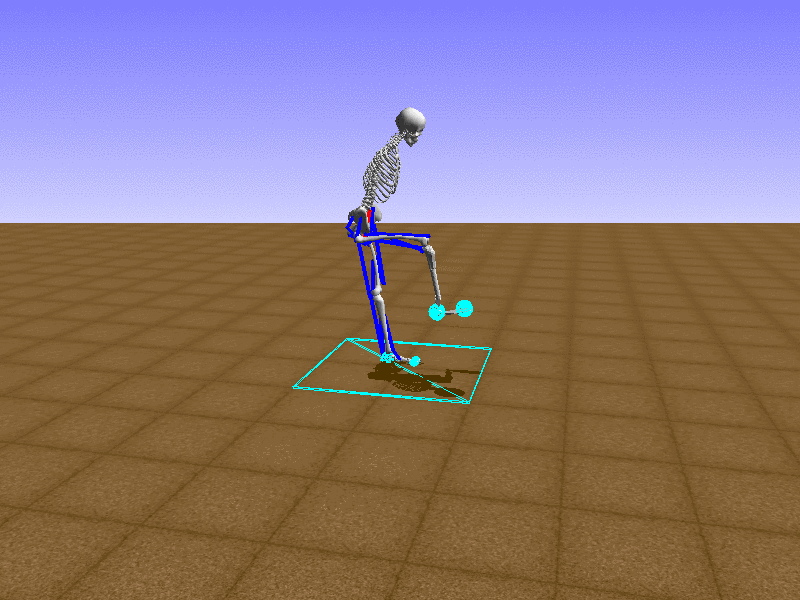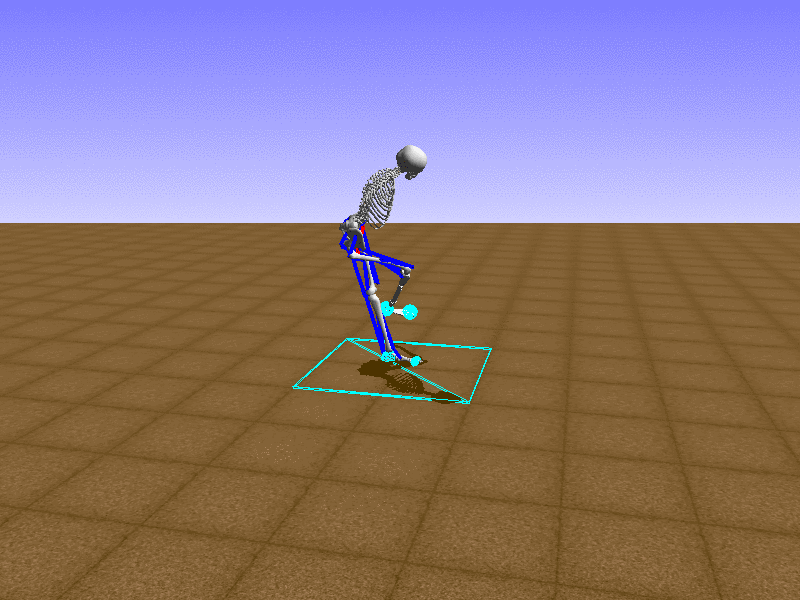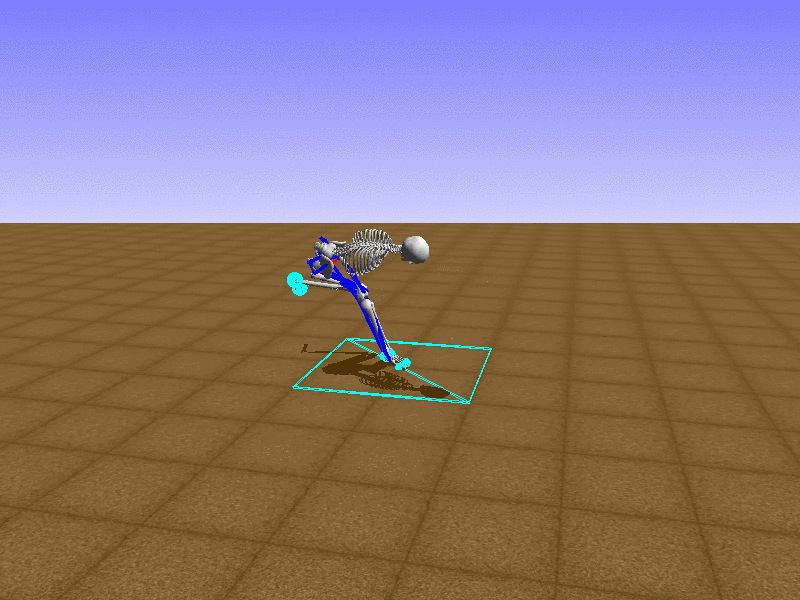
Index 6

Index 7
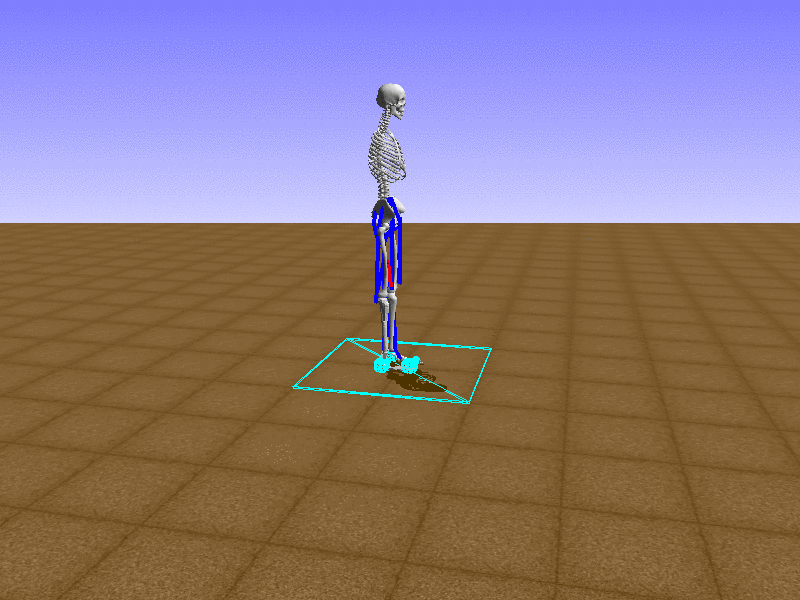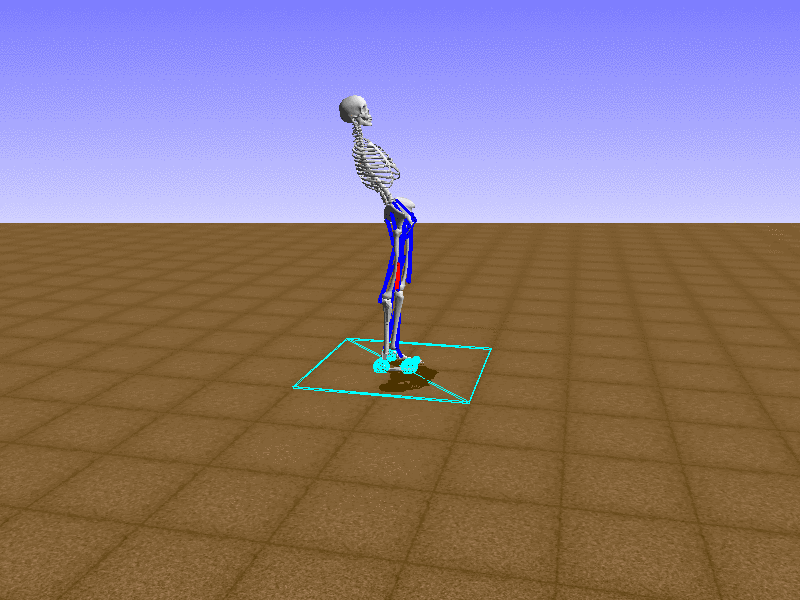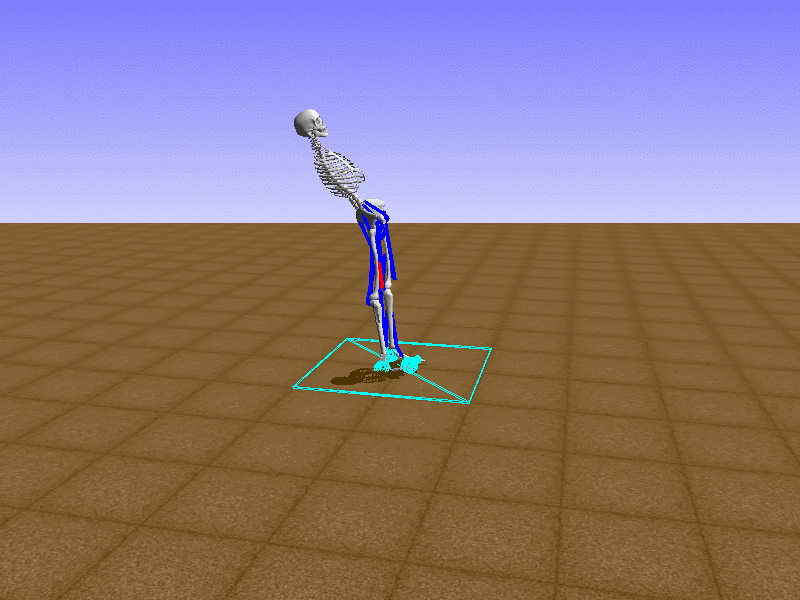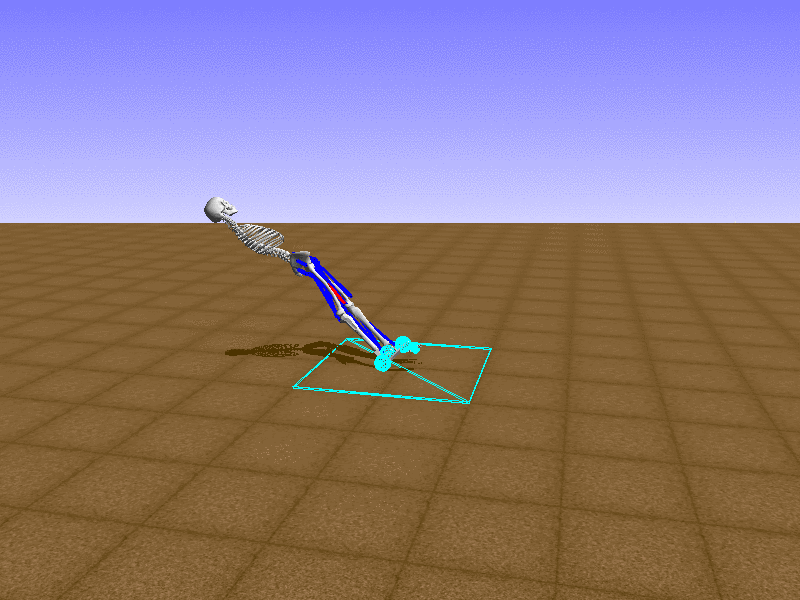
Index 8
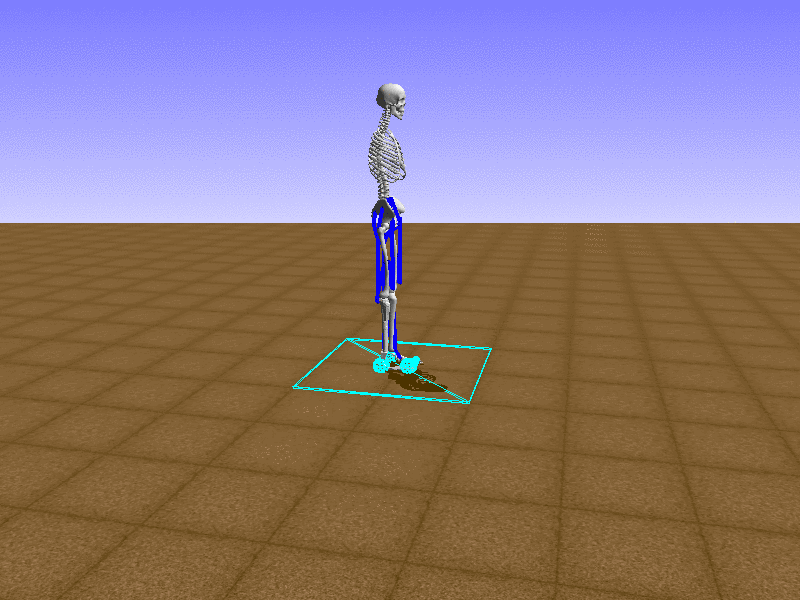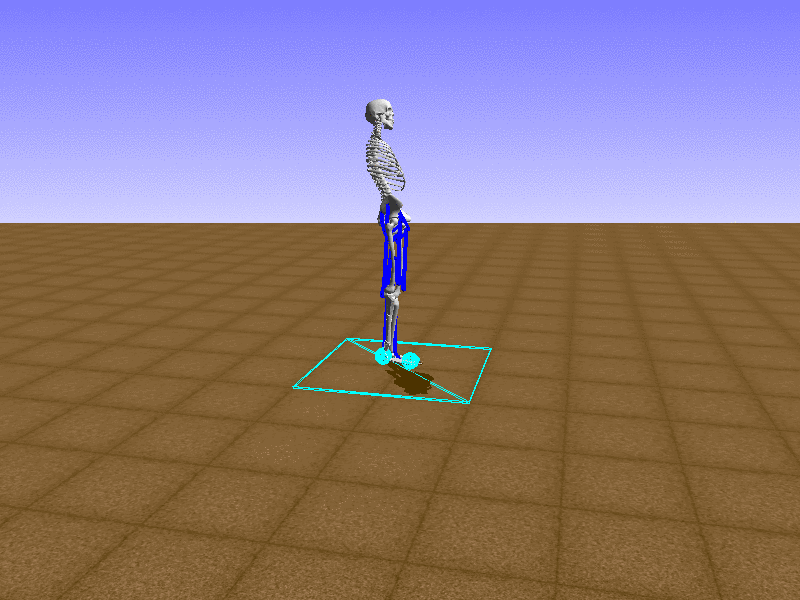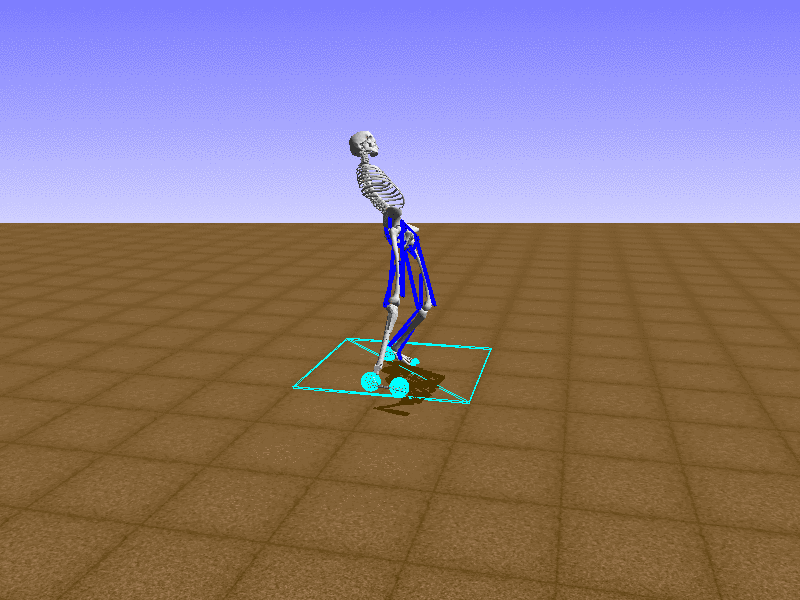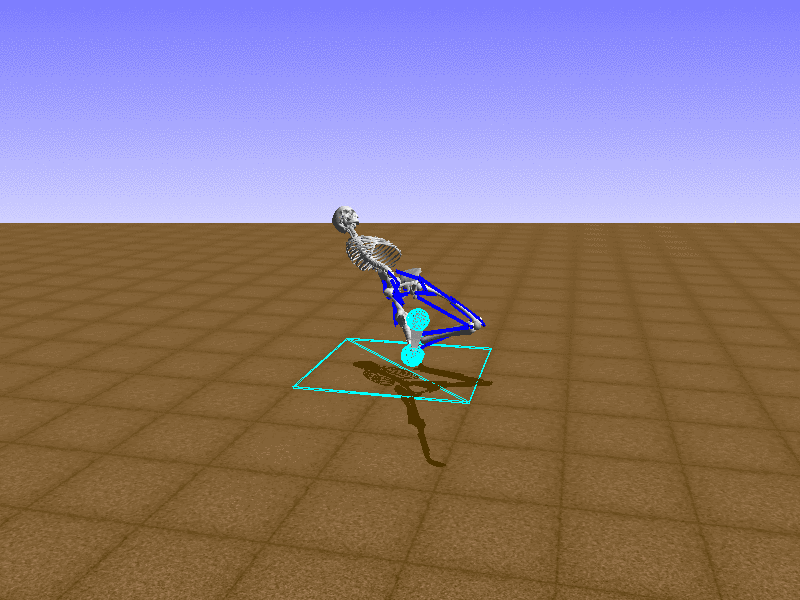
Index 9

Index 10
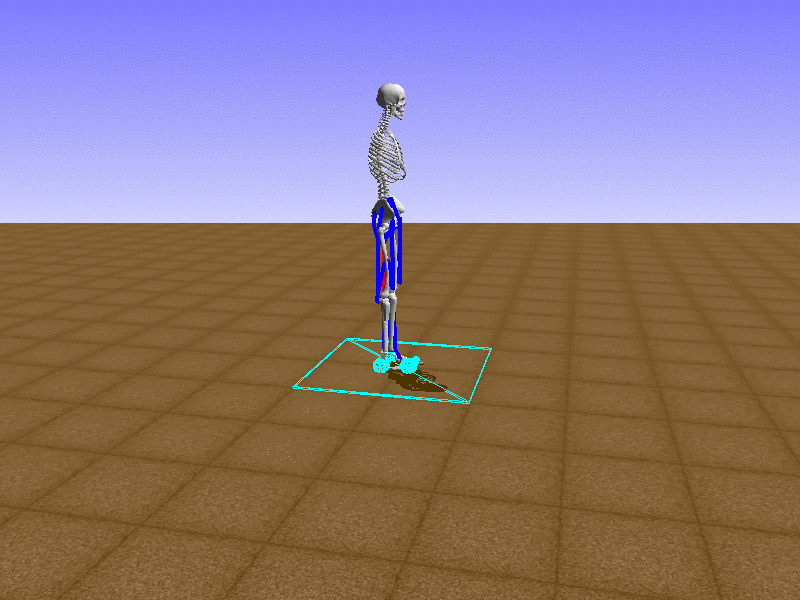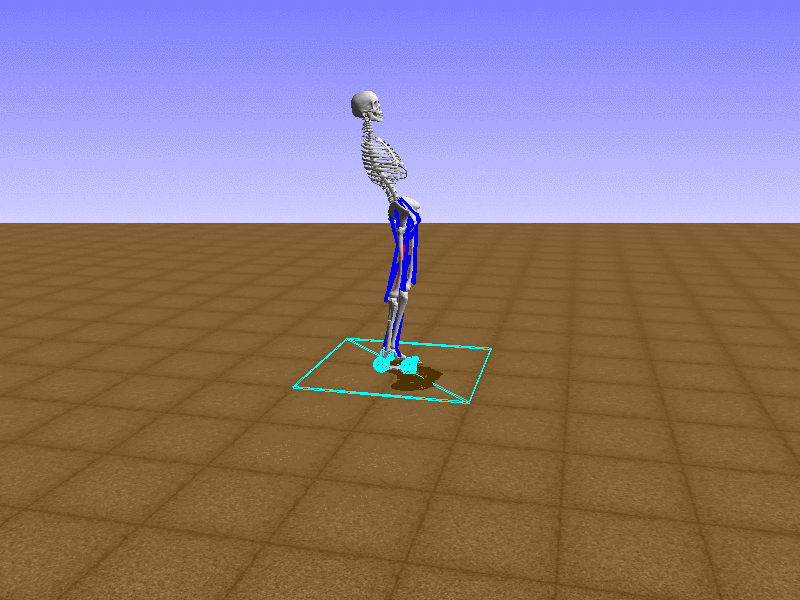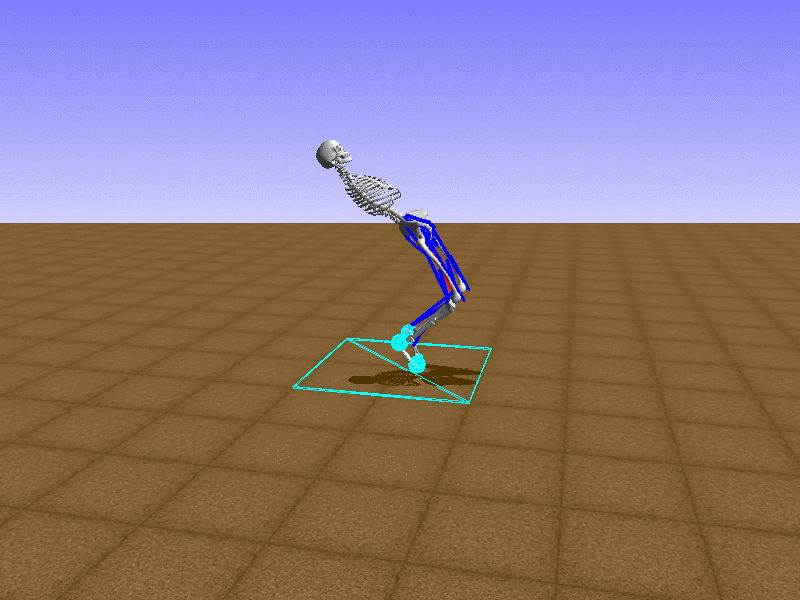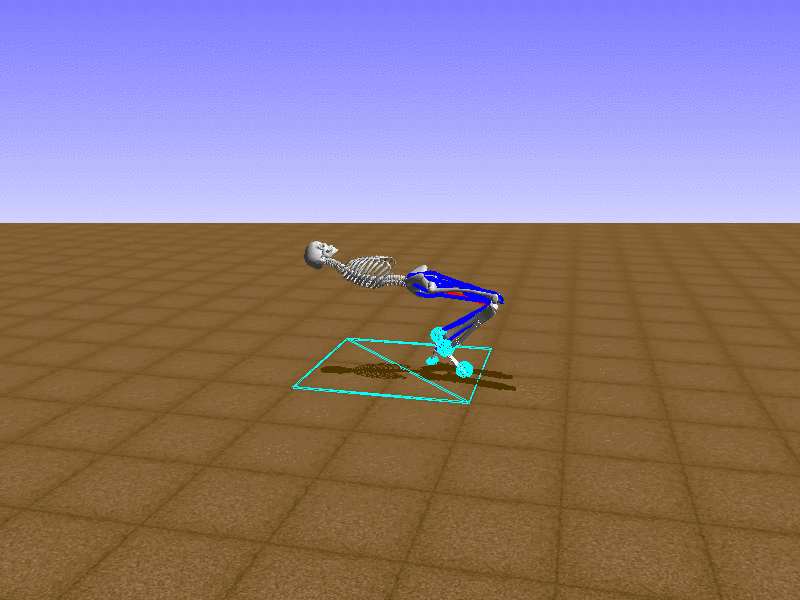
Index 11
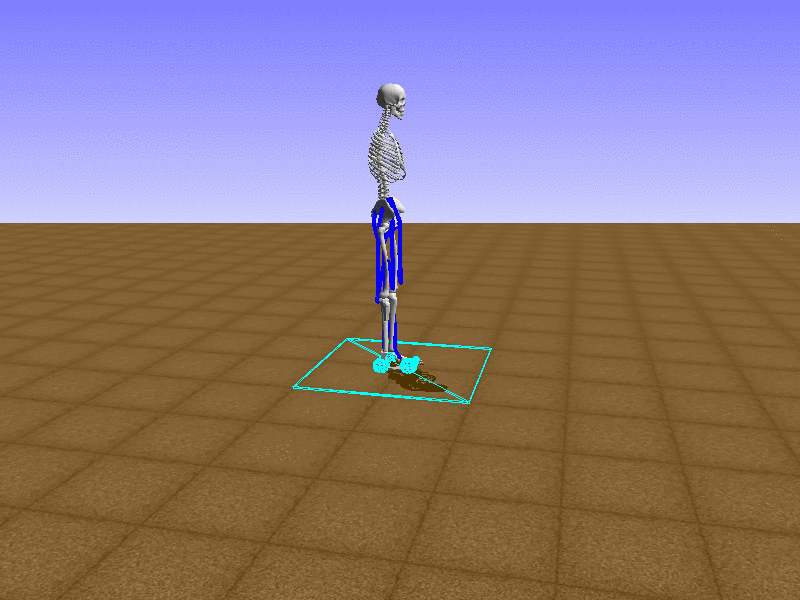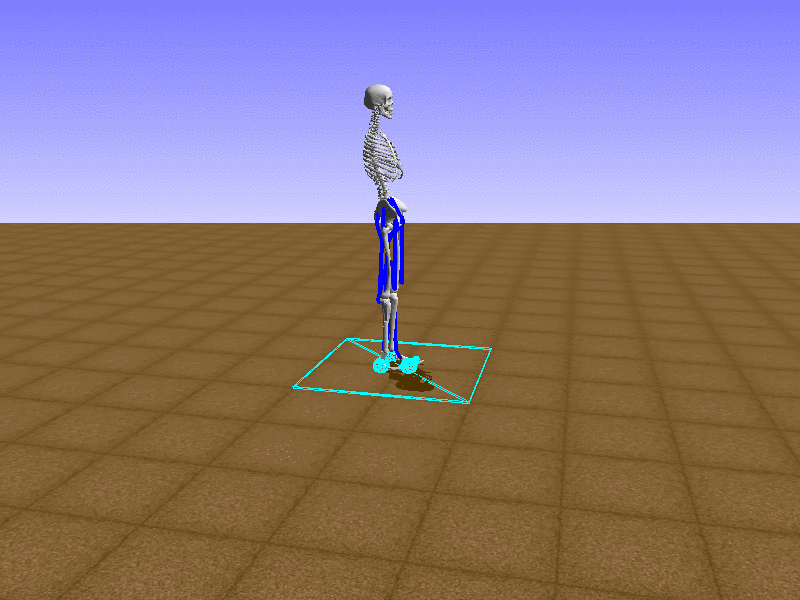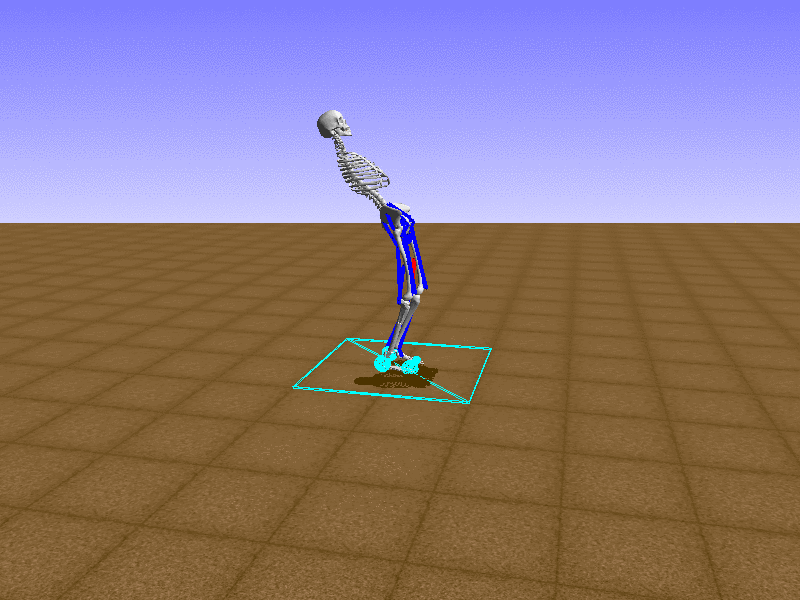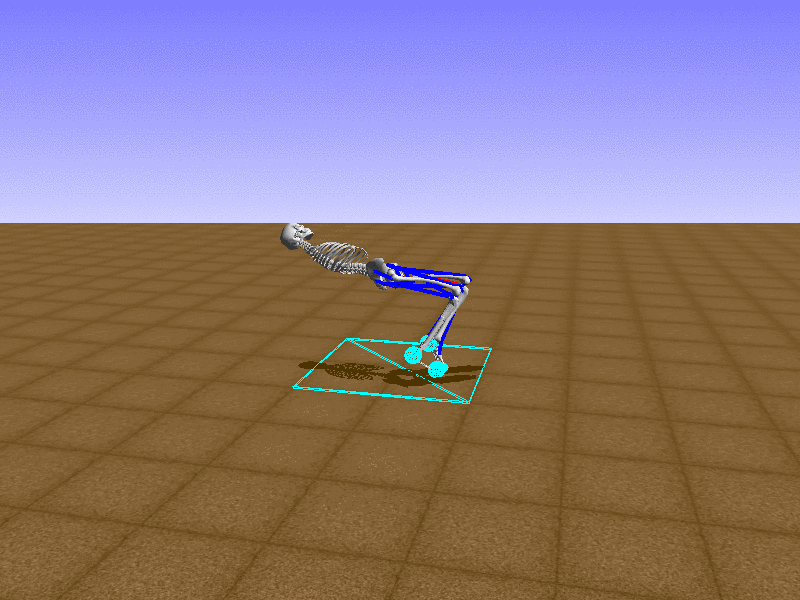
Index 12
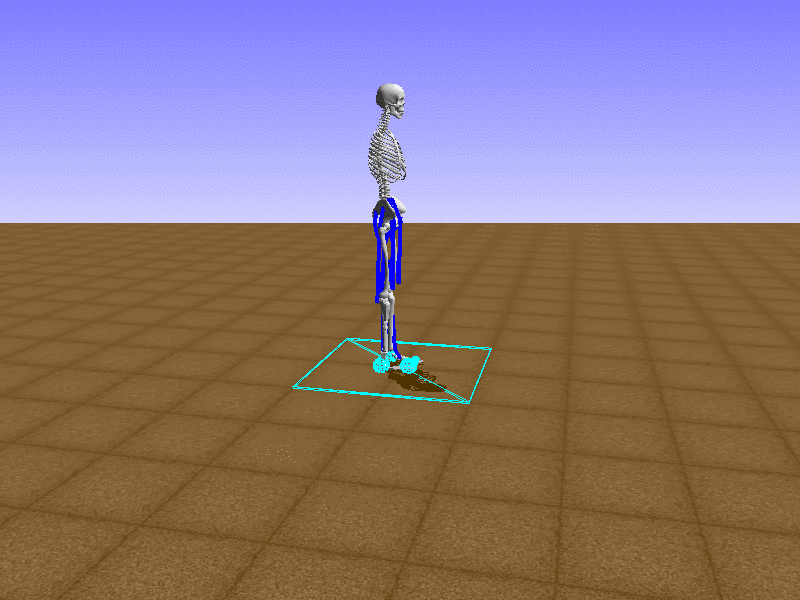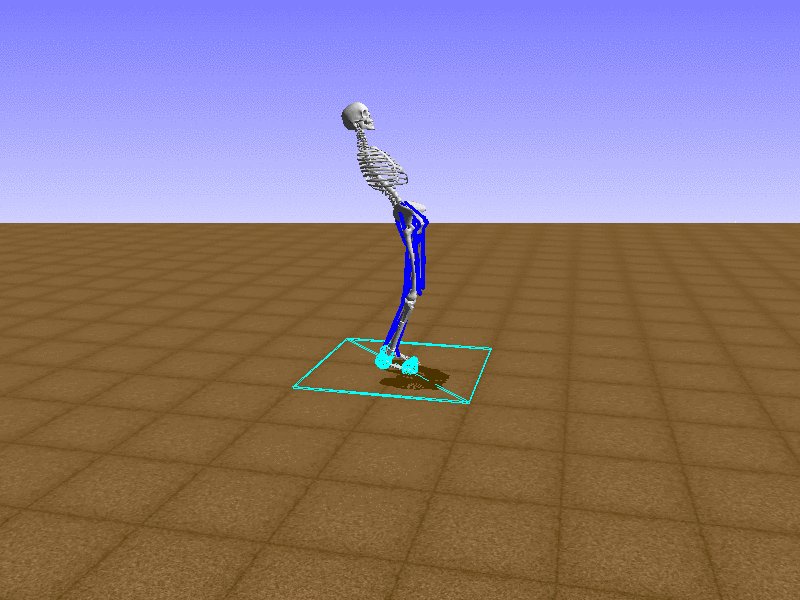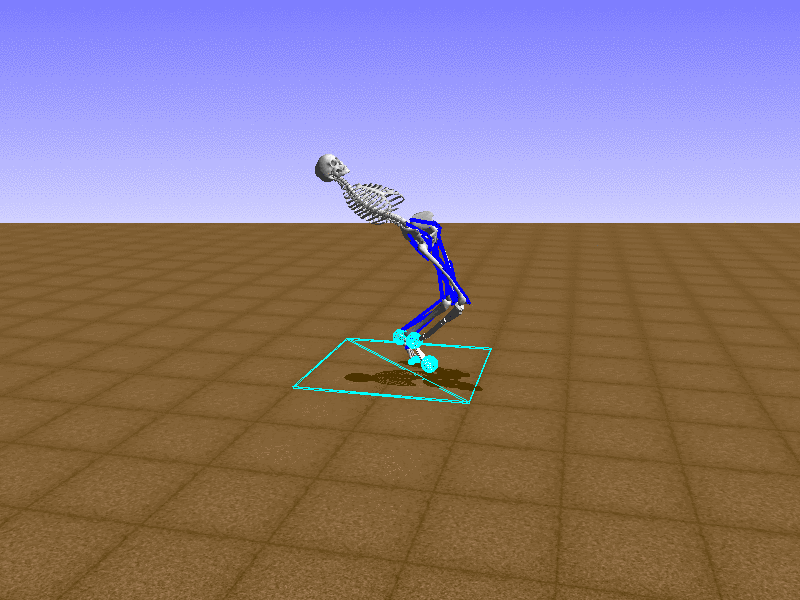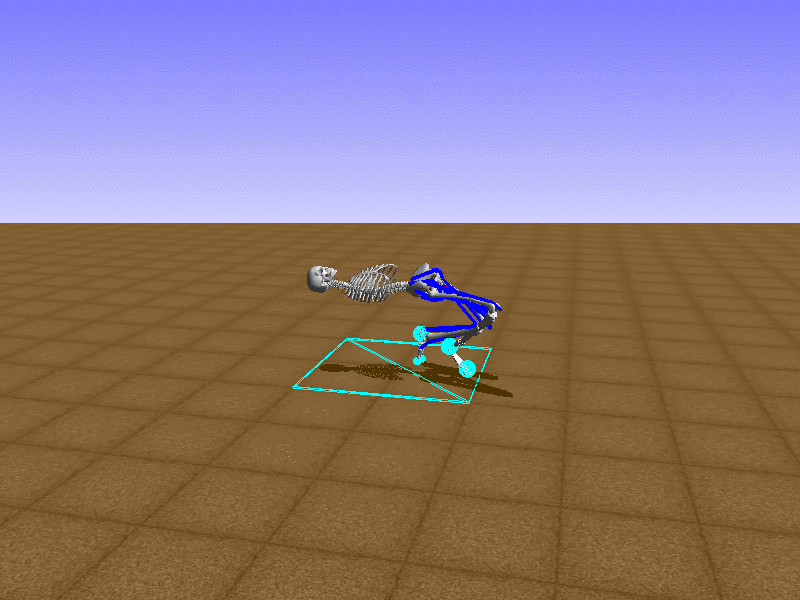
Index 13
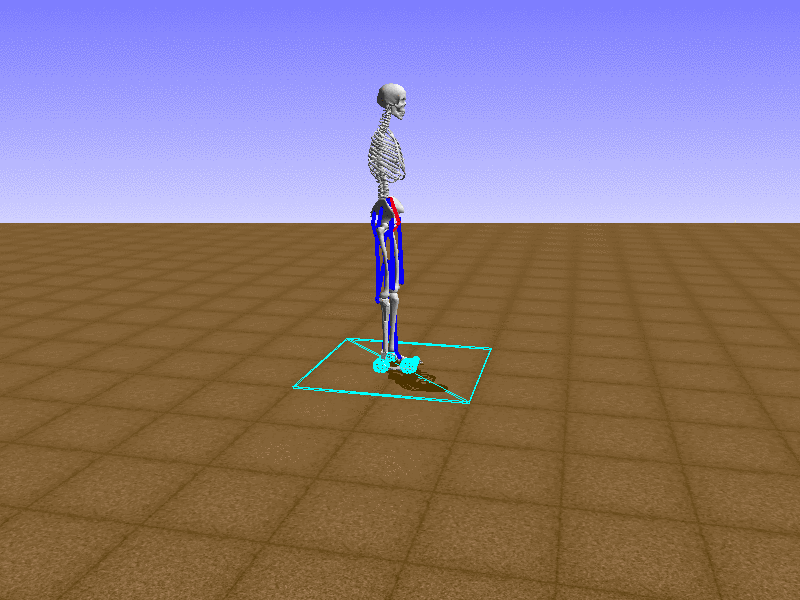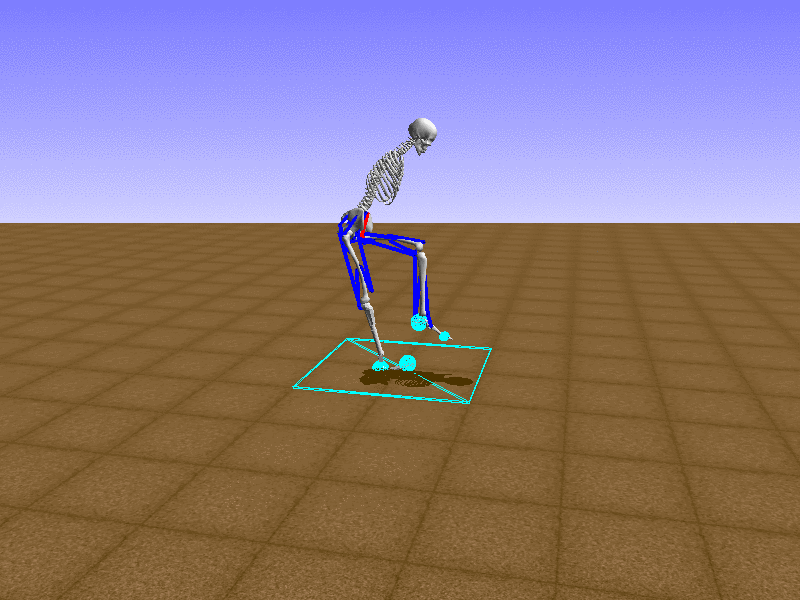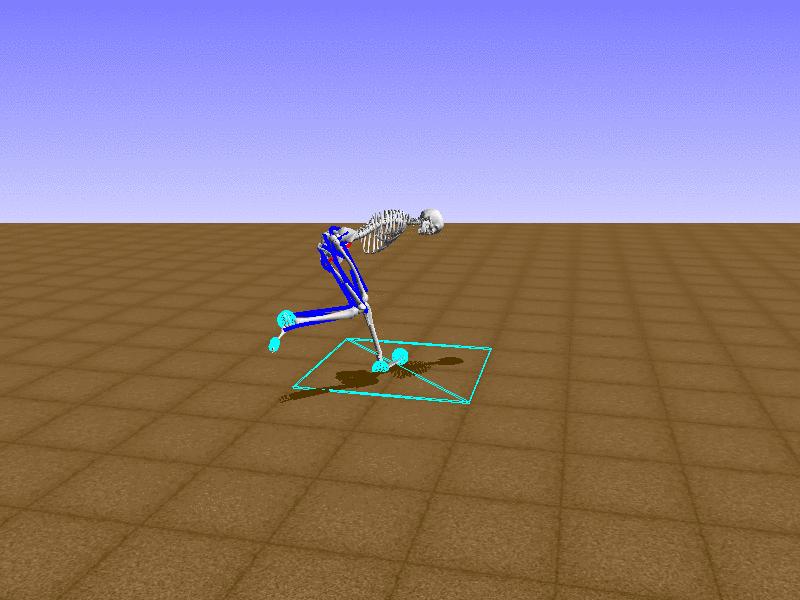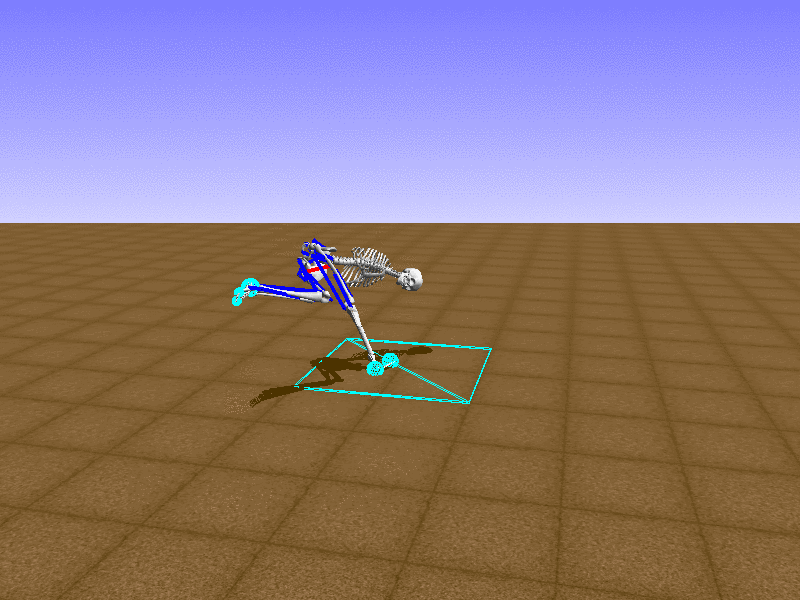
Index 14
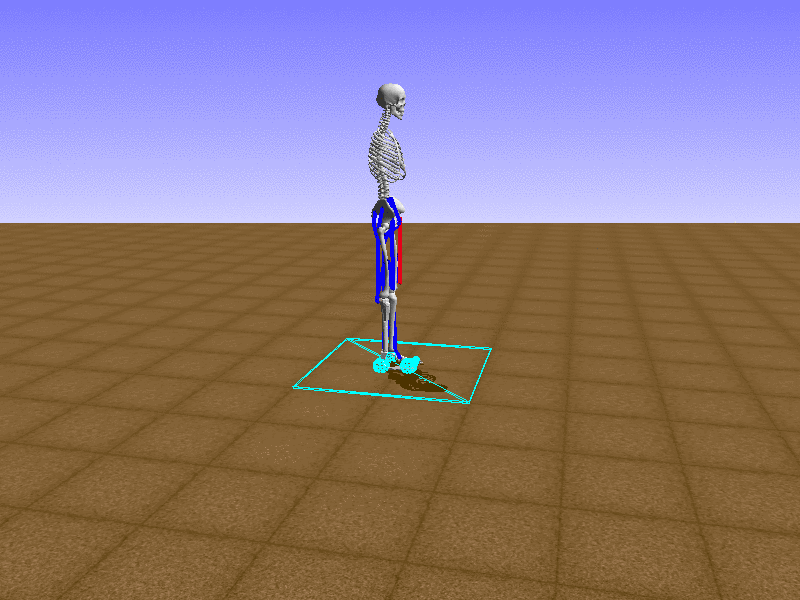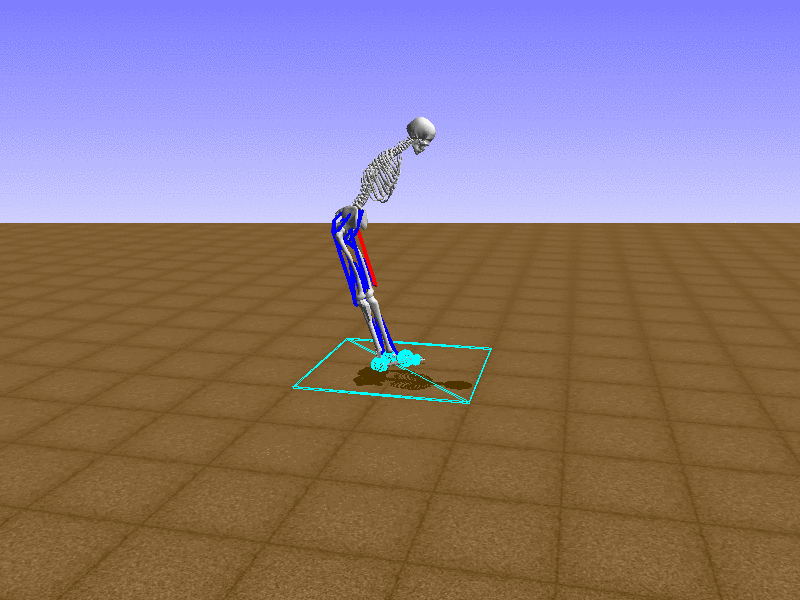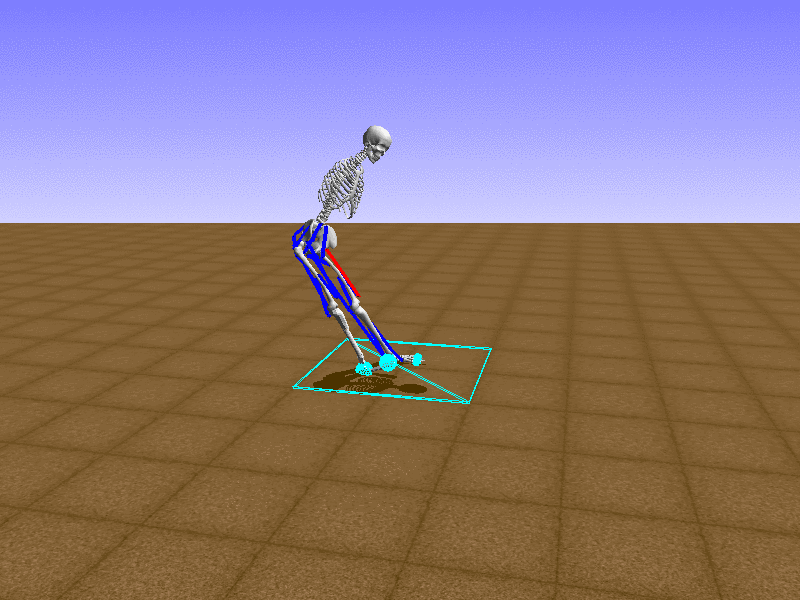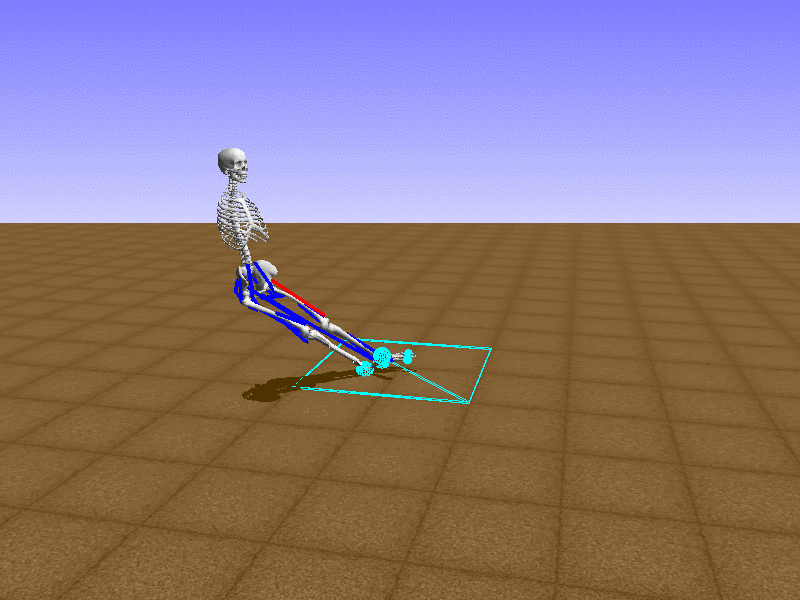
Index 15
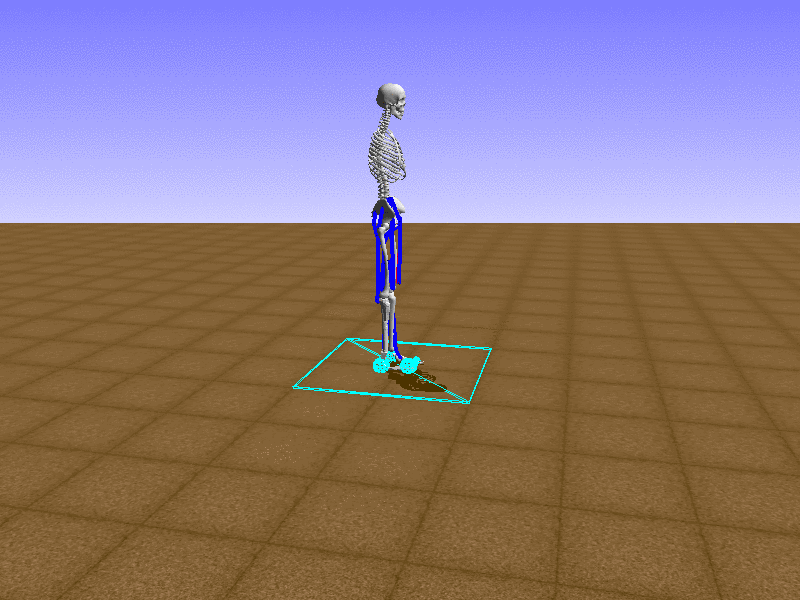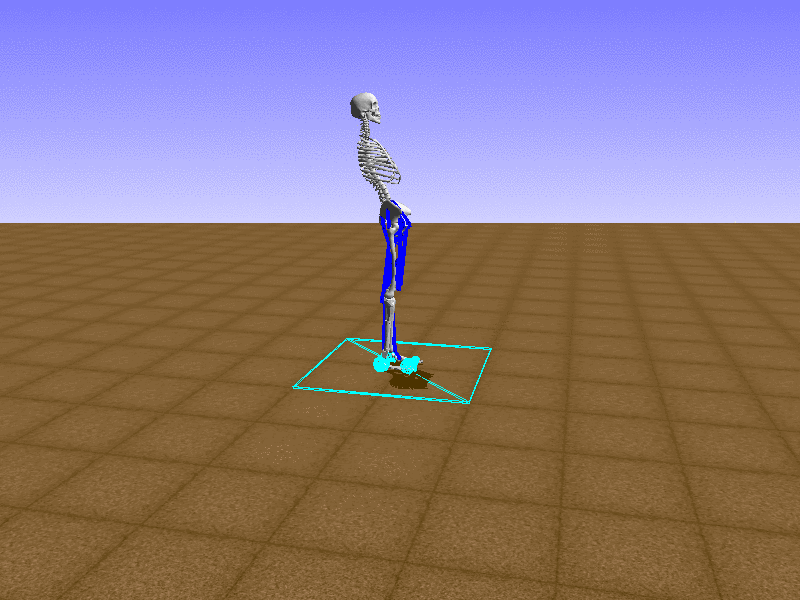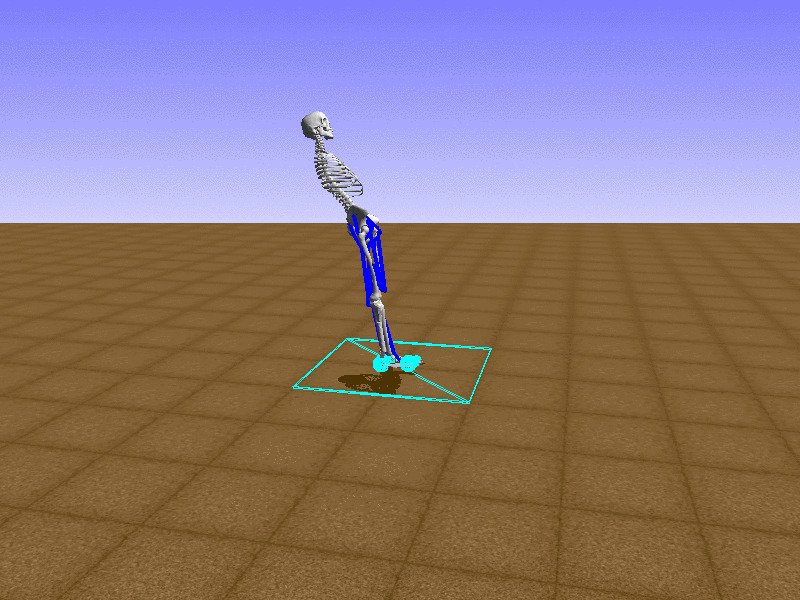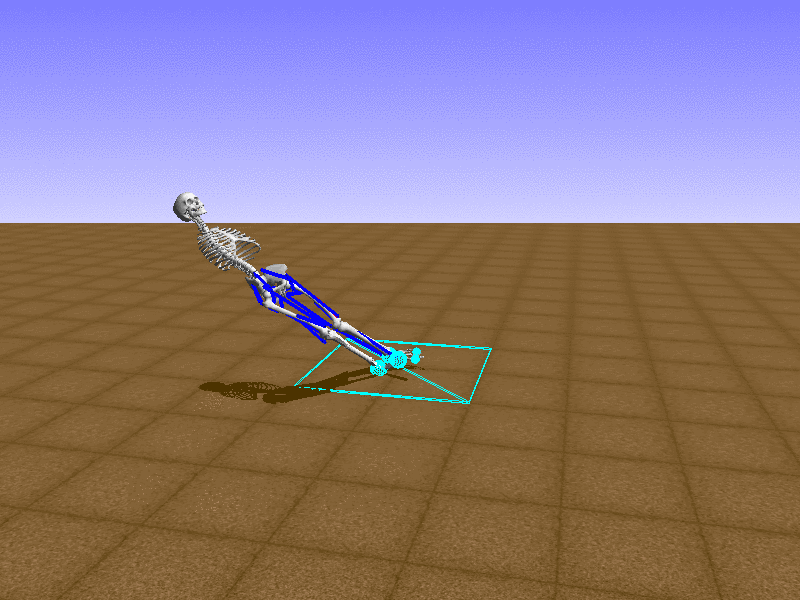
Index 16

Index 17
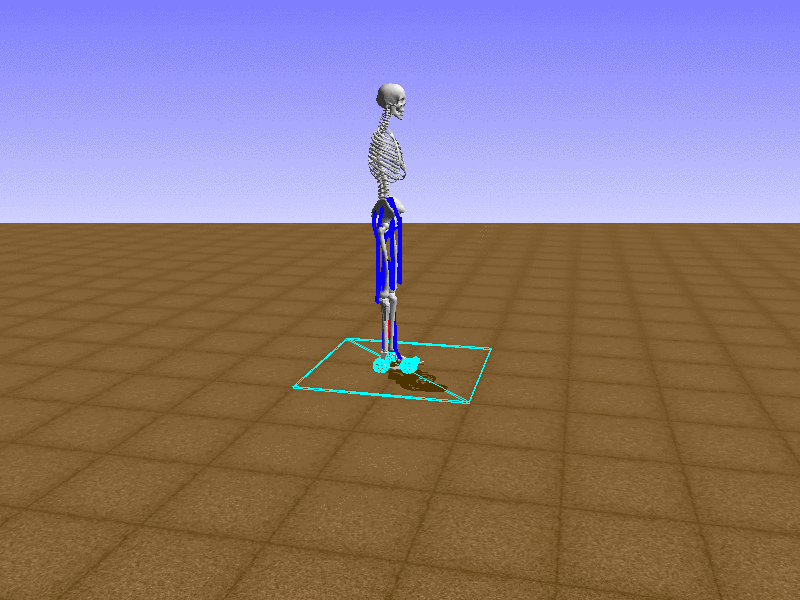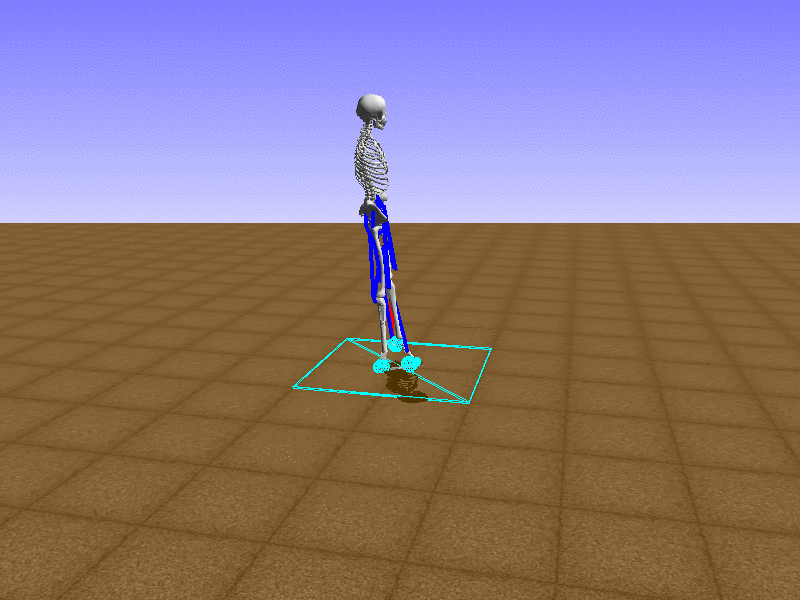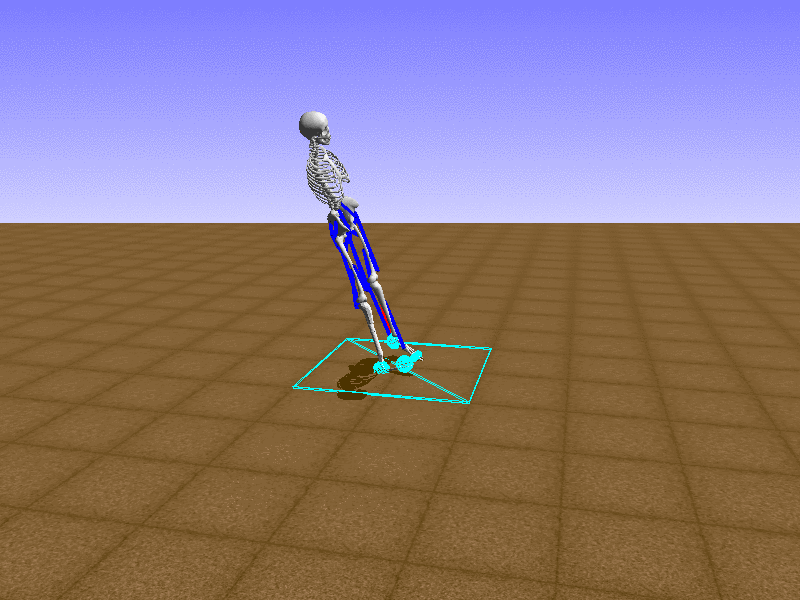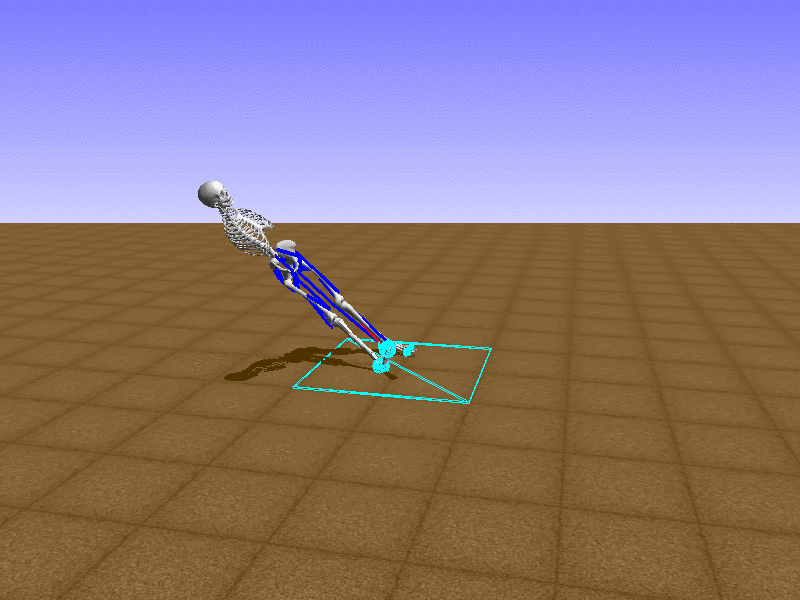
Index 18
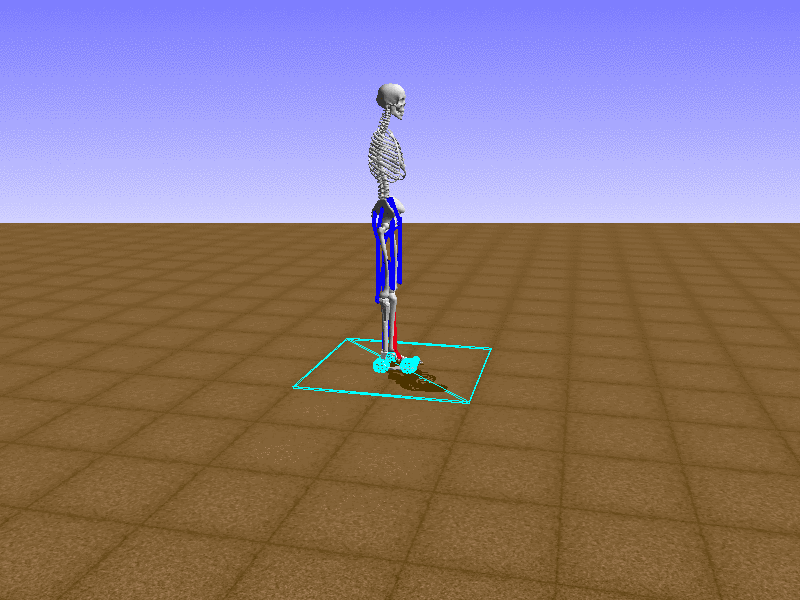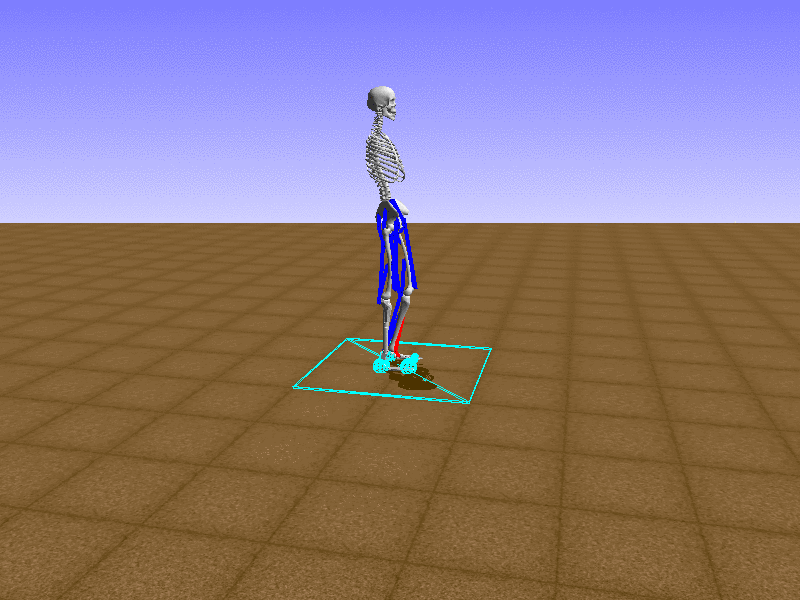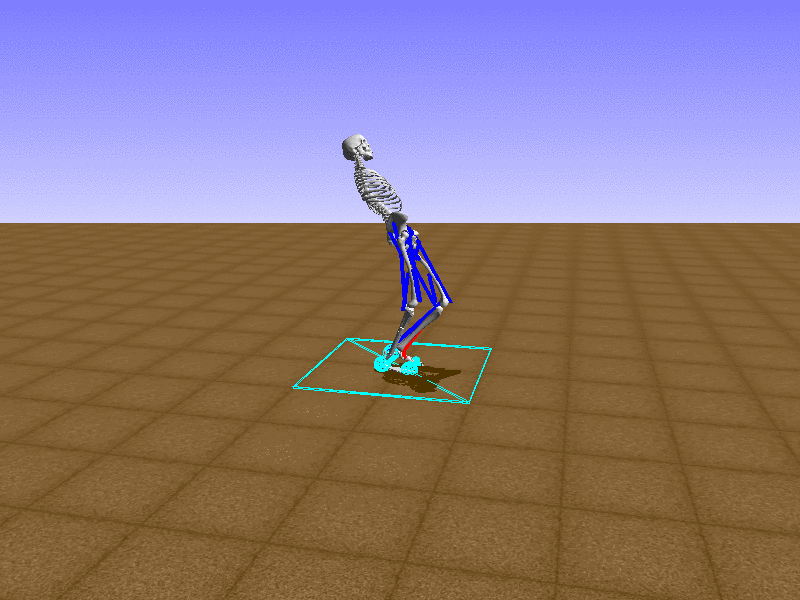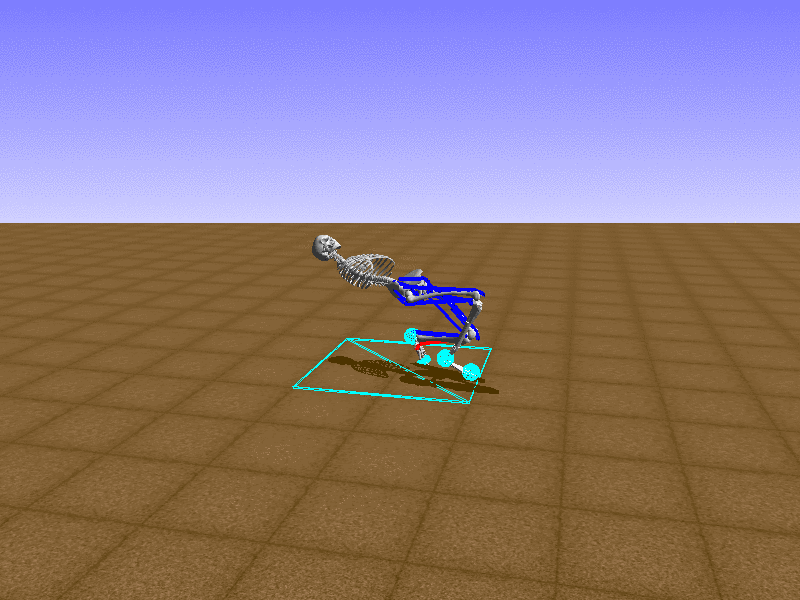
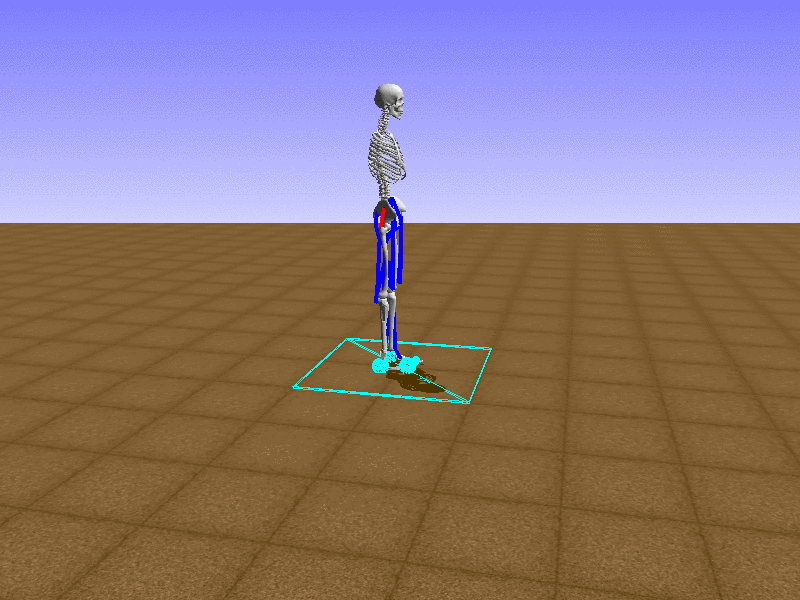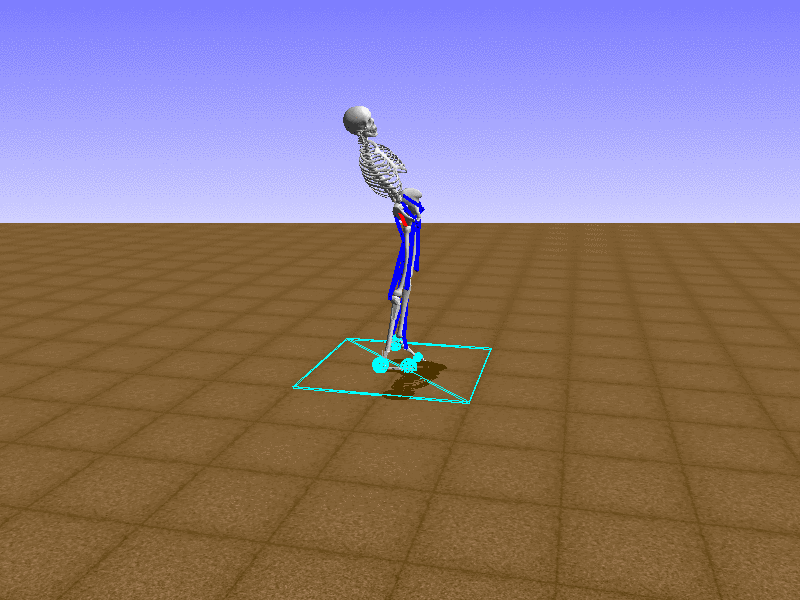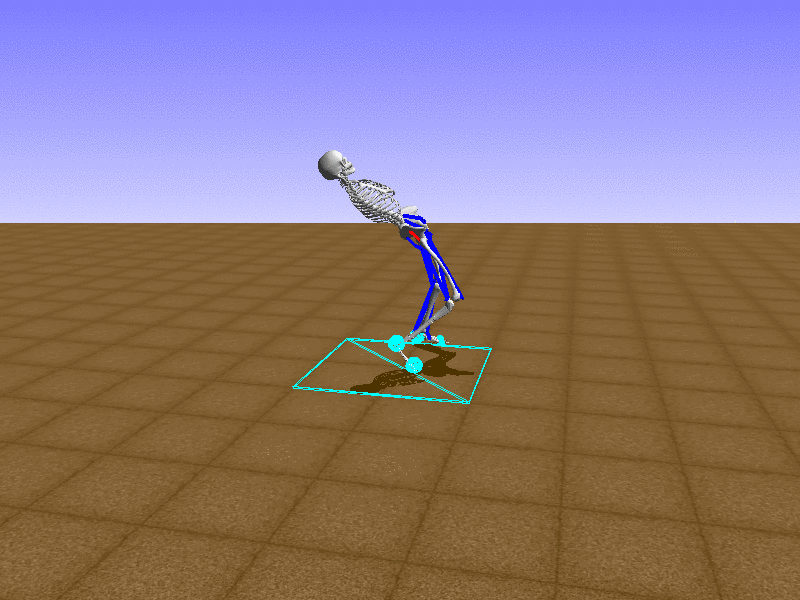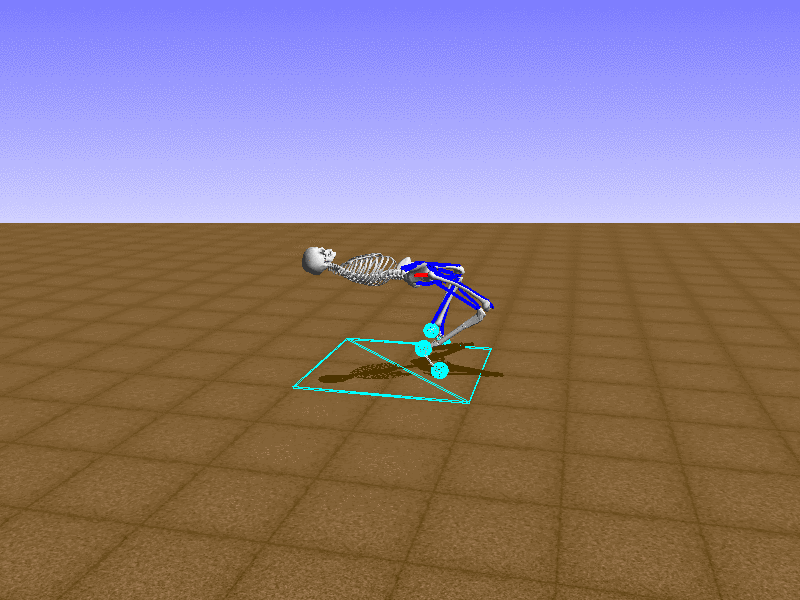
Hip Thrust
Let’s test our intuition by trying to create a “hip-thrust” action. The indices 2, 4, 10, 12 look promising, so let’s try fully activating these muscles, leaving all other muscles unactivated.
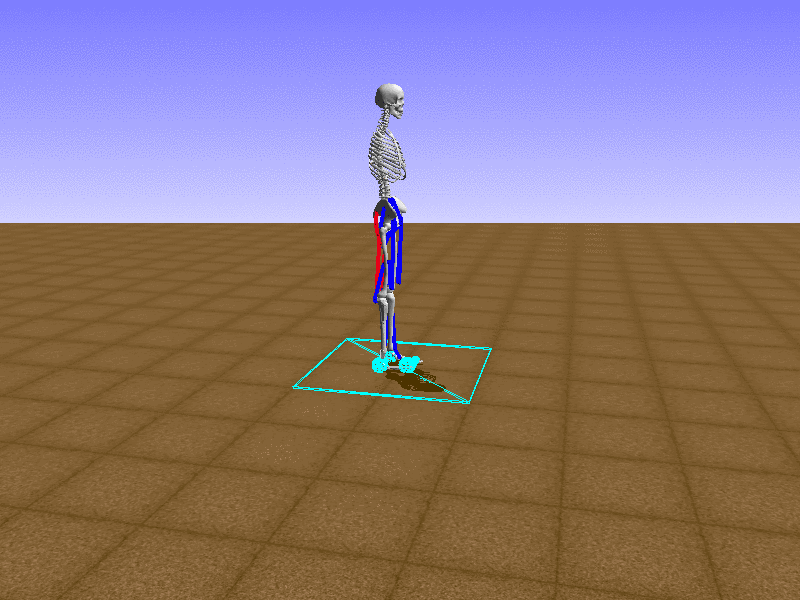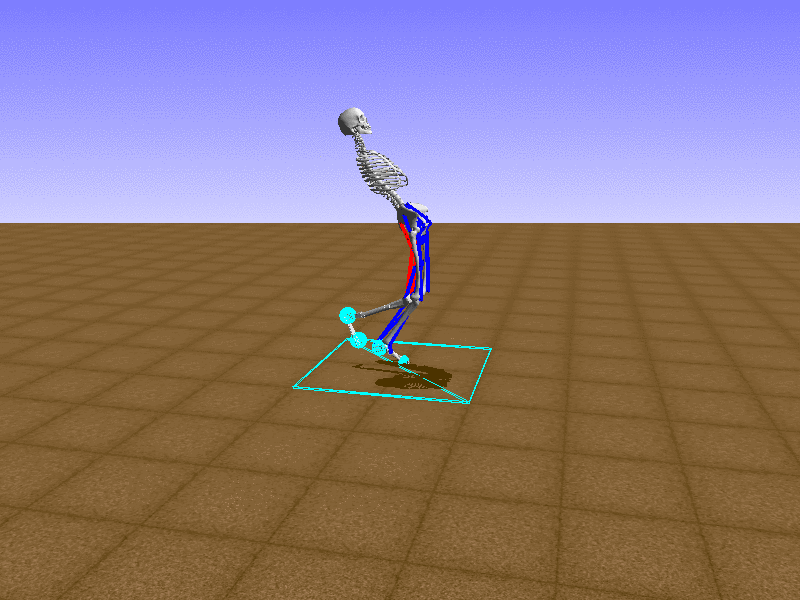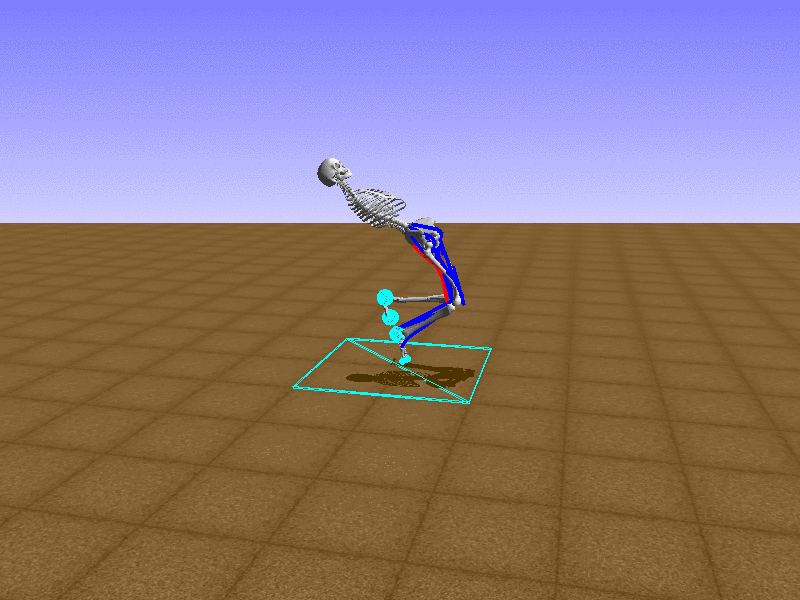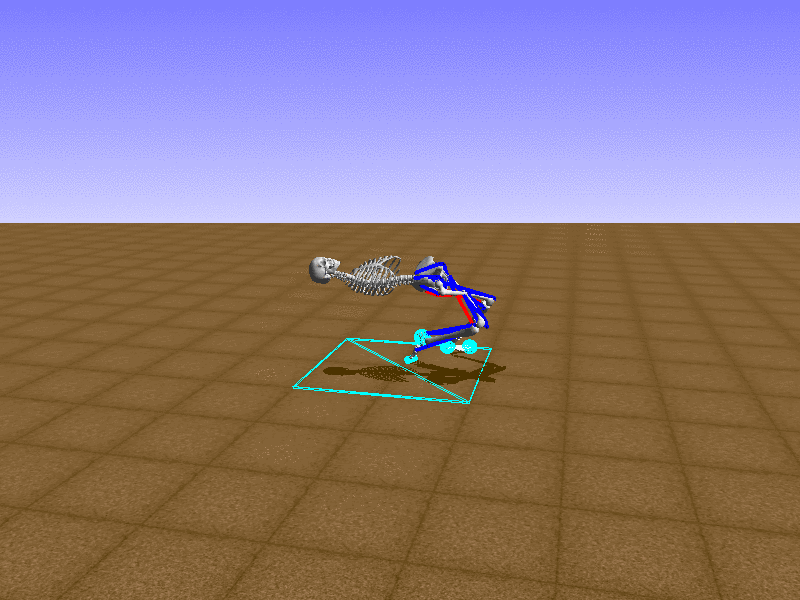
Awesome! We now have some basic intuition on how each muscle affects the biomechanical model.
osim-rl-helper
KerasDDPGAgent
A brand new agent called KerasDDPGAgent was added to the osim-rl-helper repository. This agent uses Deep Deterministic Policy Gradient (DDPG) method by Lillicrap et al. (2015). You need to install keras and keras-rl packages to run this agent.
conda install keras
pip install keras-rl
The syntax for testing and submitting KerasDDPGAgent is identical to previous agents, using run.py.
./run.py KerasDDPGAgent
./run.py KerasDDPGAgent --submit
To run or submit, you need a pretrained model saved in KerasDDPGAgent_actor.h5f and KerasDDPGAgent_critic.h5f. These files are generated and updated when you train the KerasDDPGAgent.
To train KerasDDPGAgent, you need to specify the number of steps to train the agent with the -t/--train flag. For example, the command below trains the agent for 1000 time steps.
./run.py KerasDDPGAgent --train 1000
The KerasDDPGAgent inherits the KerasAgent template, which defines train(), test(), submit() functions.
You can check the source code of KerasDDPGAgent in /helper/baselines/keras/KerasDDPGAgent.py. You can check the source code of KerasAgent in /helper/templates/ directory.
Client Wrappers
The keras-rl package requires an env parameter. However, during submission, the agent needs to interact with the client. Thus, I created a wrapper that transforms the client into the format of a local environment. The ClientToEnv wrapper simply wraps a client instance into an env.
class ClientToEnv:
def __init__(self, client):
"""
Reformats client environment to a local environment format.
"""
self.reset = client.env_reset
self.step = client.env_step
The client returns observations in dictionary format, so the DictToList wrapper transforms the dict-type observation to list-type using the code from ProstheticsEnv.get_observation().
class DictToList:
def __init__(self, env):
"""
Formats Dictionary-type observation to List-type observation.
"""
self.env = env
def reset(self):
state_desc = self.env.reset()
return self._get_observation(state_desc)
def step(self, action):
state_desc, reward, done, info = self.env.step(action)
return [self._get_observation(state_desc), reward, done, info]
# _get_observation() omitted
Finally, because the client does not accept NumPy types (since they cannot be converted to JSON), I created a JSONable wrapper that converts NumPy ndarrays to lists.
class JSONable:
def __init__(self, env):
"""
Converts NumPy ndarray type actions to list.
"""
self.env = env
self.reset = self.env.reset
def step(self, action):
if type(action) == np.ndarray:
return self.env.step(action.tolist())
else:
return self.env.step(action)
You can check the source code of the wrappers in /helper/wrappers/ directory.
What’s Next?
Łukasz Kidziński (@kidzik), the osim-rl project initiator and lead, kindly created a page explaining the meaning behind each number in the observation dictionary. I plan to analyze the observation space and monitor the observations to see how they change throughout an episode.
With the current environment, it is very easy for the agent to get stuck in a local optima. The reward is determined by the location of the pelvis, and the easiest way to move the pelvis forward is by thrusting the hip. However, as shown above, such “hip-thrust” action makes the agent lose balance. A good way to combat this problem is to customize the rewards. Adam Stelmasczczyk, a participant of the Learning to Run competition, wrote a great article about their team’s “reward hacking” attempts. I will try to imitate their approach.