NOTE. This stub post is for my lab teammates. It will be populated after posts 3 and 4 is published.
The Unity team used Rainbow and PPO agents to test their environments. Although they did not perform any hyperparameter tuning, the team made it clear that neither vanilla Rainbow nor vanilla PPO can solve the 25-floor environment.
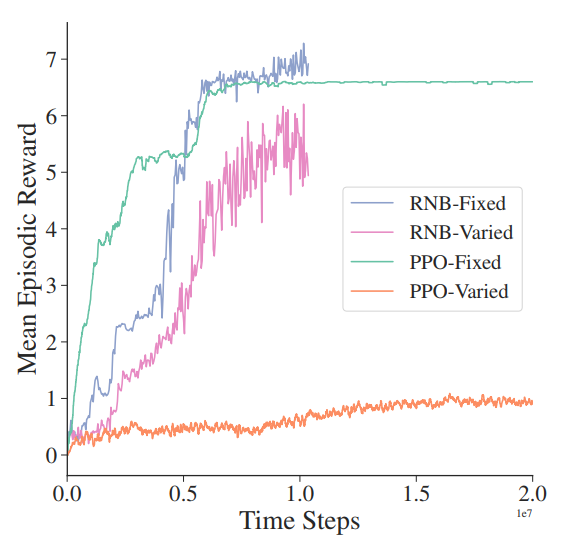
Fortunately, they also listed some possible methods that have high potential to improve the score. In this post, you will understand the central idea of each of these methods.
Hierarchy
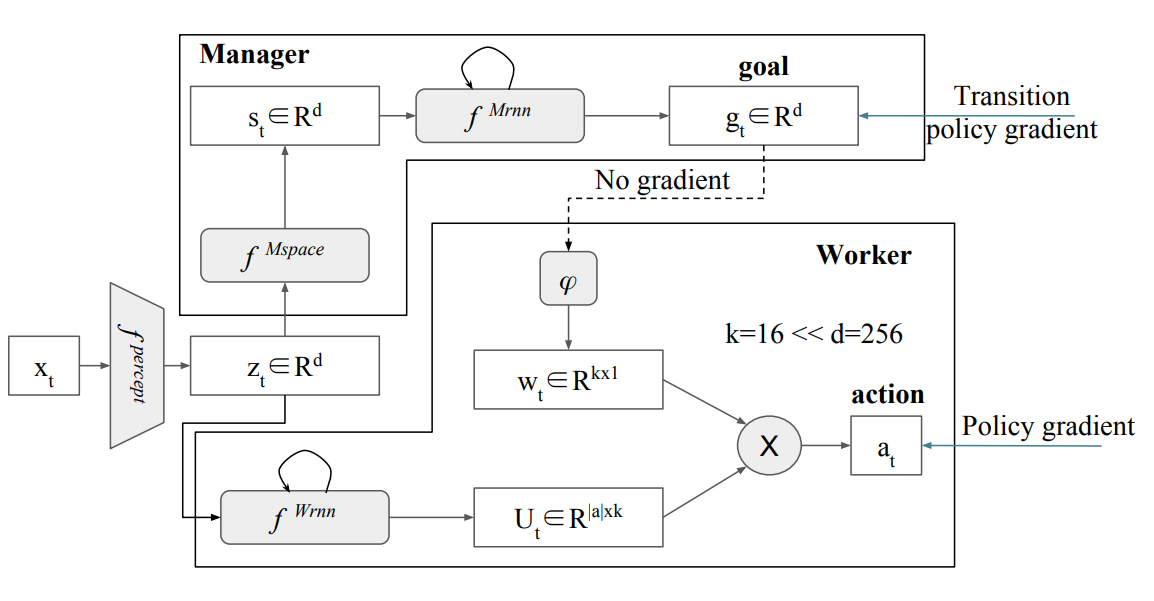
FuN
FeUdal Networks for Hierarchical Reinforcement Learning
HIRO
Data-Efficient Hierarchical Reinforcement Learning

Intrinsic Motivation
We did not include Brute by Machado et al. and Go-Explore by Ecoffet et al., as they need to exploit determinism of the training environment.
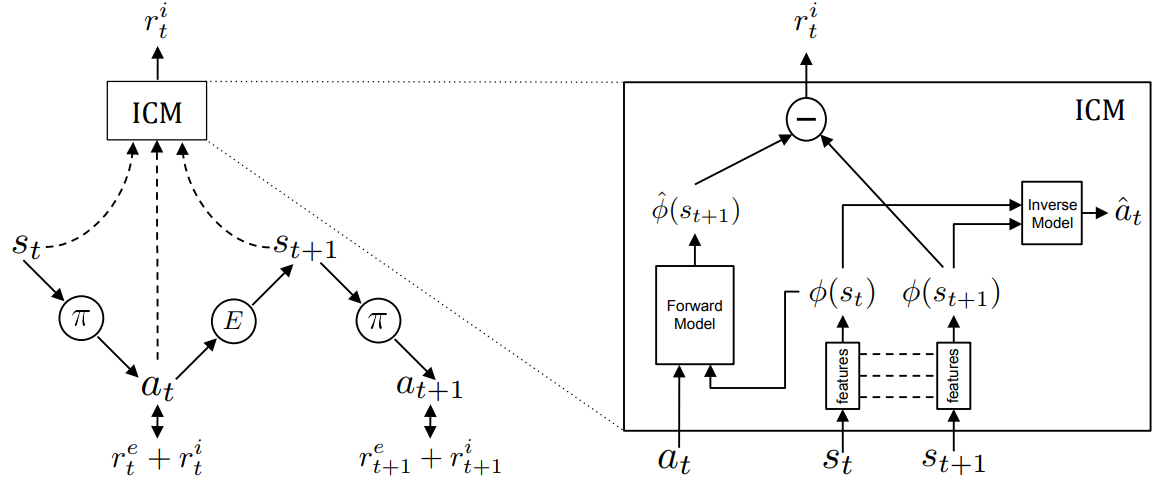
ICM
Curiosity-driven Exploration by Self-supervised Prediction
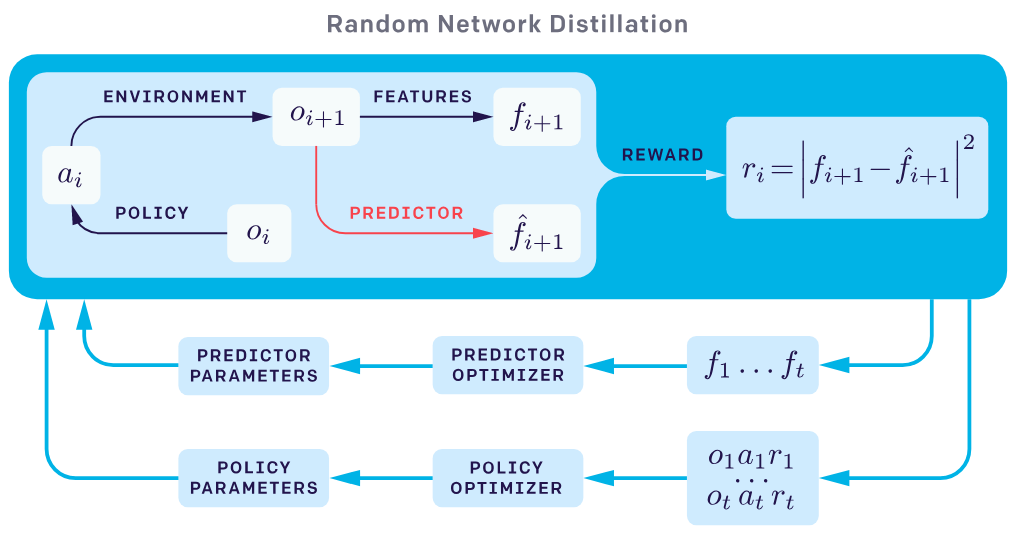
RND
Exploration by Random Network Distillation
CTS
Unifying Count-Based Exploration and Intrinsic Motivation
PixelCNN
Count-Based Exploration with Neural Density Models
Empowerment
Variational Information Maximisation for Intrinsically Motivated Reinforcement Learning
Meta-Learning
MAML
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
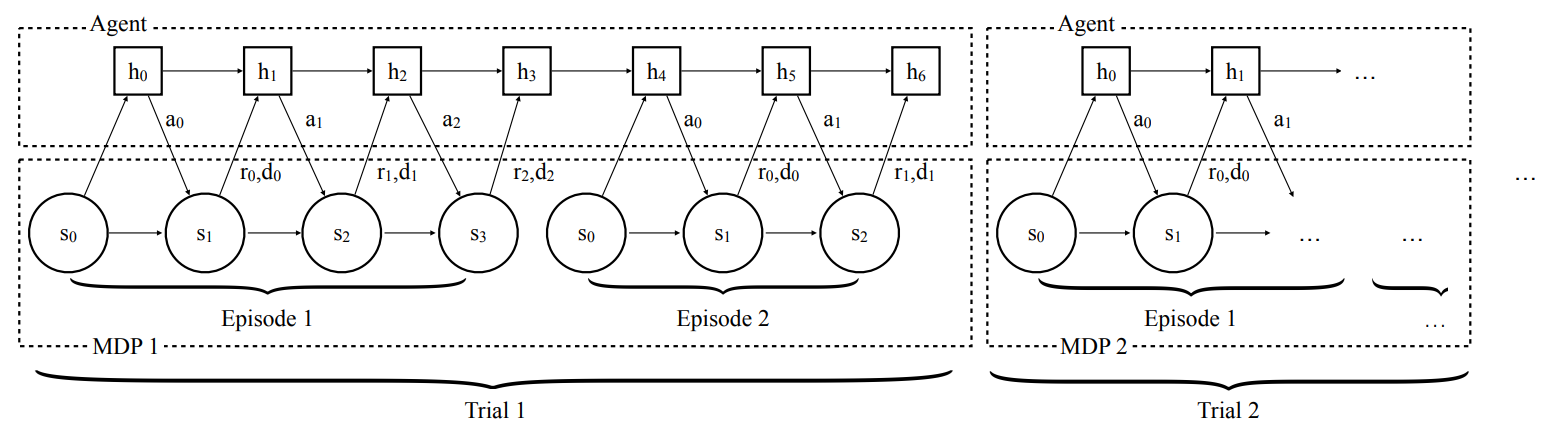
RL^2
Fast Reinforcement Learning via Slow Reinforcement Learning
Model Learning
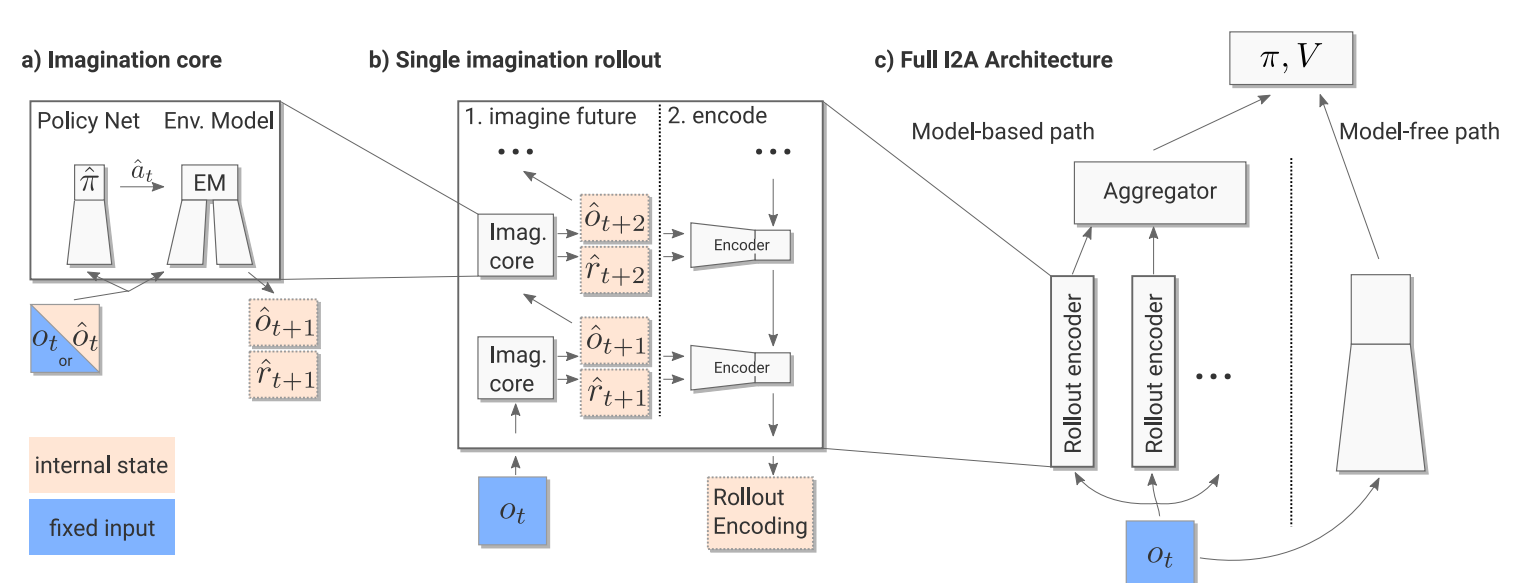
I2A
Imagination-Augmented Agents for Deep Reinforcement Learning
World Model
World Models
