Weeks
- Week 1: Understanding the Challenge
- Week 2: Understanding the Action Space
- Week 3 - 4: Understanding the Observation Space
- Week 5: Understanding the Reward
- Week 6 - 8: General Techniques of RL
- Week 9 - 10: Unorthodox Approaches
Latest News
Łukasz Kidziński, the project lead of osim-rl, had a webinar on Robust control strategies for musculoskeletal models using deep reinforcement learning on August 7th. For those who missed the webinar, here is the video:
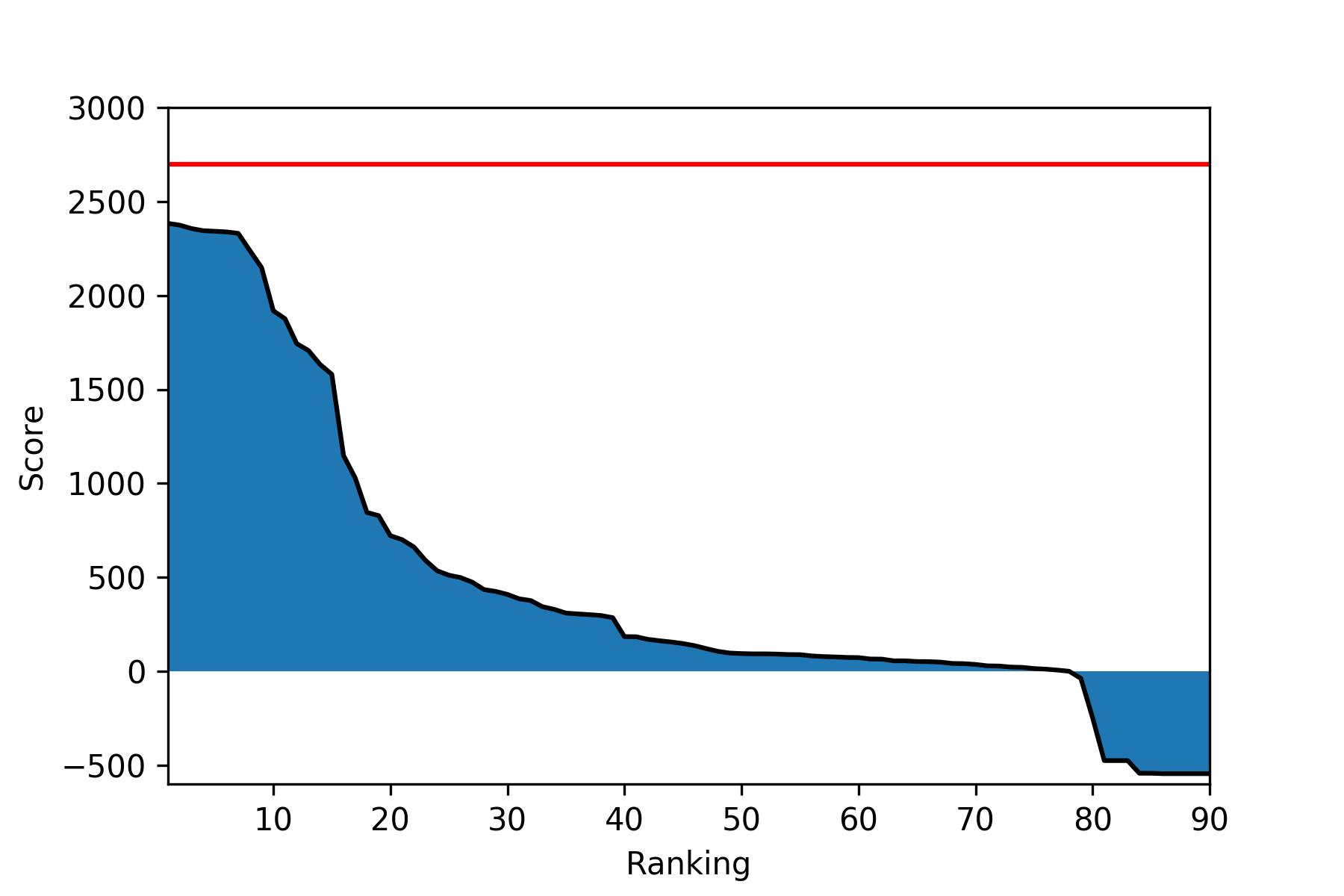
Leaderboard
Here are the top 10 scores for this week. Three new people (jbr, qyz55, jssk) appeared in the top 10, and all but one agent were submitted in August.
| Participant | Cumulative Reward | Last Submission (UTC) |
|---|---|---|
| jbr | 2387.517 | Tue, 7 Aug 2018 21:44 |
| Firework | 2374.061 | Fri, 3 Aug 2018 04:49 |
| lijun | 2356.148 | Mon, 6 Aug 2018 10:16 |
| qyz55 | 2344.622 | Sun, 12 Aug 2018 07:32 |
| nskiran | 2341.482 | Tue, 31 Jul 2018 14:03 |
| jack@NAN | 2338.136 | Fri, 10 Aug 2018 05:15 |
| rl_agent | 2330.393 | Tue, 7 Aug 2018 17:54 |
| ymmoy999 | 2238.523 | Mon, 6 Aug 2018 14:02 |
| Yongjin | 2148.157 | Thu, 9 Aug 2018 22:54 |
| jssk | 1918.556 | Fri, 10 Aug 2018 06:06 |
There are 36 new participants in the competition! Most of them have successfully gotten above 0, qualifying themselves for the Google Cloud Platform credits.
General Techniques
This week, we take a step back from the competition and study common techniques used in Reinforcement Learning.
Frame Skipping
Frame skipping is a technique of repeating selected actions for $k$ steps. First introduced in Section 5 of Playing Atari with Deep Reinforcement Learning for Deep Q-Networks on Atari environments, this technique can significantly decrease the amount of time each episode takes.
Discretized Actions
The ProstheticsEnv environment has continuous actions, and the Policy Gradient algorithms support continuous actions. However, discretization of actions has worked surprisingly well in many Policy Gradient algorithms. The most extreme discretization would be to excite the machine fully (1) or not at all (0). A more general discretization could use more intermediate values.
Recently, OpenAI published Learning Dexterous In-Hand Manipulation that used Proximal Policy Optimization (PPO), showcasing a successfully trained robot hand able to manipulate a square block. In Section 4.2, they mention that
While PPO can handle both continuous and discrete action spaces, we noticed that discrete action spaces work much better. This may be because a discrete probability distribution is more expressive than a multivariate Gaussian or because discretization of actions makes learning a good advantage function potentially simpler. We discretize each action coordinate into 11 bins.
Distributed Learning
If one has the resources, the most significant increase would be through distributed learning. If one has the CPUs and GPUs (or emulate them), parallelizing computations results in dramatic speedup for collecting experience.
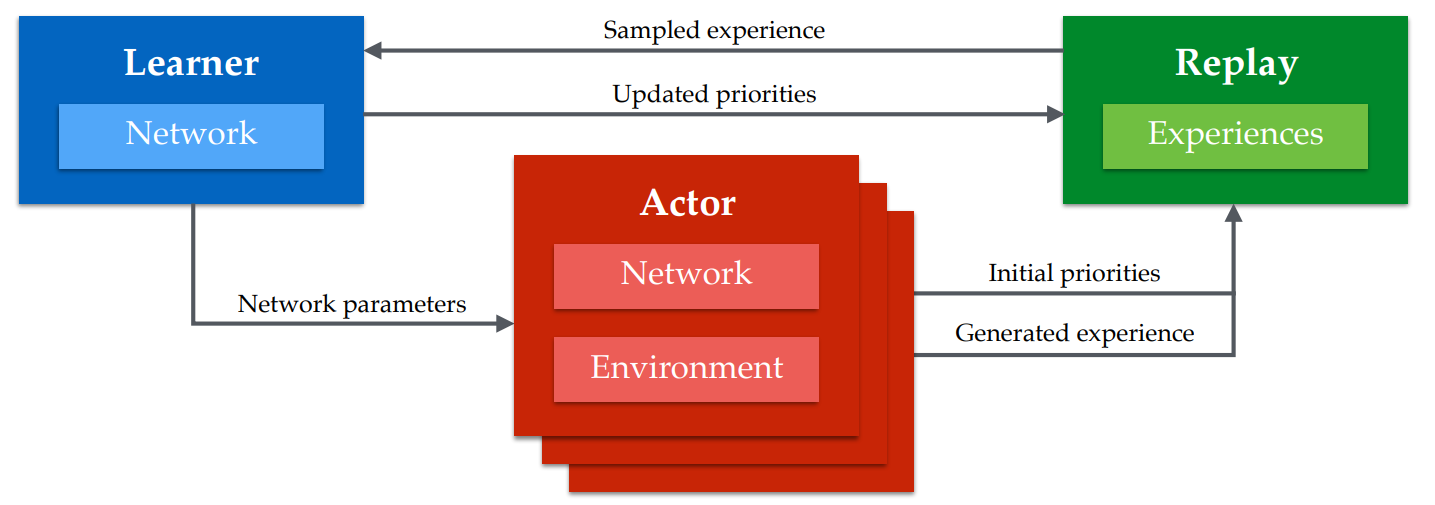
Most state-of-the-art results use parallelization extensively. DeepMind’s Distributed Prioritized Experience Replay showcases Ape-X DQN that achieves state-of-the-art results for most Atari 2600 games by using 376 cores and 1 GPU, collecting experience 200 times faster than Rainbow.
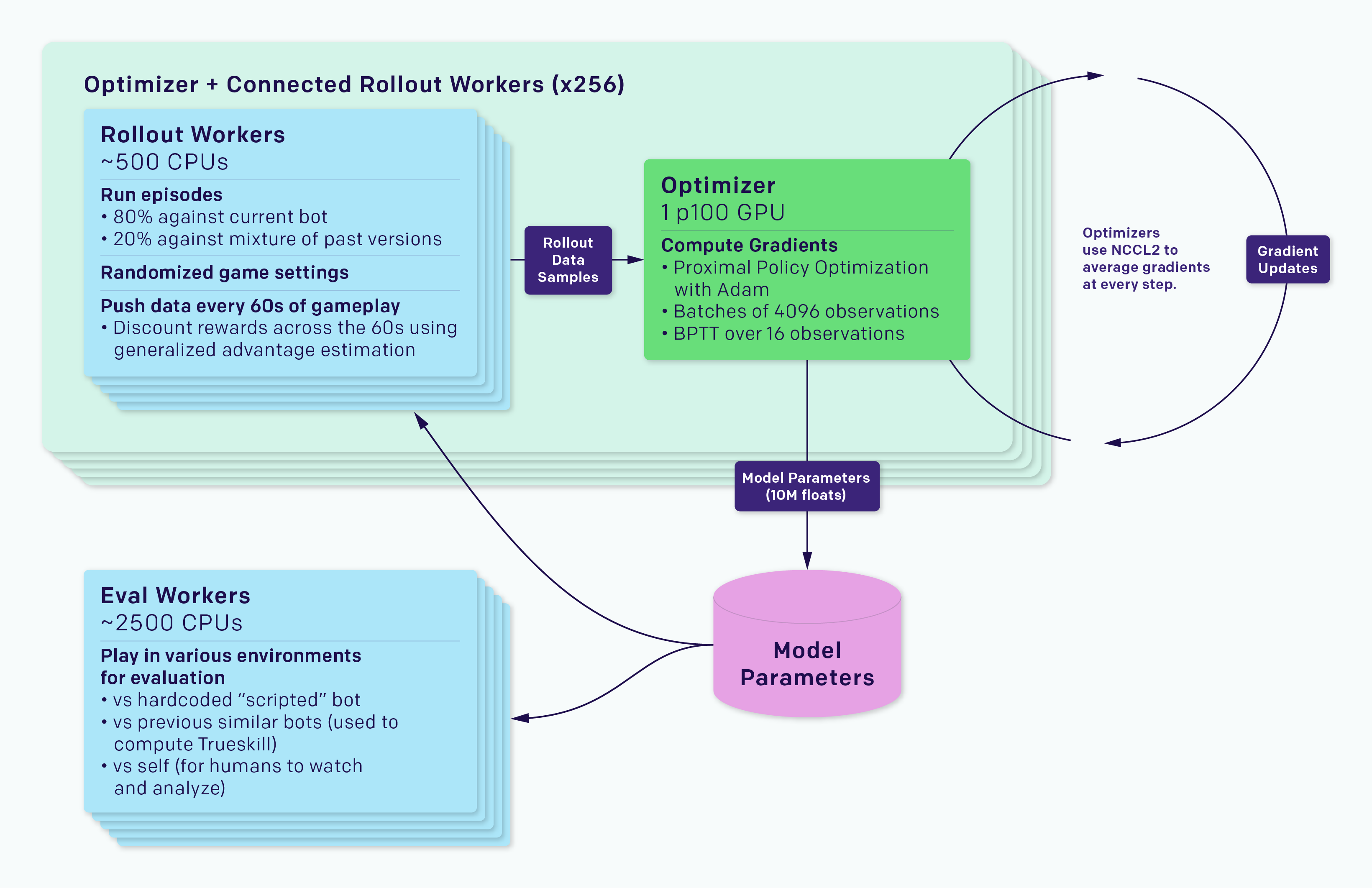
OpenAI Five, an AI that won against professional gamers of Dota 2, a two-sided game with 5 players on each side, also utilized 128000 CPU cores and 256 P100 GPUs, collecting 900 years of experience per day.
To try out distributed learning, I recommend Ray’s RLLib, Reinforce.io’s Tensorforce, and OpenAI’s Baselines.
For some more ideas, take a look at top solutions of NIPS 2017 Learning to Run challenge!
What’s Next?
Although Policy Gradient methods such as DDPG and PPO are more natural choices for this challenge, I want to try using Deep Q-Networks! I have not yet decided which implementation to use, but it will be either unixpickle’s anyrl-py or Kaixhin’s Rainbow.
Also, I have never used Google Cloud Platform (GCP) before, but now I have both the supply ($250 credit) and the demand (more computational power needed for training agents) for it, so it sure is a good time to start!