On April, OpenAI held a two-month-long competition called the Retro Contest where participants had to develop an agent that can achieve perform well on unseen custom-made stages of Sonic the Hedgehog. The agents were limited to 100 million steps per stage and 12 hours of time on a VM with 6 E5-2690v3 cores, 56GB of RAM, and a single K80 GPU.
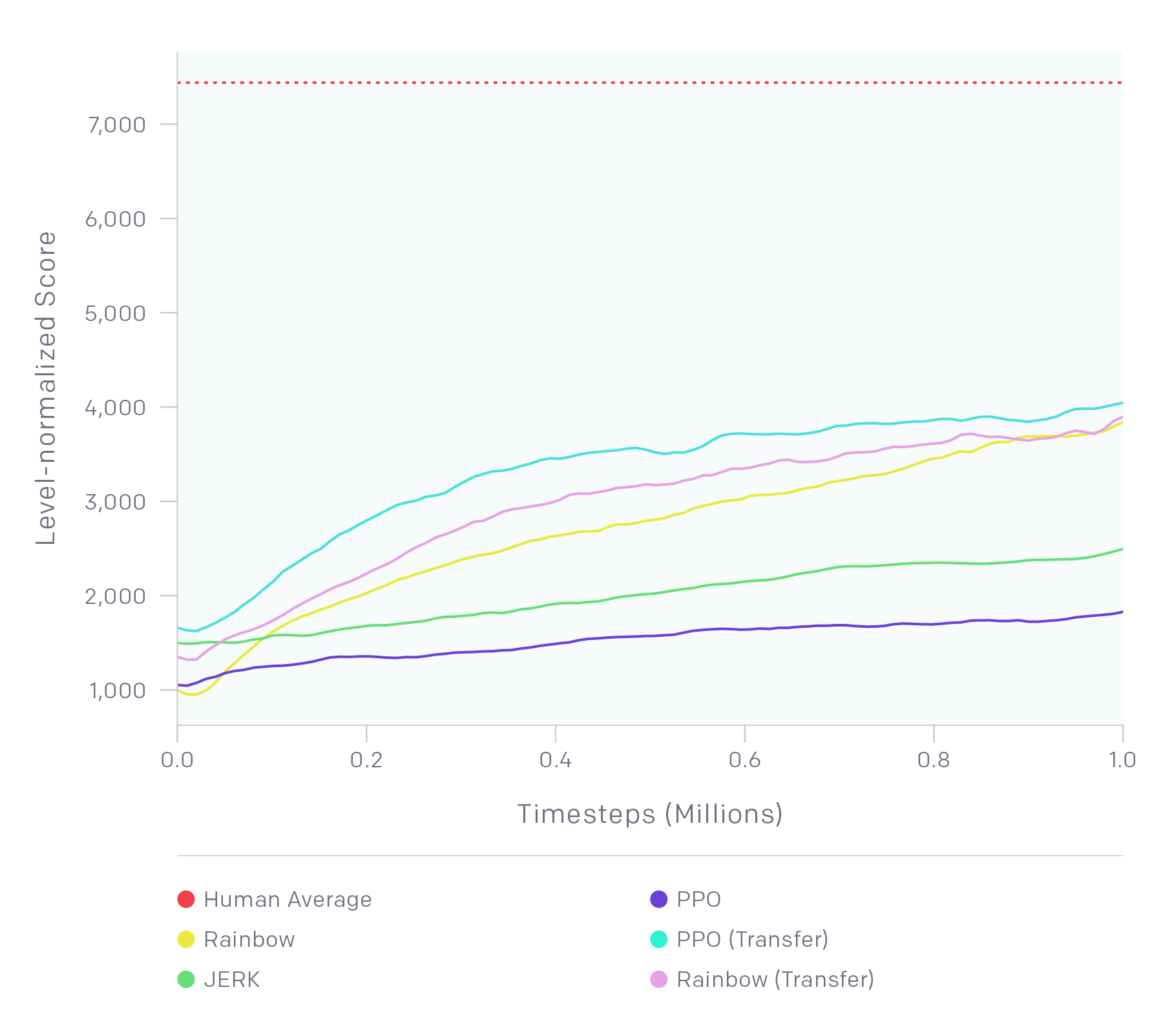
OpenAI provided three baseline agents: JERK (Just Enough Retained Knowledge), Rainbow DQN (Deep Q Network), and PPO (Proximal Policy Optimization). JERK is a basic algorithm without a neural network. Rainbow DQN and PPO are well-known algorithm that achieved superhuman level of play for most Atari 2600 games. However, in Sonic, none of the three agents came close to human performance. Whereas humans had an mean score of 7438.2, the highest agent (Joint PPO) had a mean score of 3127.9. In other words, there were lots of room for improvement.
When I started the competition on May, I knew very little about Reinforcement Learning. I skimmed through David Silver’s lectures and just started reading Sutton and Barto’s book. I ran few environments and baseline agents in OpenAI Gym, but I never developed an agent. Thus, I knew that I was not ready for the competition. Yet, I had to join after watching this short video:
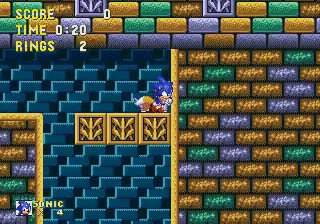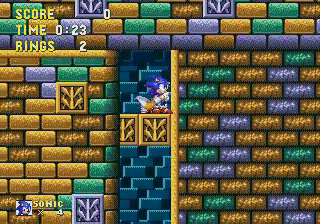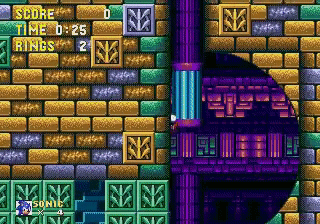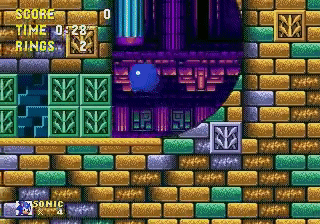
Through exploration, the agent found a “glitch” that allowed sonic to pass parts of the map! This convinced me that Reinforcement Learning agents could achieve superhuman results through nonhuman behaviors. My goal for this contest was to create an agent that can find glitches and use them.
On the first week, the only parts of code I changed in the baseline Rainbow DQN were the numbers. (In other words, I tuned the hyperparameters). I was familiar with only one hyperparameter: the learning rate, and randomly changing hyperparameters did not improve the agent’s performance. Thus, by the second week, I abandoned this approach and started reading papers behind the Rainbow DQN.
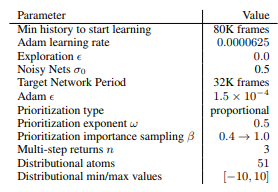
Among the seven papers, the Prioritized Experience Replay paper intrigued me the most. The simple idea of sampling experiences with priority instead of sampling randomly resulted in a stunning improvement in performance. Furthermore, the paper had plenty of suggestions for possible variants and improvements. Thus, I decided to focus on improving experience memory. The paper focused on prioritizing sampling, so I decided to focus on collection and deletion, the other aspects of experience replay.
The remainder of the month passed by quickly. Every day, I was implementing new ideas for collection and deletion and testing them. The results almost always surprised me: most ideas that I thought were clever achieved low scores, while ideas that I could barely rationalize achieved high scores. By the end of the competition, I was unsure what score to expect for any of my agents. (This is probably what Andrew Ng meant when he said that Machine Learning is a highly iterative process.)
The contest finished yesterday (June 5th). I was unable to rank in top 10 with any of my agents, and I still cannot pinpoint the best performing agent due to the high variance of the score. However, I did achieve my goal. My agent was able to find a glitch in a custom stage and used it to bypass time-consuming parts of the stage.

Even though I understand the algorithm behind the agent now, I am still just as excited watching the agent find a glitch as I was before starting the contest. I will continue to develop agents for other environments of OpenAI’s Gym Retro. There is always time for more (reinforcement) learning and glitch hunting!
I would like to sincerely thank the OpenAI team for hosting this wonderful competition. With Retro Contest, I was motivated to learn about DQNs, implement my ideas and test them, and meet wonderful helpful people also interested in Reinforcement Learning. Thank you!