In the last post, we installed the Obstacle Tower environment locally and verified that it was installed correctly. In this post, we will take a look at the game itself. It is crucial to understand the environment well to debug and improve the agents’ performance.
How to Run Game
Download the environment if you have not already:
Navigate to the folder you unzipped the downloaded environment. If you followed the guide, it should be under examples/ObstacleTower. Run the obstacletower.x86_64 by double-clicking. After the Unity logo, the game should start in a few seconds.
Here are the keyboard controls:
| Keyboard Key | Action |
|---|---|
| W, S, A, D | Move character forward / backwards / left / right |
| K, L | Rotate camera left / right |
| Space | Jump |
Procedural Generation
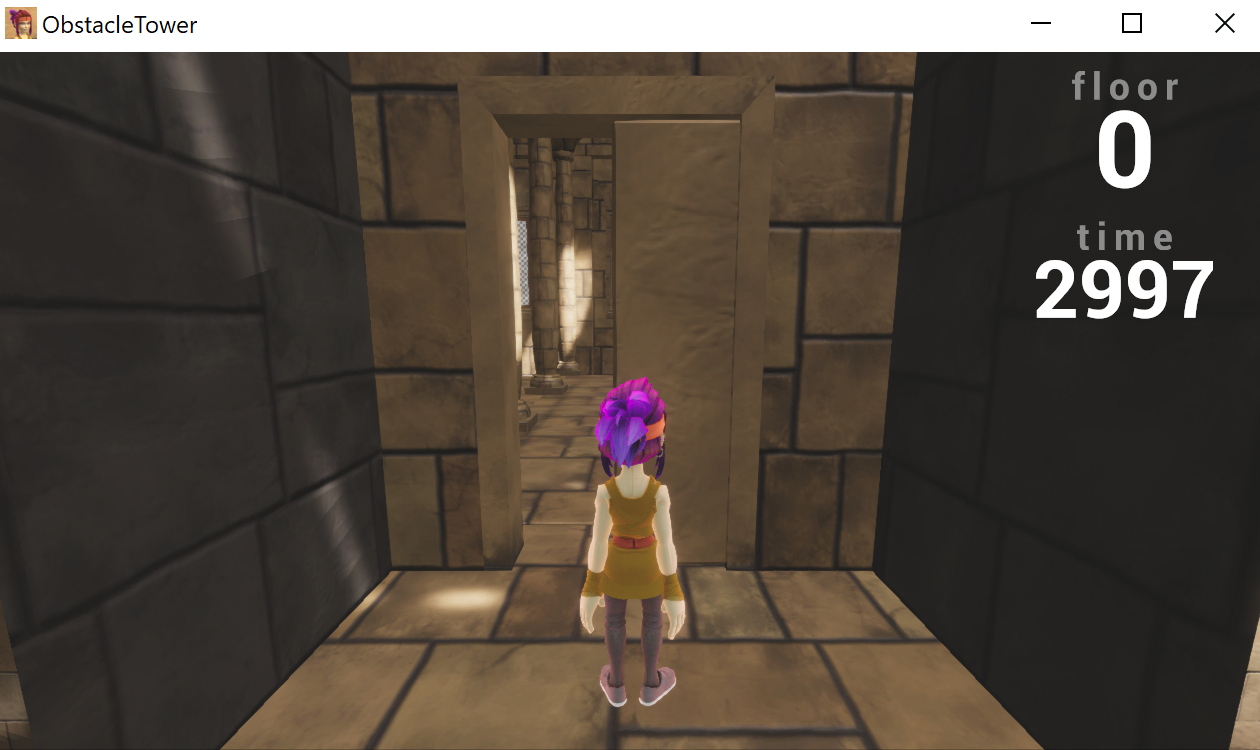

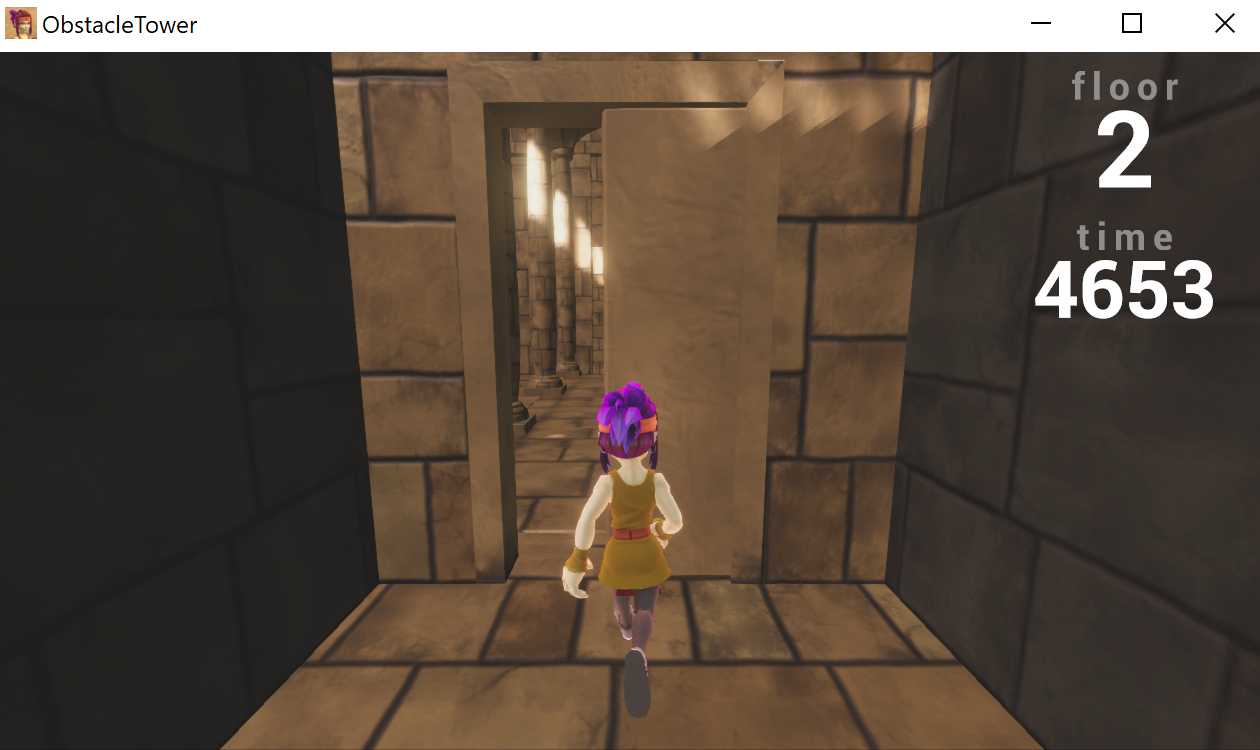




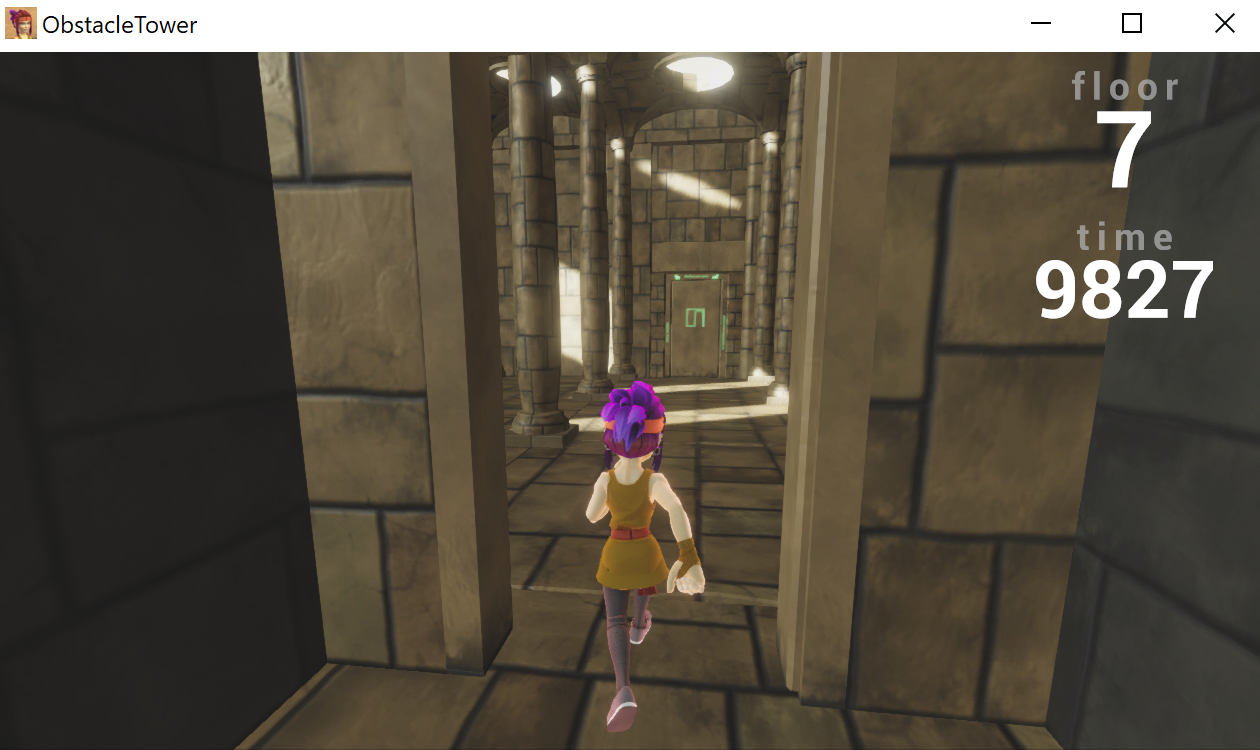


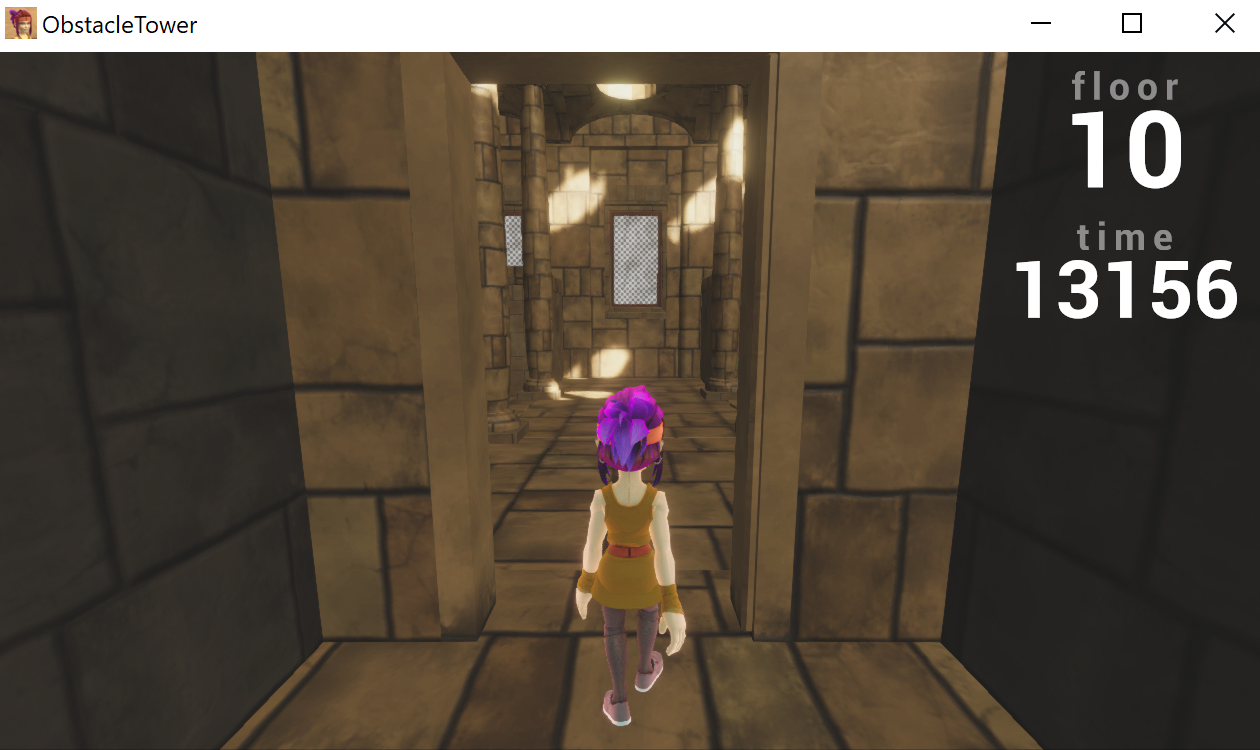
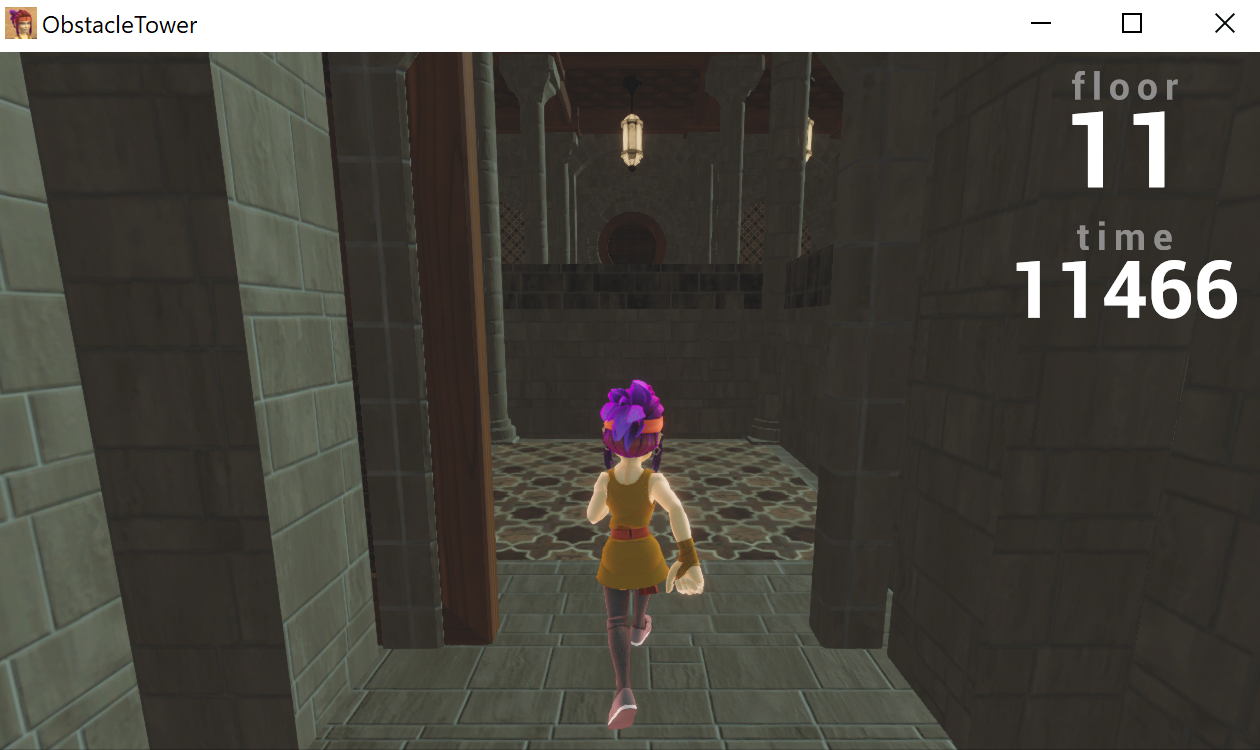

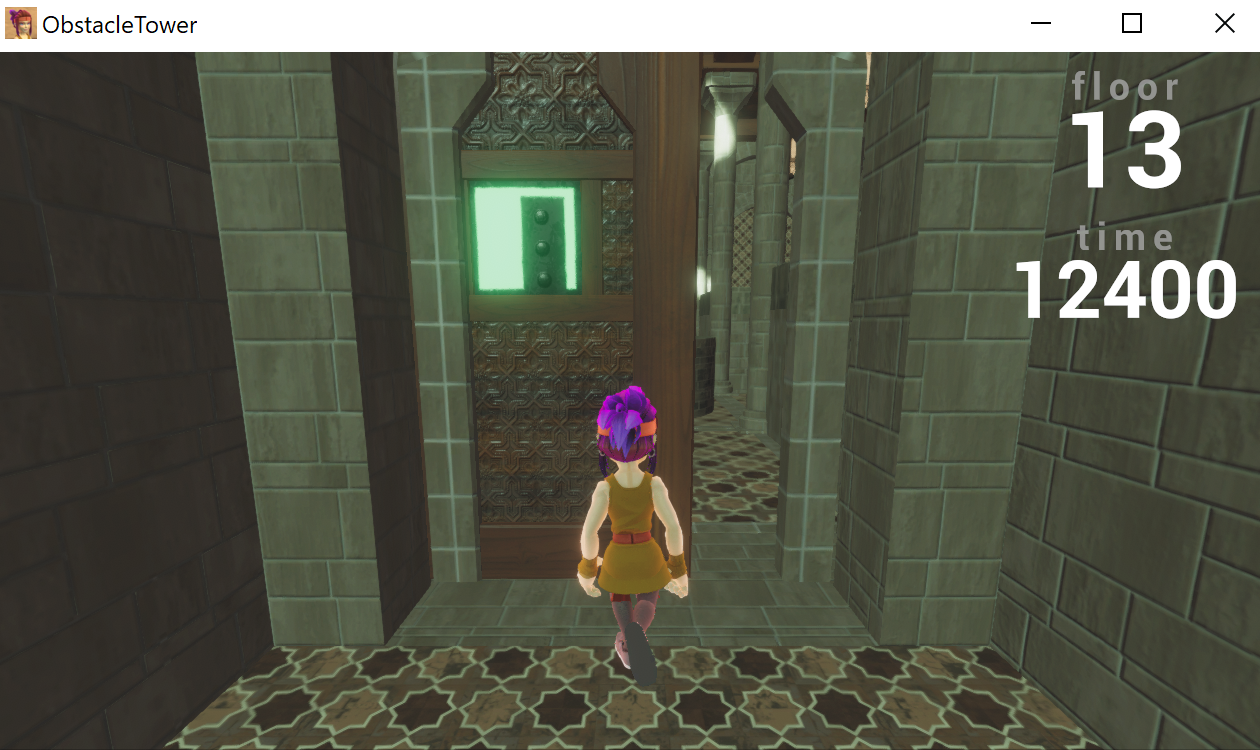


One of the exciting features of this environment is how nondeterministic it is. Every level and room is procedurally generated, along with variations on textures, lighting conditions, and object geometry. Thus, to train an agent that performs well in different levels, the agent must learn to generalize for different visuals and different floor structures.
I have sampled a picture from each floor of a single playthrough. The floors look similar to the human eye, but the color and theme variations could be quite misleading to the convolutional neural network (CNN).
Doors
There are four types of doors in the game:
- a normal door that leads to the next room,
- a locked door, and
- a puzzle door, and
- the door that leads to the next floor.
Opening a door give a reward of 0.1 if the dense reward function is used, and 0 if the sparse reward function is used.
Normal Door


Normal doors have green symbols, and they can opened simply by touching it. Note that the door’s design changes with the theme of the floor.
Locked Door


Locked doors have red symbols, and can only be opened if the player has a “key.” (see description below). By consuming a key, the player permanently unlocks the door.
Puzzle Door
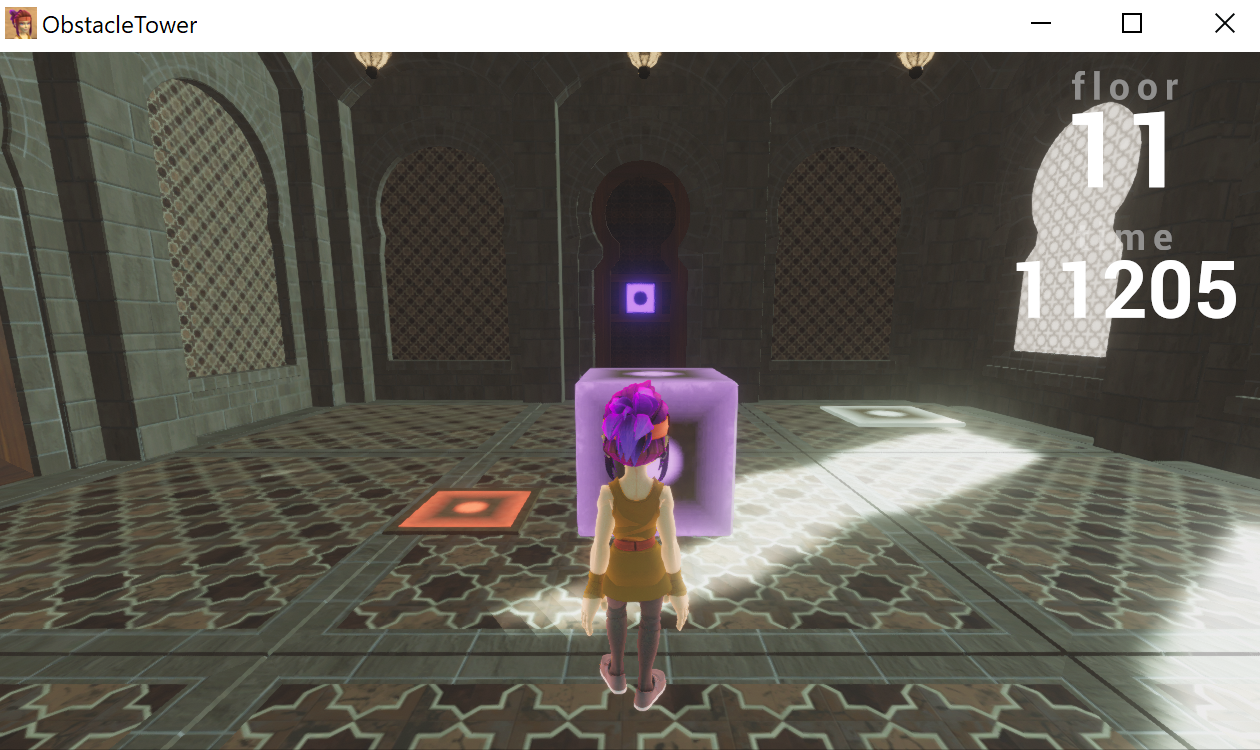
Puzzle doors have purple symbols, and they are locked until the user completes the “puzzle room” (see description below).
Next Floor Door


Next floor doors have yellow arrow symbols, and can be opened simply by touching. Upon entering this door, the episode terminates, and a new episode begins with newly generated floor.
Objects
Time Orb

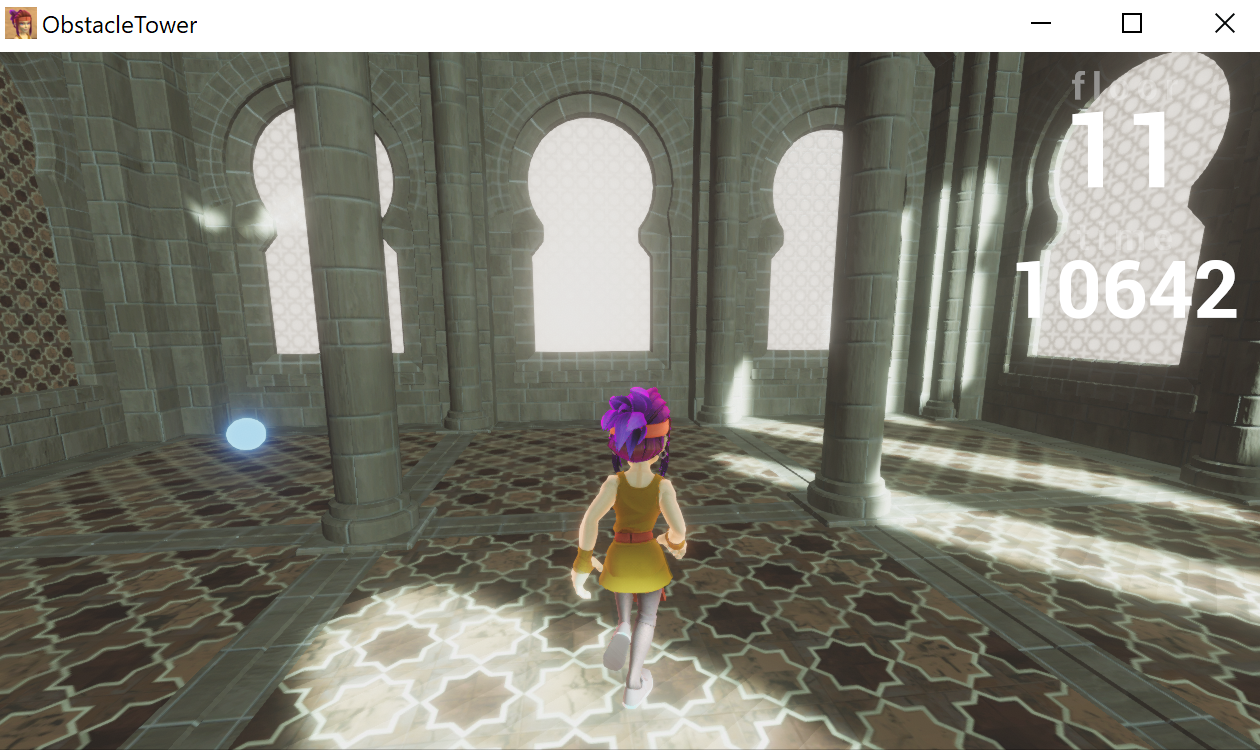
In some rooms, there are blue glowing orbs. Upon running into these orbs, the players’ countdown timer increases by 500. There are often rooms with multiple time orbs.
Key

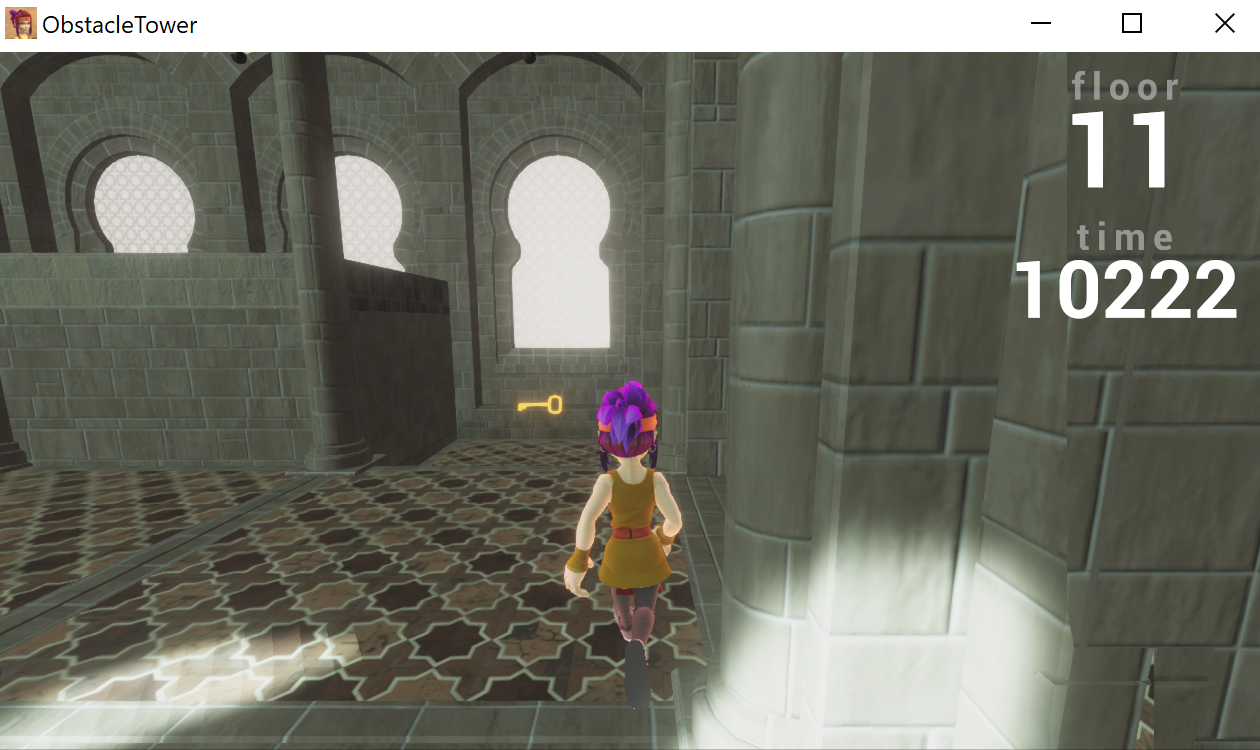
Keys are yellow key-shaped objects that the player can pick up. It is used to open “locked doors” (see description above). After opening a locked door, the key vanishes.


When you pick up a key, a key symbol appears in the top of your screen.
Puzzle Room
Sokoban

The Sokoban room requires the player to push a purple box onto a white plate. If the players wants to reset the Sokoban puzzle, moving to the red plate resets the puzzle. Upon completing the puzzle, the Sokoban door opens.
Miscellaneous
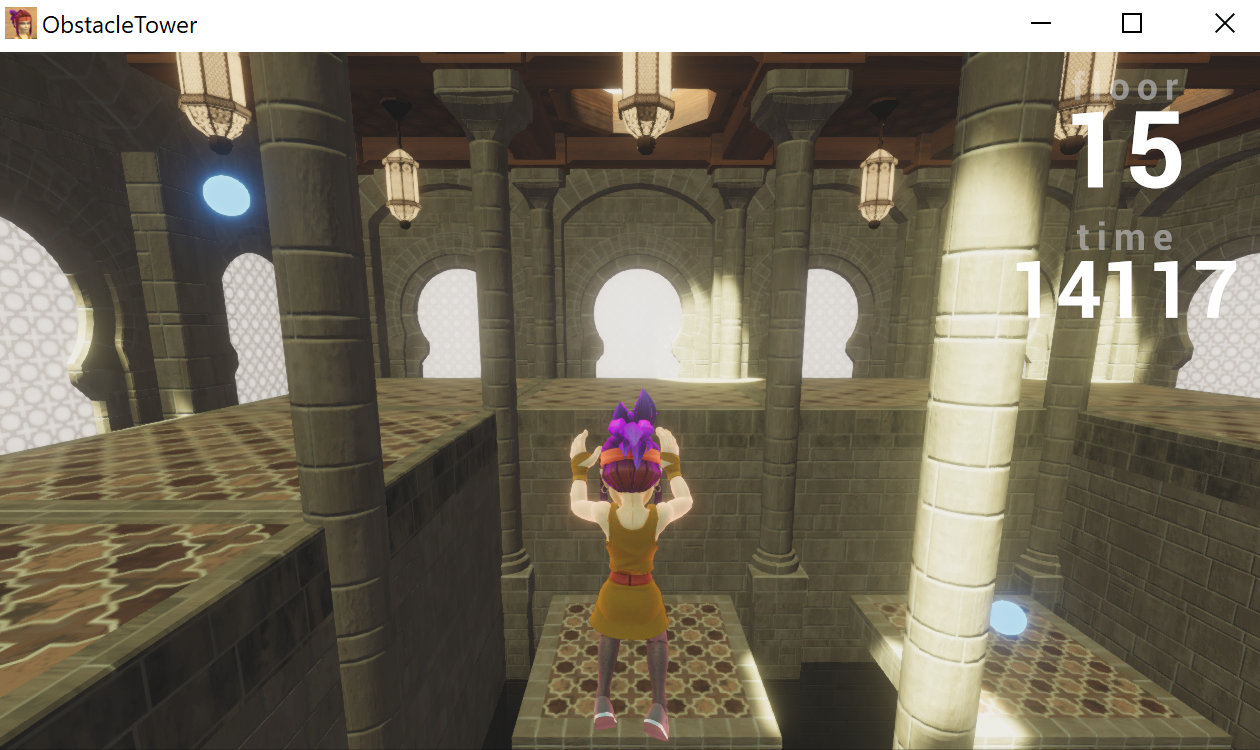
Jumping is not necessary in most floors. However, as the episode gets harder, jump becomes necessary.
On the left, we see a key on a cylindrical block. To complete the episode, the key must be collected, which requires jumping twice.
On the right, we see a map with pits. Falling into a pit results in an episode termination, so the player must move around or jump across the pits.
Conclusion
After playing the game for just 5-10 minutes, I came up with many ideas that could dramatically reduce the training time of the agent. I highly recommend others also interested in this environment to play the game themselves.
From my playthrough, a few things became clear to me:
- Not all 54 actions are needed.
- Extracting features from raw visual input would be harder than Montezuma’s Revenge for CNNs.
- Distilling game knowledge is essential. (ex. Hierarchical Reinforcement Learning)
What’s Next?
Now that I played the game myself, I should now check how the agent would see and play the game. In the next post, I will check the observation space and the action space of the agent. Afterwards, I will run a simple baseline agent and discuss possible improvements to this baseline agents, listing some noteworthy papers.