Weeks
- Week 1: Understanding the Challenge
- Week 2: Understanding the Action Space
- Week 3 - 4: Understanding the Observation Space
- Week 5: Understanding the Reward
- Week 6 - 8: General Techniques of RL
- Week 9 - 10: Unorthodox Approaches
Latest News
Congrats to nskiran (#1), rl_agent (#3), ymmoy999 (#4), Firework (#6), Yongjin (#8), HP (#9), and jack@NAN (#10) for getting their new agents to Top 10 this week! Read more about the current leaderboard in the section below.
I misinterpreted the transition from Round 1 to Round 2. It has been clarified that Round 1 will continue until September 16th, and once it is over, Round 2 will be held until September 30th (tentative). Round 1 is the current round where the agent needs to follow a constant horizontal velocity vector of 3 m/s. In contrast, for Round 2, the target velocity vector will be time-dependent. More information should be available soon.
Meanwhile, congratulations to the AI for Prosthetics team for getting Google Cloud Platform as a sponsor! Top 400 teams with positive points by August 15th will be awarded $250 cloud credits. Hope this encourages many of you to participate, since there are currently about 50 people in the leaderboard, with 34 people with positive scores!
Leaderboard
Here are the top 10 scores for this week. A lot of new people climbed up the ladder this week, with only Mattias_Ljungström staying in the top 10 with his old agent. Only 6 of the top 10 have participated in the Learning to Run challenge, so feel free to join the competition as a newcomer!
| Participant | Cumulative Reward | Last Submission (UTC) |
|---|---|---|
| nskiran | 2240.904 | Mon, 23 Jul 2018 05:25 |
| lijun | 2230.505 | Mon, 16 Jul 2018 09:03 |
| rl_agent | 2192.552 | Thu, 26 Jul 2018 07:51 |
| ymmoy999 | 1910.049 | Wed, 25 Jul 2018 13:03 |
| Mattias_Ljungström | 1632.521 | Wed, 11 Jul 2018 15:30 |
| Firework | 1582.416 | Fri, 20 Jul 2018 03:04 |
| aadilh | 1461.556 | Mon, 16 Jul 2018 00:02 |
| Yongjin | 1297.568 | Wed, 25 Jul 2018 00:03 |
| HP | 1278.196 | Tue, 24 Jul 2018 13:48 |
| jack@NAN | 1255.956 | Fri, 27 Jul 2018 05:26 |
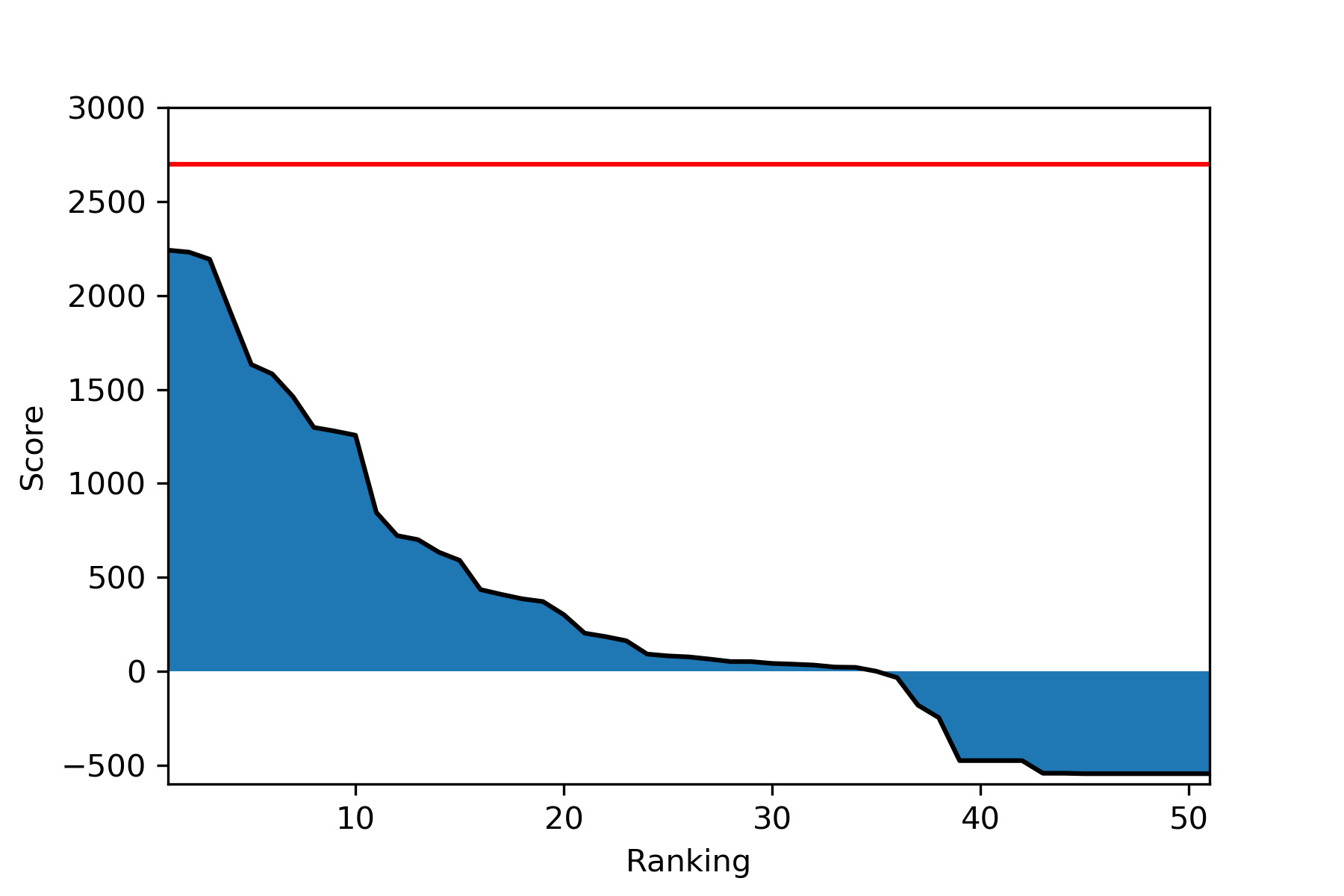
Reward
The goal of reinforcement learning is defined by the reward signal - to maximize the cumulative reward throughout an episode. In some ways, the reward is the most important aspect of the environment for the agent: even if it does not know about values of states or actions (like Evolutionary Strategies), if it can consistently get high return (cumulative reward), it is a great agent.
Reward Calculation
In Round 1, the goal of the agent is to run at a constant speed of 3 meters per second. This is shown by the calculation of reward:
\[r_t := 9 - \left| 3 - v_t \right|^2\]where $v$ is the horizontal velocity vector of the pelvis. In other words,
reward = 9 - abs(3 - obs['body_vel']['pelvis'][0]) ** 2
Note that if $\mid 3 - v_t \mid > 3$, then the reward $r_t$ is negative. This is true if the velocity of the pelvis is too fast ($v_t > 3$) or if the velocity is negative ($v_t < 0$). Of course, once the episode is terminated, no more reward can be accumulated.
Now, let’s compare two possible ways of going 1 meter: going 1 m/s for 100 steps (1 second) or going 3 m/s for 33 steps (0.33 seconds). For simplicity, let’s assume that these are the only rewards the agent receives. Then, the return for the first method is:
\[\sum^{100}_{k=1} (9 - \left| 3 - 1\right|^2) = 100 \times 5 = 500\]In comparison, the return for the second method is:
\[\sum^{33}_{k=1} (9 - \left| 3 - 3 \right|^2) = 33 \times 9 = 297\]There is a surprising amount of difference between the two methods. Of course, the second method is more advantageous if the agent can consistently maintain that velocity, since that will generate the maximum return of 2700. However, if such policy results in a premature termination, slowly accumulating rewards might result in a higher return.
Reward Modification
Recently, there have been great successes on reinforcement learning methods that modify the reward signal. Two noteworthy papers are Playing hard exploration games by watching YouTube and RUDDER: Return Decomposition for Delayed Rewards. The exemplary environment used in these papers are Montezuma’s Revenge and Bowling from Atari 2600. Both games have sparse rewards (few nonzero rewards), so the agent must explore for a long time before discerning good or bad actions. In these games, the state-of-the-art (SotA) methods are one that reshape the reward (Bowling SotA, Montezuma’s Revenge SotA).
The Prosthetics environment has a dense reward function: there is a nonzero reward at every step. Thus, the agent can be trained without modifying the reward in any way. However, that does not prohibit us from modifying the reward signal. Complex modifications like Imitation Learning (DQfD or YouTube) might not be needed, but the agent could benefit from a reward signal that is more insightful.
Note that this is a somewhat dangerous approach. We are attempting to inject our prior knowledge to the agent through the reward. In general, the reward signal should communicate the agent what its goal is, not how it should achieve that goal. A better place to use prior knowledge is initial policy or value function (Sutton and Barto, 2018). One way to address this problem would be to fine-train the agent without the reward modification once it performs reasonably well.
If it is not obvious how the reward signal should be modified, it is helpful to compare successful and unsuccessful agents. Here are three top-performing agents by nskiran, lijun, and rl_agent, each with the score of 2240.904, 2230.505, and 2192.552.
For comparison, here are 3 agents in the 700~800 range:
Finally, here are 3 agents in the 150~400 range:
Stayin’ Alive
One of the noticeable difference between the agents is that the high performing agents have longer episodes. This is somewhat obvious, you cannot expect the agent to score above 2000 if it cannot stay alive for more than 222 steps. Thus, a good way to train the agent could be to first train it to “stay alive,” giving little or no weight to the actual reward distribution. This can be done via a simple reward function:
\[r_t = 1\]This is the exact opposite of other environment settings such as maze-solving where the agent’s goal is to have shorter episodes.
Upright Posture
Now, let’s see how the episode gets terminated. The termination condition is filling 300 steps or the height of the pelvis falling below 0.6 meters, but it seems like the primary cause of all premature termination is the upper body swaying too much. Thus, it is possible to incentivize the agent to hold the upper body still. However, there is a fine line: most top-performing agents also sway their body, perhaps due to the prosthetics making the model fundamentally unbalanced. To inject this knowledge, some fine tuning might be necessary.
Note that this is somewhat similar to the Lean Forward approach used by participants in the last competition. In the last year’s competition, there was no $z$-axis, and the model was symmetric, so the upper body was either in front of or behind the body. Thus, the obvious conclusion was to keep the upper body leaning forward, so the reward was shaped to promote this behavior.
osim-rl-helper
I have refactored the agents and the environment wrappers to give a more consistent experience to those who might be using the osim-rl-helper package. If you are building upon the osim-rl-helper package, make sure you test your agents locally before you submit!
TensorforcePPOAgent
I created a new agent that uses Proximal Policy Optimization Algorithms (PPO) by Schulman et al. (2017) and the tensorforce package. Most top-performing agents in the last year’s Learning to Run contest used either the DDPG algorithm or the PPO algorithm, so try experimenting with both! The easiest experiments would be to make the neural network architecture more complex or to tune the hyperparameters. You can also use different optimizers (Adam, RMSprop, etc.).
What’s Next?
This post concludes the series of posts about the environment! I will now write about my analysis of the best agents in the last year’s competition. I also hope to add a better DDPG agent, since although the keras-rl package is intuitive, it is slow.
I plan to keep the new Leaderboard section so that people can see the general trend of the scores with a single chart.