Time flies! It’s already mid-August, and I received an email about project submission guidelines for the final evaluation. Luckily, with the help of Oscar and Mandar, I was able to resolve many bugs in my implementation of Random Network Distillation! I have evaluated and verified that Random Network Distillation encourages exploration of the PPO agent, so in this post I introduce the Mountain Car environment and share the performance of RND.
Mountain Car
To evaluate the effectiveness of RND in encouraging exploration, Random Network Distillation was run on MountainCar-v0.
MountainCar is a reinforcement learning environment where the agent’s goal is to move a car up a steep valley and reach the flag. Because the valley is very steep, the car cannot simply climb up the hill with its own strength. Instead, the car must move back and forth to gain momentum.
Mountain Car is a simple environment with $R^2$ observation space and three actions possible. Yet, famous baseline algorithms such as Deep Q-Network (DQN) or Proximal Policy Optimization (PPO) have trouble finding optimal solution due to insufficient exploration. Thus, it is a suitable environment to test the RND agent.
For every timestep, a reward of -1 is given. To ensure that each episode does not take too long, a time limit of 200 is enforced. In other words, the worst episodic return is -200.
Evaluation of RND
RND was tested on Mountain Car with 10000 global steps, where the agent was evaluated with its current policy every 500 steps. The hyperparameters were not tuned: I used the default hyperparameters in TF-Agents.

During each evaluation, the average return of trajectories were calculated. The orange line shows RND and the red line shows PPO. PPO agent always terminates the episode through time limit: it never reaches the flag at the top of the mountain. In contrast, the RND agent is able to reach the goal in the first evaluation.
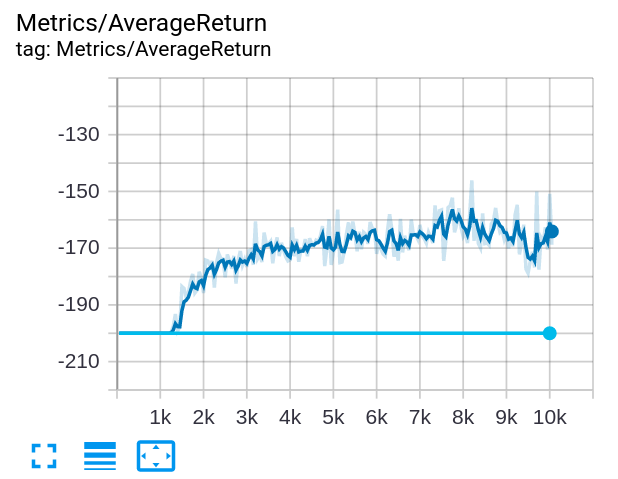

Inspired by the original RND paper (Burda et al., 2018), I also plotted the average RND loss (intrisic reward) with average return during training. The peak of average RND loss approximately matches the timestep that the average return starts to rise. The agent receives unfamiliar observations as it goes closer to the flag, which results in a high prediction loss. Since the RND loss is also the intrinsic reward, the agent is rewarded to continue visiting this state.
What’s Next?
With Mountain Car, I verified the performance and utility of RND. Now, all that is left is to evaluate RND on Atari environments known for hard exploration and sparse rewards!
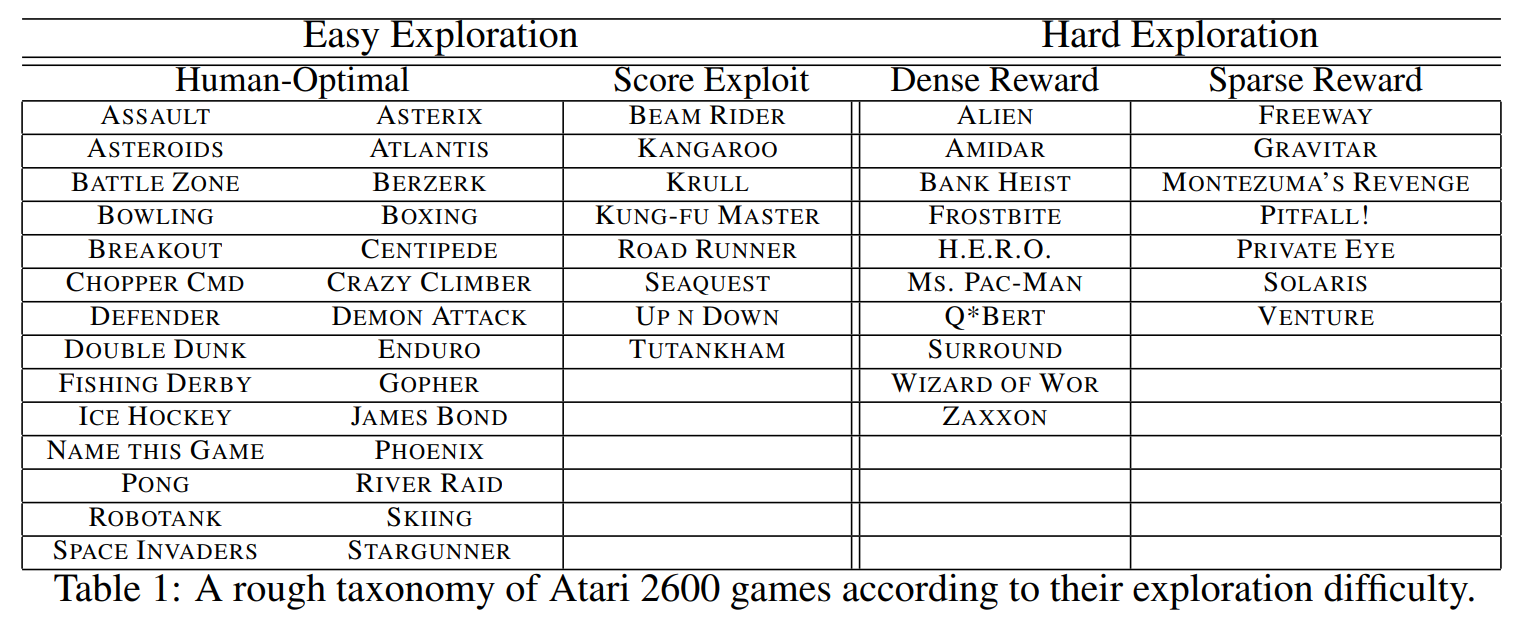
Out of 57 Atari environments, Burda et al. tested RND on the 6 of the 7 hard-exploration sparse-reward environments commonly called “Atari Hard.” (excluding Freeway)
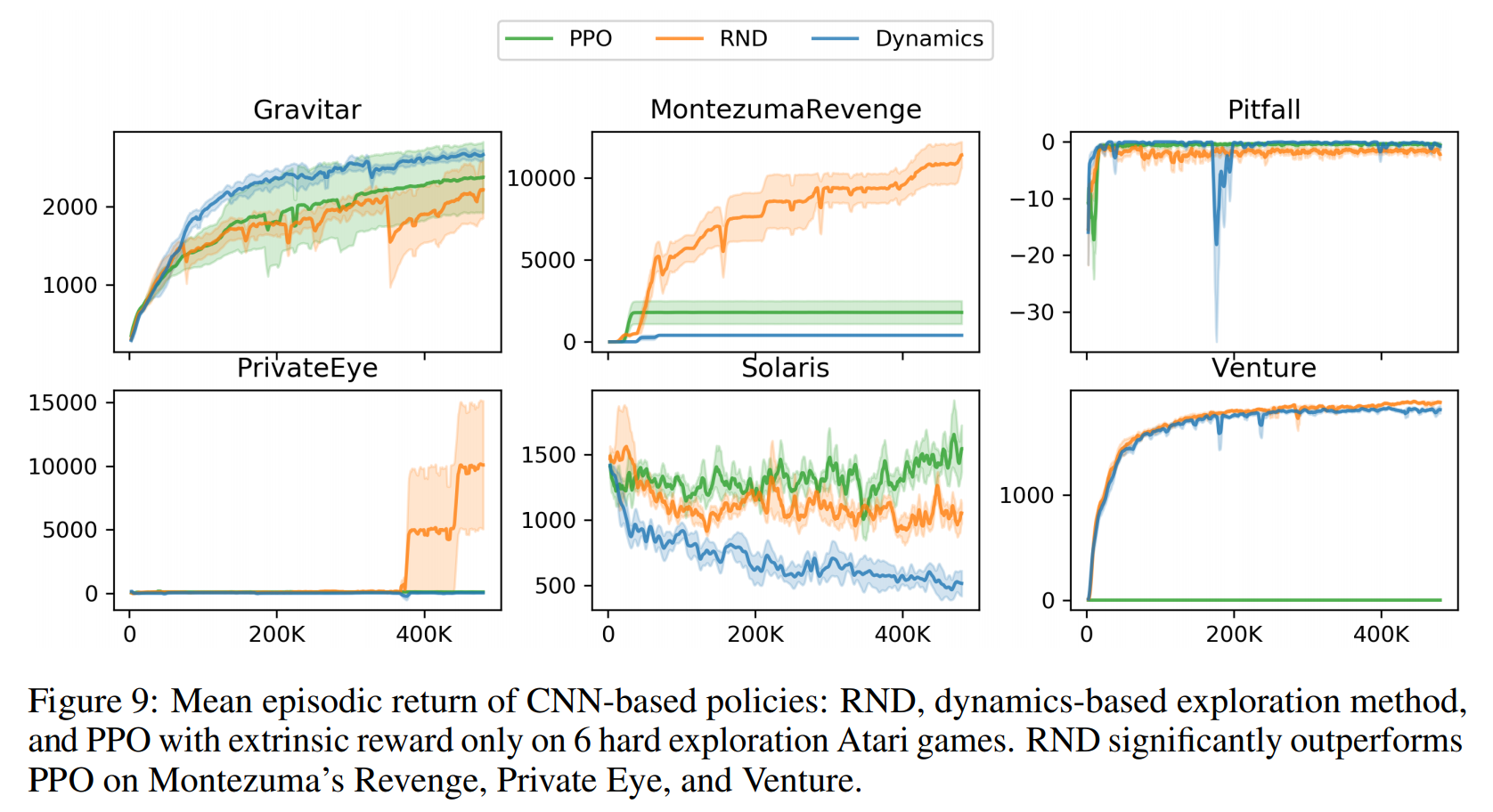
The difference between PPO and RND is most apparent in Montezuma’s Revenge and Venture, so these will be my next evaluation environments!