End-to-End Robotic RL without Reward Engineering
What it is
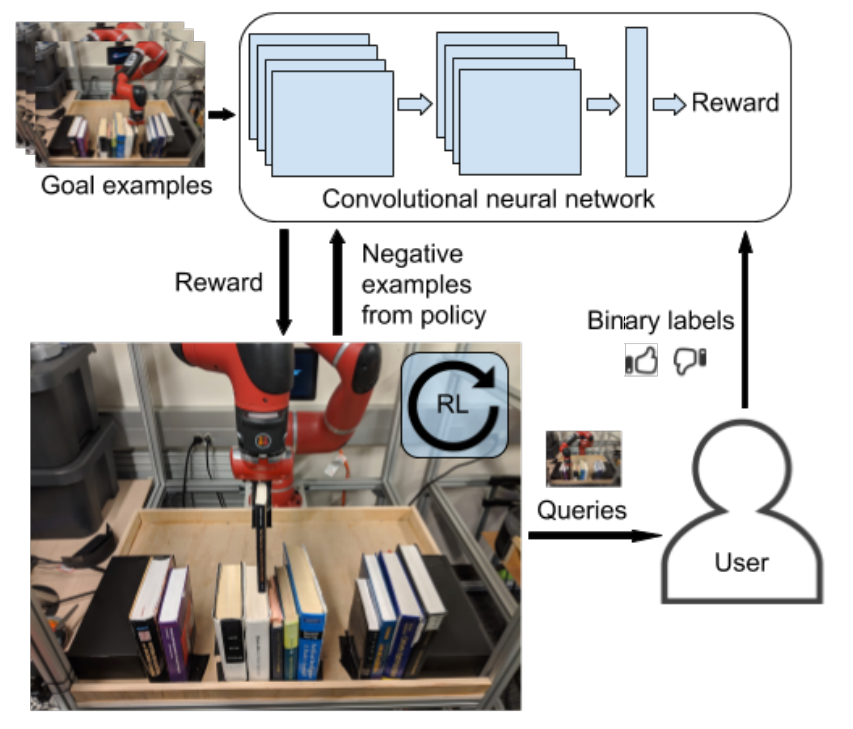
Researchers at UC Berkeley proposed VICE-RAQ, a learning algorithm that replaces the need for rewards with a number of goal examples and active binary feedback from humans during training. This algorithm is an improvement to Variational Inverse Control with Events (VICE), where a neural network classifier is trained with dataset of goal examples given and bad examples generated by the policy currently being trained. The proposed Reinforcement Learning with Active Queries (RAQ) method allows the agent to seldom ask humans whether its attempt was a success or a failure. With their extension to off-policy, VICE-RAQ with Soft Actor Critic can successfully learn various robot manipulation tasks.
Why it matters
Reinforcement learning algorithms are designed to maximize cumulative reward, so the reward signal is a crucial part of reinforcement learning. However, in the real world designing a reward function is complicated. First, it is difficult to design a dense reward signal since it is often uncertain what behavior should be rewarded. Also, detecting such behavior is difficult and requires multiple sensors. To give reward when the robot has completed a task, there must be sensors to verify that the robot has indeed completed the task. There have been various classifier-based approaches to replace reward signals with raw images of goal examples, since they require no such sensors. VICE-RAQ offers a method where the human can assist the agent in such situations.
Read more
- End-to-End Robotic Reinforcement Learning without Reward Engineering (ArXiv Preprint)
- End-to-End Robotic Reinforcement Learning without Reward Engineering (Google Sites)
- End-to-End Robotic Reinforcement Learning without Reward Engineering (YouTube Video)
- avisingh599/reward-learning-rl (GitHub Repo)
External Resources
Extrapolating Beyond Suboptimal Demonstrations
What it is
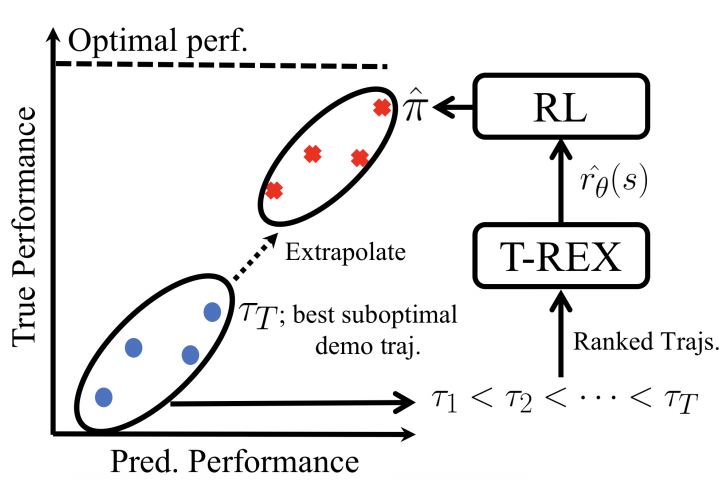
Researchers at UT Austin and Preferred Networks developed a new inverse RL (IRL) method that can significantly outperform the demonstrator. Their new algorithm, Trajectory-ranked Reward EXtrapolation (T-REX), requires a ranked list of demonstrations. With these ranked demonstrations, T-REX trains the reward function with a loss function that signals that demonstrations with better rank should have better total reward. T-REX performs better than existing IRL methods: Behavioral Cloning with Observations (BCO) and Generative Adversarial Imitation Learning (GAIL).
Note that T-REX can be seen as a type of preference-based inverse RL (PBIRL).
Why it matters
Collecting demonstrations is difficult, as it requires an expert playing on the same reinforcement learning environment. Yet, there is no guarantee that they will be perfect, as various factors such as reaction speed or human error is possible. Thus, it might not be beneficial for the agent to similar “imitate” every human action. T-REX attempts to learn from suboptimal demonstrations through preference-based inverse RL, and shows its capabilities with results in various Atari and MuJoCo domains.
Read more
External Resources
- Behavioral Cloning from Observation (ArXiv Preprint)
- Generative Adversarial Imitation Learning (ArXiv Preprint)
- A Survey of Preference-Based Reinforcement Learning Methods (JMLR)
Some more exciting news in RL:
- OpenAI Five Arena is almost over! OpenAI Five currently has 4394 wins and 41 losses, with one team managing to defeat OpenAI Five 10 times in a row.
- u/Kuvster98 shared a simple demo of a trained RL agent landing a simulated rocket.
- Curt Park open-sourced Rainbow-IQN.