How DeepMind tuned AlphaGo

What it is
On March 2016, AlphaGo, a Go program developed by DeepMind, won 4 out of 5 matches against Lee Sedol, an 18-time world champion. This version of AlphaGo had two stages: neural network training, and game playing with Monte Carlo Tree Search (MCTS). Large number of hyperparameters were used in both stages.
Instead of using commonly known methods such as grid search, researchers at DeepMind used Bayesian optimization to meta-optimize many MCTS components. For example, one such MCTS component tuned was the exploration constant of the UCT exploration formula.
The effects of Bayesian Optimization hyperparameter tuning was measured through win rates in self-play. Tuning MCTS hyperparameters resulted in 14.4% increase in win rate (50% to 64.4%) Bayesian optimization was also used in tuning hyperparameter for various tasks: hyperparameters for self-play games with reduced search time, for distributed implementation, for mixing rollout and value network, and for time allocation formula.
Why it matters
A traditional way to tune hyperparameters is a systematic grid search. Unfortunately, this is often impractical when the algorithm has many hyperparameters. In fact, the motivation for Bayesian Optimization was the high cost of systematic grid search: it would take 8.3 days using 400 GPUs to optimize 6 hyperparameters, each taking 5 possible values.
A less robust hyperparameter tuning method would be element-wise hand-tuning, changing one hyperparameter value at a time while keeping others constant. However, hyperparameters are often correlated, so optimal hyperparameters might not be attainable via element-wise hand-tuning for some initial set of hyperparameters.
The Bayesian Optimization approach is a promising method to tune models with many hyperparameters. Since many new reinforcement learning algorithms (ex. Twin Delayed DDPG) suffer from sensitive hyperparameters, perhaps future work will experiment Bayesian optimization in such algorithms.
It is also noteworthy that this improved hyperparameter search results in an algorithmic improvement. Through tuning, researchers at DeepMind found that Bayesian optimization increasingly preferred value network estimates over rollout estimates. This triggered the decision to abandon rollout estimates in future versions of AlphaGo and AlphaGo Zero.
Read more
External Resources
- Bayesian Optimization (Martin Krasser’s Post)
- Nevergrad: An open source tool for derivative-free optimization (Facebook Code Post)
Hierarchical Macro Strategy Model for MOBA Game AI
What it is
Researchers at Tencent AI Lab developed a hierarchical multi-agent AI that achieved 48% win-rate against top 1% human player teams in a game called Honour of Kings. Honour of Kings is a MOBA game, similar to Dota 2 that OpenAI Five was developed for.
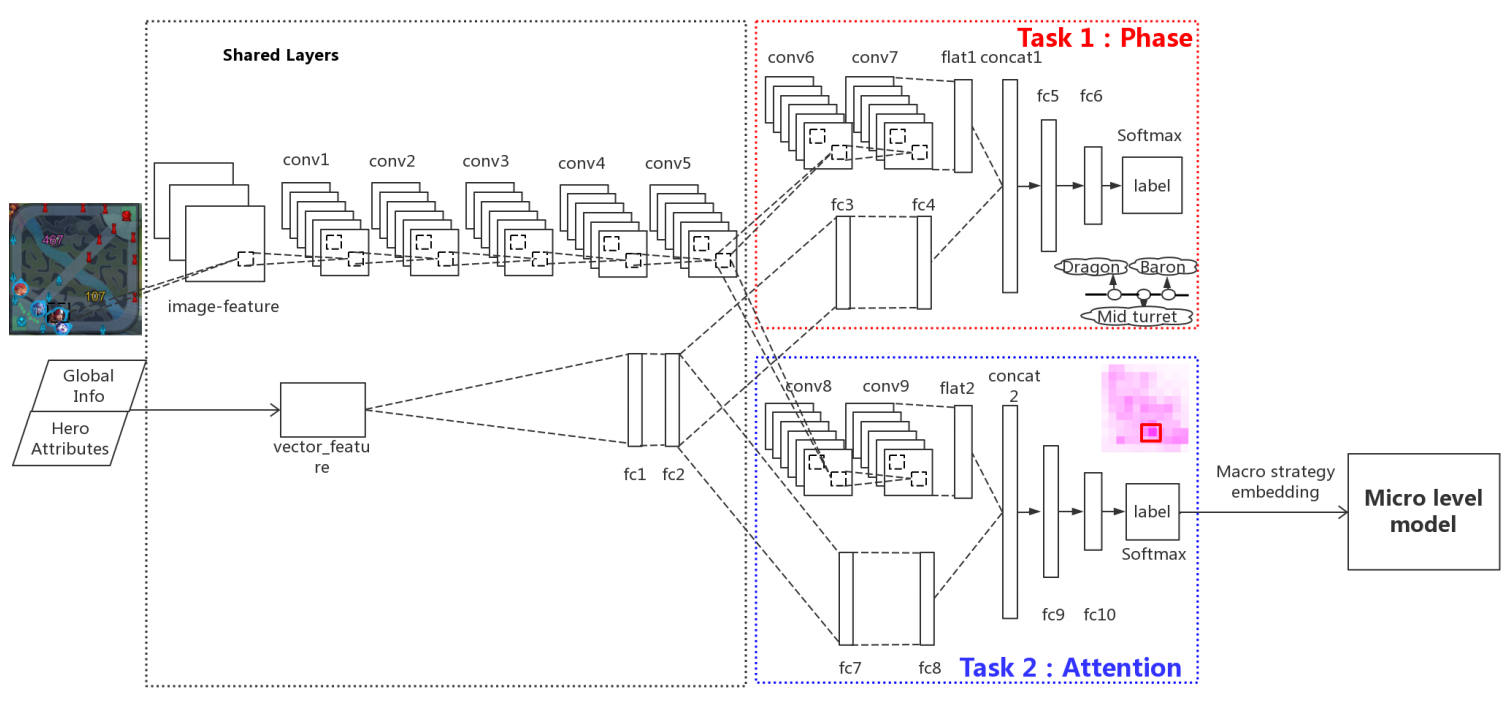
The proposed model is Hierarchical Macro Strategy (HMS) model that acts as high level guidance for micro-level model. HMS consists of two layers: Phase layer and Attention layer. The Phase layer recognizes the current phase of the game by checking major resources of the game. The Attention layer predicts the best region to move to. The output of the attention layer is a macro strategy embedding that is fed to the micro-level model.
Why it matters
MOBA games like Honour of Kings are difficult for reinforcement learning agents due to several reasons. First, one episode is about 20 minutes long, which is equivalent to about 20000 frames. These games also have high-dimensional continuous action spaces.
OpenAI Five’s approach to this MOBA game was scale: it used 128000 CPU cores and 256 P100 GPUs, effectively collecting 180 years of experience per day for each hero.
RL researchers (including ourselves) have generally believed that long time horizons would require fundamentally new advances, such as hierarchical reinforcement learning. Our results suggest that we haven’t been giving today’s algorithms enough credit — at least when they’re run at sufficient scale and with a reasonable way of exploring.
Compared to OpenAI Five, the scale of HMS is much more reproducible: 12 hours on 8 GPUs. Although a direct comparison is impossible due to the difference in the game and the opponents, this research shows the power of hierarchical reinforcement learning in difficult environments.
Read more
External Resources
Sim-to-Real via Sim-to-Sim using cGAN
What it is
Researchers at X, Google Brain, and DeepMind developed a method named Randomized-to-Canonical Adaptation Networks (RCAN) that outperforms previous state-of-the-art system using less than 1% of the real world data.
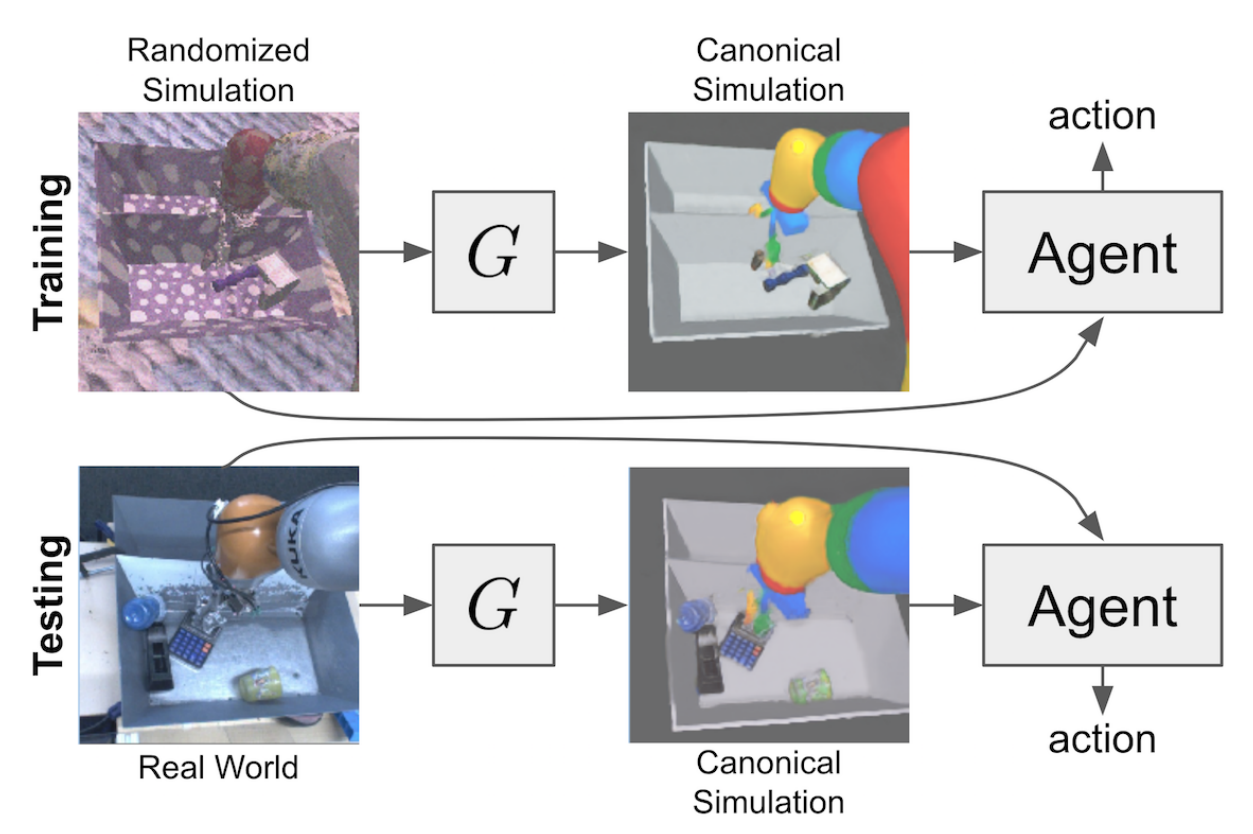
The Randomized-to-Canonical Adaption Networks (RCAN) uses image-conditioned generative adversarial network (cGAN). The goal of this cGAN is to transform real-world images to images similar to the simulation environment. The output of the cGAN is an image from the “canonical” simulation, where no randomization has been performed. The input is an image from the randomized version of the simulation environment. The cGAN thus learns to find relevant parts of the robot and convert them to a clean “canonical” version.
For a grasping task, without any online training in the real world, a robot arm trained with RCAN and QT-Opt has a success rate of 70%, whereas QT-Opt with domain randomization methods have a success rate around 35%. Training with 5000 and 28000 real-world grasps, the success rate increases to 91% and 94%.
Why it matters
Data collection of robotic tasks in real world is incredibly expensive and cumbersome. A human must intervene and initialize the environment at every iteration, and the robot can wear out. Simulations have no such problem: they can be run in parallel without human intervention. However, because simulations are imperfect representations of reality, there exists a “reality gap” between simulation and reality.
There are two popular categories of techniques to reduce this reality gap. Given large amounts of unlabeled data from the real world, it is possible to approximately learn this gap. However, this again requires real world data collection, which is difficult. Another technique is domain randomization, where certain parts (ex. color, texture, shape) of the environment is modified. However, this could make the learning task harder than necessary.
The high success rate of RCAN paired with QT-Opt in grasping task shows a promising future. Reinforcement learning has been restricted mostly to simulated environments due to the sample inefficiency. Dropping two orders of magnitude (1/100) in real world samples is an impressive and exciting progress for sim-to-real research.
Read more
- Sim-to-Real via Sim-to-Sim: Data-efficient Robotic Grasping via Randomized-to-Canonical Adaptation Networks (arXiv paper)
- Randomized-to-Canonical Adaptation Networks (Google Sites)
Lex Friedman interviewed Pieter Abbeel in his AI Podcast! Pieter Abbeel is a professor at UC Berkeley that works on robot control through imitation learning and deep reinforcement learning. You can find the video in YouTube or at Lex Friedman’s website.
ICLR2019 acceptance results are now posted! Browse them at OpenReview.