Last week, I created a pull request (PR #103) improving documentation, which was merged thanks to Sergio Guadarrama and my mentor Oscar! This week, I focused on getting used to environment wrappers, and in this post I will recap my progress.
I also had a joy of having a conference call with Paige Bailey and Oscar. Paige is the Senior Developer Advocate of TensorFlow (“TensorFlow Mom”) and the lead organizer for GSoC TensorFlow. I will have biweekly (once every two weeks) check-in meetings with them, separate from the weekly meetings with my mentors Oscar Ramirez and Mandar Deshpande. Having all these mentors that I can ask questions to is amazing: one of my goals for GSoC is to ask as many thoughtful questions as I can think of!
By the way, here are some interesting statistics about GSoC 2019 published by Google Open Source.
Creating Environment Wrapper
As discussed in Issue #21, curiosity algorithms such as Random Network Distillation (RND) is best implemented as in the form of an environment wrapper. As the name suggests, an environment wrapper wraps the environment, modifying the way it behaves in some way. OpenAI Gym contains a few examples of these wrappers, which allow reward clipping, reward binning, or setting max timesteps.
Following my mentor Mandar’s suggestion, I decided to implement a simple RewardClipWrapper that clips all rewards to some bound $[min, max]$.
OpenAI Gym Interface
The agent-environment interface of OpenAI Gym can be summarized by the following code snippet:
observation = env.reset() action = agent.get_action(observation) observation, reward, done, info = env.step(action)
There are two main functions: env.reset() and env.step() .
The reset function env.reset() resets the environment and returns the initial observation to the agent. The agent can use this observation to choose an action. The environment then receives the action, and returns the consequence of the action as four variables. It returns the observation after the action observation, the reward from the timestep reward, whether the episode is over done, and any other extra information info.
TF-Agents Interface
The agent-environment interface of TF-Agents is written in a detailed manner in their Environments tutorial.
class PyEnvironment(object):
def reset(self):
"""Return initial_time_step."""
self._current_time_step = self._reset()
return self._current_time_step
...
@abc.abstractmethod
def _step(self, action):
"""Apply action and return new time_step."""
self._current_time_step = self._step(action)
return self._current_time_step
TF-Agents also has env.reset() and env.step() methods. However, they have a more consistent return types. Both methods return a named tuple TimeStep, which consists of the step type step_type, reward signal reward, discount factor discount, and next observation observation.
RewardClipWrapper
# OpenAI Gym
import numpy as np
from gym import RewardWrapper
class ClipReward(RewardWrapper):
r""""Clip reward to [min, max]. """
def __init__(self, env, min_r, max_r):
super(ClipReward, self).__init__(env)
self.min_r = min_r
self.max_r = max_r
def reward(self, reward):
return np.clip(reward, self.min_r, self.max_r)
Above is the ClipReward class defined in OpenAI Gym. As such, environment wrappers only modify relevant parts of the environment. I used a similar approach to implement my RewardClipWrapper.
# TF-Agents
class RewardClipWrapper(PyEnvironmentBaseWrapper):
"""Clip all reward signals to a specified [min, max]."""
def __init__(self, env, min_r=-0.5, max_r=0.5):
super(RewardClipWrapper, self).__init__(env)
self.min_r = min_r
self.max_r = max_r
def _reset(self):
return self._env.reset()
def _step(self, action):
time_step = self._env.step(action)
reward = np.clip(time_step.reward, self.min_r, self.max_r)
time_step = time_step._replace(reward=reward)
return time_step
Above is my implementation. As you can see, the initialization __init__ is identical, and both use the same NumPy clip function np.clip to modify the reward. The core differences are what these classes inherit, and how they interact with the agent.
Using Environment Wrapper
To verify that this environment wrapper is working, we need to test it with an actual RL environment. Let’s modify tf_agents/agents/dqn/examples/v1/train_eval_gym.py, one of the example scripts, to use RewardClipWrapper.
In the script, the environment is initialized in the following line:
tf_env = tf_py_environment.TFPyEnvironment(suite_gym.load(env_name))
An OpenAI Gym environment is loaded and converted to a PyEnvironment through suite_gym.load(). Then PyEnvironment is wrapped into TFPyEnvironment. While loading a Gym environment, it is possible to specify custom environment wrappers as a list or a tuple through the env_wrappers parameter.
tf_env = tf_py_environment.TFPyEnvironment(suite_gym.load( env_name, env_wrappers=[wrappers.RewardClipWrapper], )) eval_py_env = suite_gym.load(env_name)
(tf_env is the environment used to train the agent, and eval_py_env is the environment used to evaluate teh agent.)
Now we can run the modified script.
# Ran with RewardClipWrapper python tf_agents/agents/dqn/examples/v1/train_eval_gym.py \ --root_dir=$HOME/tmp/dqn_v1/gym/CartPole-v0/clip/ \ --alsologtostderr
I have also ran the unmodified script shown below to compare the results of the two.
# Ran without RewardClipWrapper python tf_agents/agents/dqn/examples/v1/train_eval_gym.py \ --root_dir=$HOME/tmp/dqn_v1/gym/CartPole-v0/no-clip/ \ --alsologtostderr
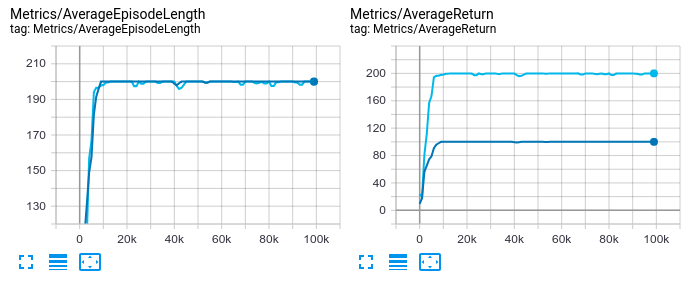
The results can be visualized via TensorBoard
tensorboard --logdir $HOME/tmp/dqn_v1/gym/CartPole-v0/ --port 2223
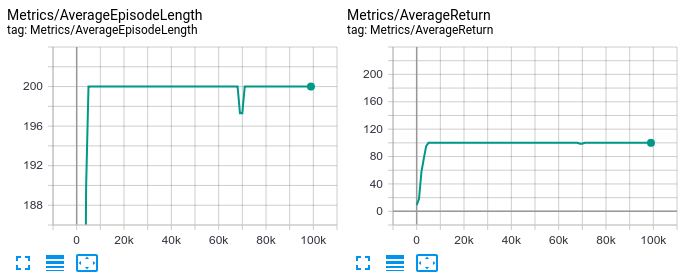
In CartPole, the agent receives $+1$ reward on every step until the episode terminates, so the episode length corresponds to total episode reward (a.k.a. return). With the reward clipped to $[-0.5, 0.5]$, the agent will receive $+0.5$ reward on every step, so the the return will equal half of episode length.
Configuring with gin
Gin is a “lightweight configuration framework for Python” used in TF-Agents. My mentor Oscar suggested to me to learn gin and referred to its documentation. By adding a @gin.configurable decorator in front of a class, it is possible to modify parameters in a separate configuration file (ex. config.gin).
@gin.configurable
# TF-Agents
class RewardClipWrapper(PyEnvironmentBaseWrapper):
"""Clip all reward signals to a specified [min, max]."""
def __init__(self, env, min_r=-0.5, max_r=0.5):
super(RewardClipWrapper, self).__init__(env)
self.min_r = min_r
self.max_r = max_r
def _reset(self):
return self._env.reset()
def _step(self, action):
time_step = self._env.step(action)
reward = np.clip(time_step.reward, self.min_r, self.max_r)
time_step = time_step._replace(reward=reward)
return time_step
We also need to create a new gin file. Like other gin files, I have created a new file reward_clip.gin.
#-*-Python-*-
import tf_agents.environments.suite_gym
import tf_agents.environments.wrappers
## Configure Environment
ENVIRONMENT = @suite_gym.load()
suite_gym.load.environment_name = %ENVIRONMENT_NAME
suite_gym.load.env_wrappers = [
@wrappers.RewardClipWrapper,
]
# Note: The ENVIRONMENT_NAME can be overridden by passing the command line flag:
# --params="ENVIRONMENT_NAME='CartPole-v1'"
ENVIRONMENT_NAME = 'CartPole-v0'
Finally, we need to tell the script to use the gin file we just created. There is already an import statement at the beginning of tf_agents/agents/dqn/examples/v1/train_eval_gym.py, so we just need to modify the part where the agent is defined.
gin.parse_config_file('tf_agents/environments/configs/reward_clip.gin')
tf_env = tf_py_environment.TFPyEnvironment(suite_gym.load())
eval_py_env = suite_gym.load()
We can now run the script again, and indeed, the reward is successfully clipped.
python tf_agents/agents/dqn/examples/v1/train_eval_gym.py \ --root_dir=$HOME/tmp/dqn_v1/gym/CartPole-v0/clip-with-gin/ \ --alsologtostderr
What’s Next?
Now that the coding period has begun, I will start my main project: adding curiosity to TF-Agents. The first curiosity method I will add is Exploration by Random Network Distillation by Burda et al. I have reviewed the paper already, so I do not plan on reviewed the paper in detail again. Instead, I will dive straight into implement Random Network Distillation (RND). My goal is to implement RND by the end of the first phase (June 30th).