Credit Assignment as a Proxy for Transfer in Reinforcement Learning
What it says
The “credit assignment” problem is a problem of identifying which actions influenced future rewards, and in what way these actions influenced those rewards. Giving valid credit to the important action is an important part of agent learning to solve the task, but it is difficult to pinpoint them. The authors propose using Transformer, a sequence-to-sequence (seq2seq) model with self-attention, to identify the relations between two state-action pairs. The Transformer is trained through a reward prediction task with partial states and actions given as input. The network must learn reconstruct the missing information from past state-action pairs to predict the reward accurately. (Section 3).
This Transformer network can be used to shape the reward. The shaped reward must follow the “reward shaping theorem” to induce the same optimal policies as the unshaped reward. The authors show that it is possible to formulate a state potential function using the self-attention weights (Section 4).
The authors point at the robustness to task modification as the main advantage of this reward model. Because this model is learned with credit assignment, the model is useful as long as the “causal structure underlying the reward function” remains unmodified. Thus, authors propose transfer learning by augmenting the reward signal of the new environment using this trained reward model (Section 5).
This algorithm is put to test in two environments: the 2D-grid Trigger environment and a 3D keys_doors_puzzle environment. In the Trigger environment, the agent must activate all the triggers to start receiving rewards, and in the Key-Door environment, the agent must get a colored key to unlock a same-colored door. The authors show that their algorithm can assign credit to key actions (activating the trigger or getting the key) very well (Section 6.1, Figure 3).
The algorithm is also tested for transfer learning, and verify that the agents train faster with the augmented rewards in both in-domain transfer (Figure 4) and out-of-domain transfer (Figure 5, 6). The plots show that reward shaping benefits agents in the very early phase of learning.
Read more
Convolutional Reservoir Computing for World Models
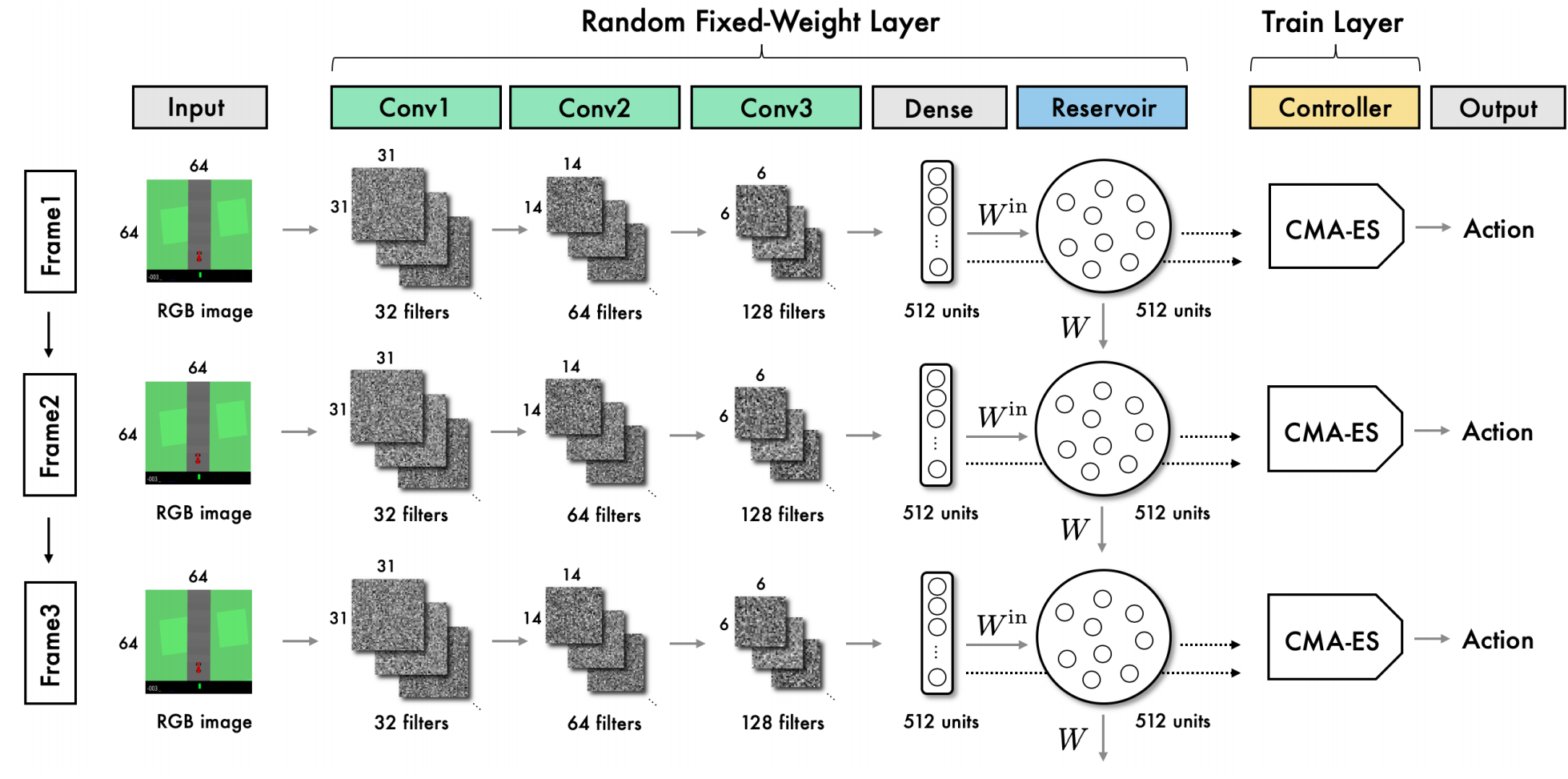
What it says
Feature extraction is an important part of reinforcement learning, especially for environments with large observation space. World model is an algorithm that separates the training of feature extraction model (trained with VAE + MDN-RNN) and the action decision model (trained with CMA-ES), allowing the model to learn features not only to solve the task but to represent the whole environment well. (Section 2.2). The authors propose using “convolutional reservoir computing” to skip the training the feature extraction model and focusing on training the action decision model.
The proposed algorithm “RL with Convolutional Reservoir Computing” (RCRC) is inspired by reservoir computing (Section 2.1). The model uses a randomly initialized convolutional network with fixed weights to extract the features. The features are then given to “ESN”, a reservoir computing model that use a fixed random matrix (Section 3.3). These outputs are given to the controller which is trained with CMA-ES, an evolution algorithm. (Section 3.4).
The authors test RCRC in the CarRacing environment and show that it is competitive to the classical world model controller, although it was slower to reach a stable high score (Section 4.3).
Read more
External resources
One-line introductions to some more exciting news in RL this week
- RLDM2019 Notes: David Abel published his notes for RLDM 2019!
- RAISIM: Jemin Hwangbo relased RAISIM, a physics engine for robotics and AI research!
- MineRL Baselines: ChainerRL released the baselines code for the NeurIPS 2019 MineRL competition!
- Walk Around: The NeurIPS 2019 competition Learn to Move - Walk Around has begun!