The Obstacle Tower paper used two baseline algorithms to demonstrate the difficulty of the environment. In this post, we briefly introduce these two algorithms - Rainbow and PPO - and their implementations.
Rainbow
Google Dopamine
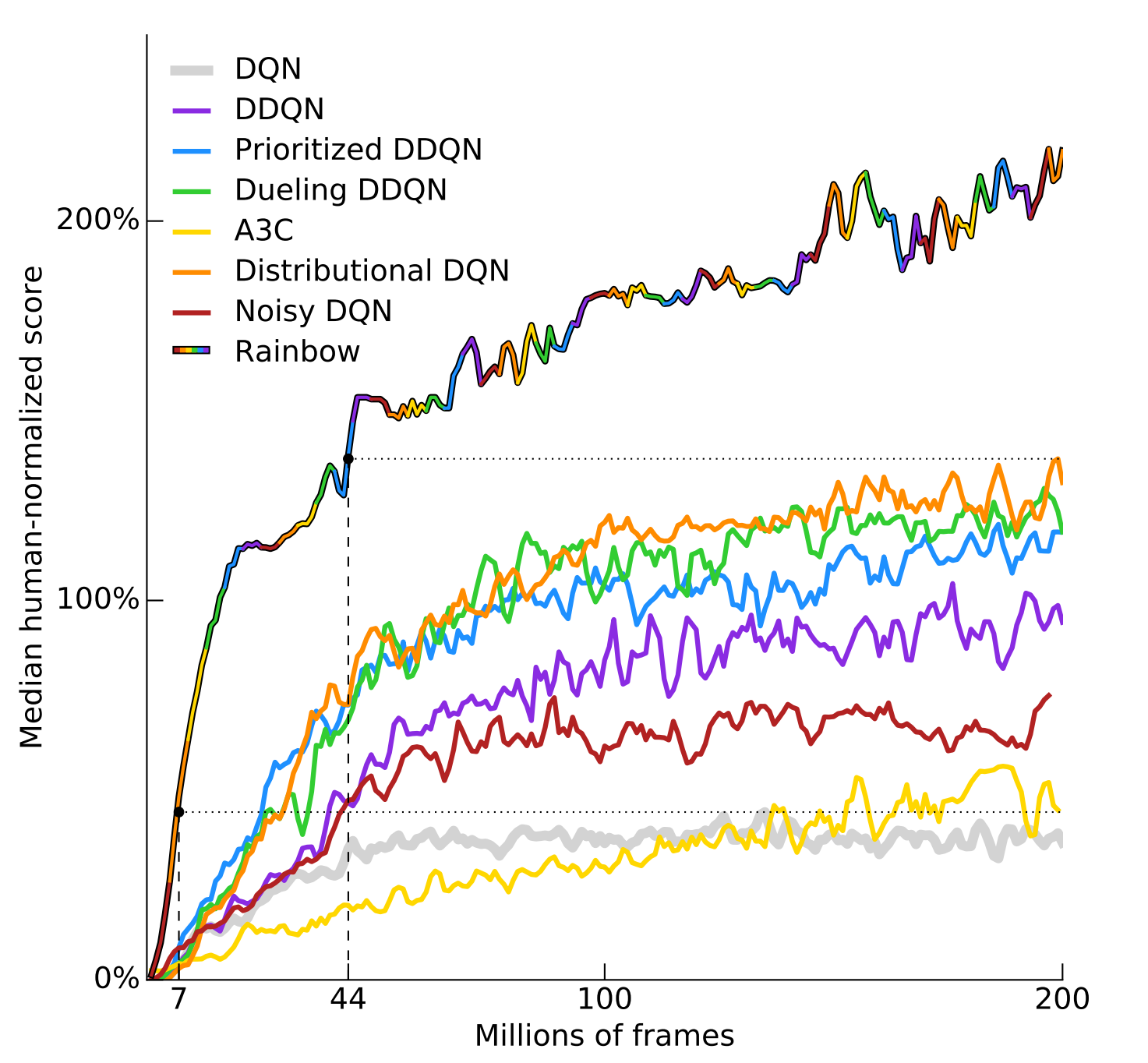
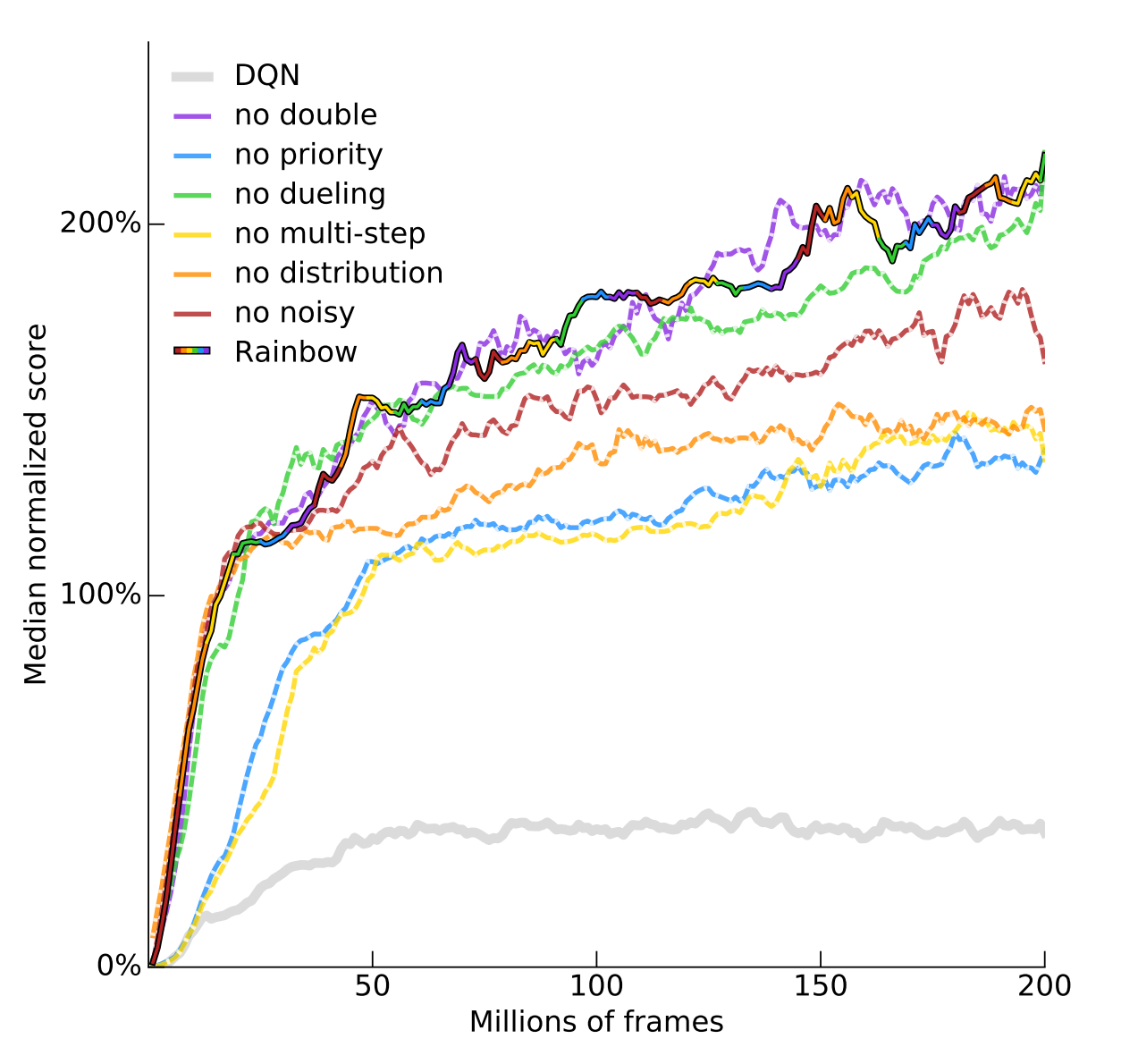
Rainbow Algorithm
Rainbow is a combination of six extensions of Deep-Q Networks (DQN). The chief contribution of the Rainbow paper is not a novel algorithm, but an empirical study of these six extensions. The six extensions are as follows:
- Double DQN (DDQN)
- Prioritized DQN (PER)
- Dueling DQN
- Distributional DQN
- Noisy DQN (NoisyNet)
- n-step Bellman updates
The graph on the left shows that combining all six extensions to DQN results indeed improves the performance greatly. However, it is uncertain how complementary each improvement is: do some of them solve the same problem? To answer the question, the authors performed an ablation study of each improvement. An ablation study is a study where some feature of the algorithm is taken out to see how it affects performance. As shown in the graph, removing some improvements have very little adverse impact.
Rainbow Implementation
The Rainbow baseline in Obstacle Tower uses the implementation by Google Brain called Dopamine. Dopamine provides a single-GPU “Rainbow” agent implemented with TensorFlow. Note that this “Rainbow” agent only uses three of the six extensions:
- Prioritized DQN
- Distributional DQN
- n-step Bellman updates
In other words, it does not use these three extensions:
- Double DQN
- Dueling DQN
- Noisy DQN
As shown in the ablation study graph below, removing Double DQN or Dueling DQN results does not degrade performance, and Noisy DQN only degrades performance a little.
Proximal Policy Optimization (PPO)
OpenAI Baselines
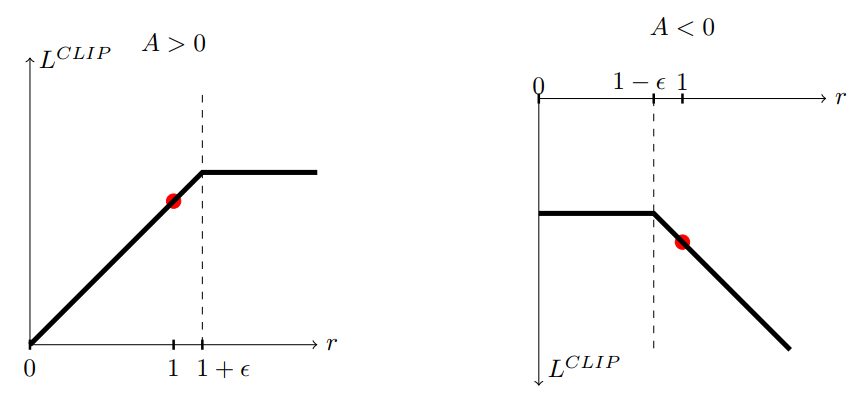
PPO Algorithm
Vanilla policy gradient methods have poor data efficiency and robustness due to overly large policy parameter updates. To counter this update, Schulman et al. developed Trust Region Policy Optimization (TRPO) by restricting updates within the “trust region,” improving data efficiency and robustness.
However, despite its reliable performance, TRPO is difficult to understand and implement. PPO is an algorithm that uses a Clipped Surrogate Objective (or Adaptive KL Penalty Coefficient) to obtain similar efficiency and robustness. Unlike TRPO, PPO only uses first-order optimization.
Note that other common baselines in policy-based methods are TRPO, DDPG, TD3, and SAC.
PPO Implementation
OpenAI Baselines is a popular reinforcement learning algorithms library written in TensorFlow. It includes multiple state of the art algorithms:
- Policy Gradient Methods: TRPO, PPO
- Actor-Critic methods: A2C, ACER, ACKTR
- Deterministic Policy Gradient methods: DDPG
- Deep Q-Network methods: DQN
- HER
Because PPO (and most algorithms listed above) was invented by researchers at OpenAI, it is a good implementation. However, note that there are some additional improvements in the implementation not written in the original paper. For example, in the paper, the clipping parameter $\epsilon$ is fixed, but it is set to decay in the implementation.
What’s Next?
The Obstacle Tower paper showed that vanilla Rainbow and PPO is not enough to solve Obstacle Tower, and listed some potential fruitful areas of research. In the next post, we will take a brief look at each area.