Dear readers,
Here is the 32nd issue! In this week's issue, there are two new algorithms that boast state-of-the-art in the Atari environment suite. There are also fascinating new frameworks, especially for robotics.
Meanwhile, I am going to Microsoft Research's Reinforcement Learning Day at New York today. It would be great to meet anyone who is also visiting!
As always, please feel free to email me or leave any feedback.
- Ryan
Off-Policy Actor-Critic with Shared Experience Replay
What it says
V-trace is an importance sampling technique introduced in the IMPALA paper (Espeholt et al., 2018) for off-policy correction. It uses clipped importance sampling ratios which reduces the variance of the estimated return but introduces bias. The authors prove that this is problematic by showing that even when given an optimal value function, V-trace may not converge to a locally optimal policy. The authors suggest mixing on-policy data into the V-trace policy gradient and show that sufficient amount of online data alleviates the problem. (Section 3).
The authors also propose using trust region estimators. Off-policy learning algorithms often use multiple behavior policies to collect experience, and some of them may be unsuitable. Using importance sampling for those behavior policies may result in high or even infinite variance. Thus, the authors define a behavior relevance function and use a trust region scheme to adaptively select only suitable behavior distributions to estimate the value. (Section 4).
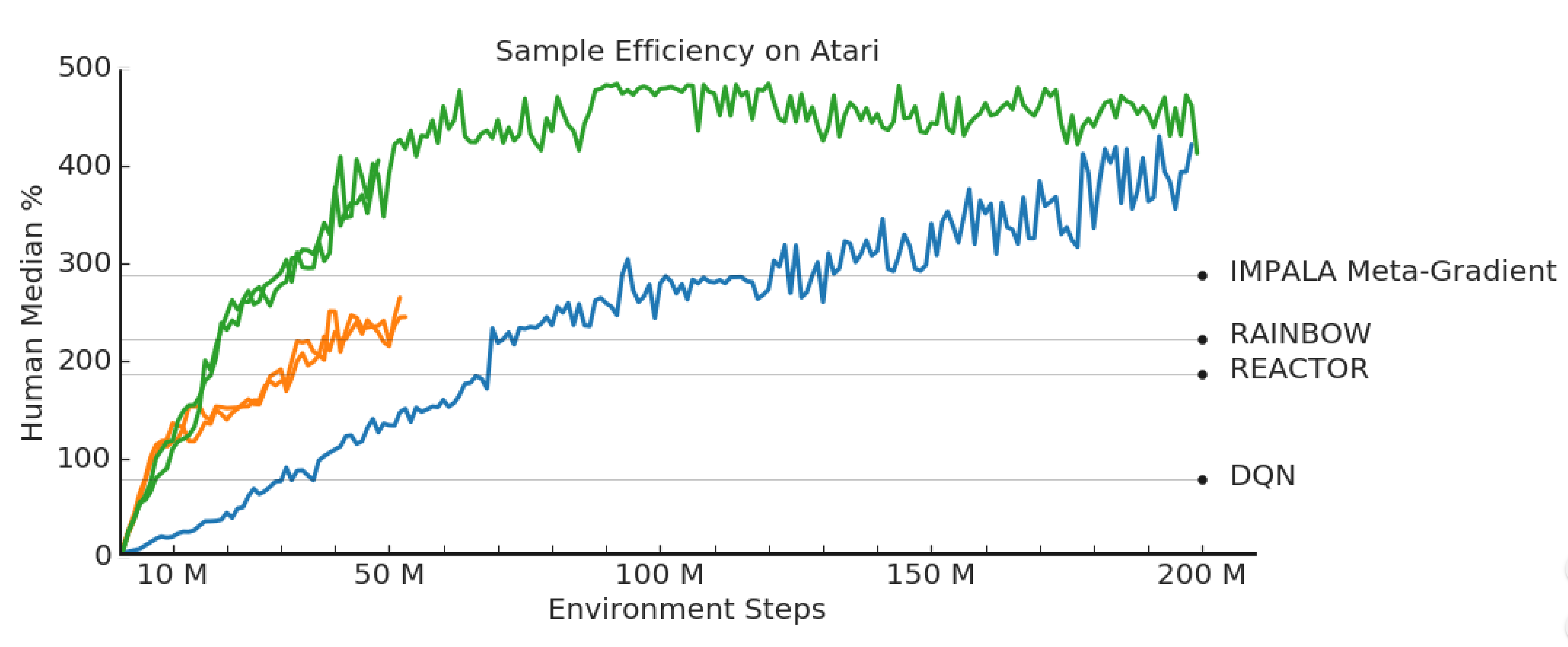
The authors test their algorithm LASER (LArge Scale Experience Replay) on Atari and DMLab-30 and show that it is more sample-efficient than Rainbow, Reactor, and IMPALA Meta-gradient. Interestingly, they show that prioritized experience replay did not meaningfully improve LASER’s performance (Section 5.2).
Read more
External resources
- IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures (arXiv Preprint): Introduced V-trace (Section 4)
- A Deeper Look at Experience Replay (arXiv Preprint): Introduced Combined Experience Replay (DQN) with similar idea.
Why Does Hierarchy (Sometimes) Work So Well in Reinforcement Learning?
What it says
Hierarchical RL (HRL) have been successful in various environments, achieving performance comparable to or better than “shallow” RL that does not use hierarchy. Despite such success, the benefits of HRL is not understood well, and the justification to HRL largely consists of arguments based on intuition.
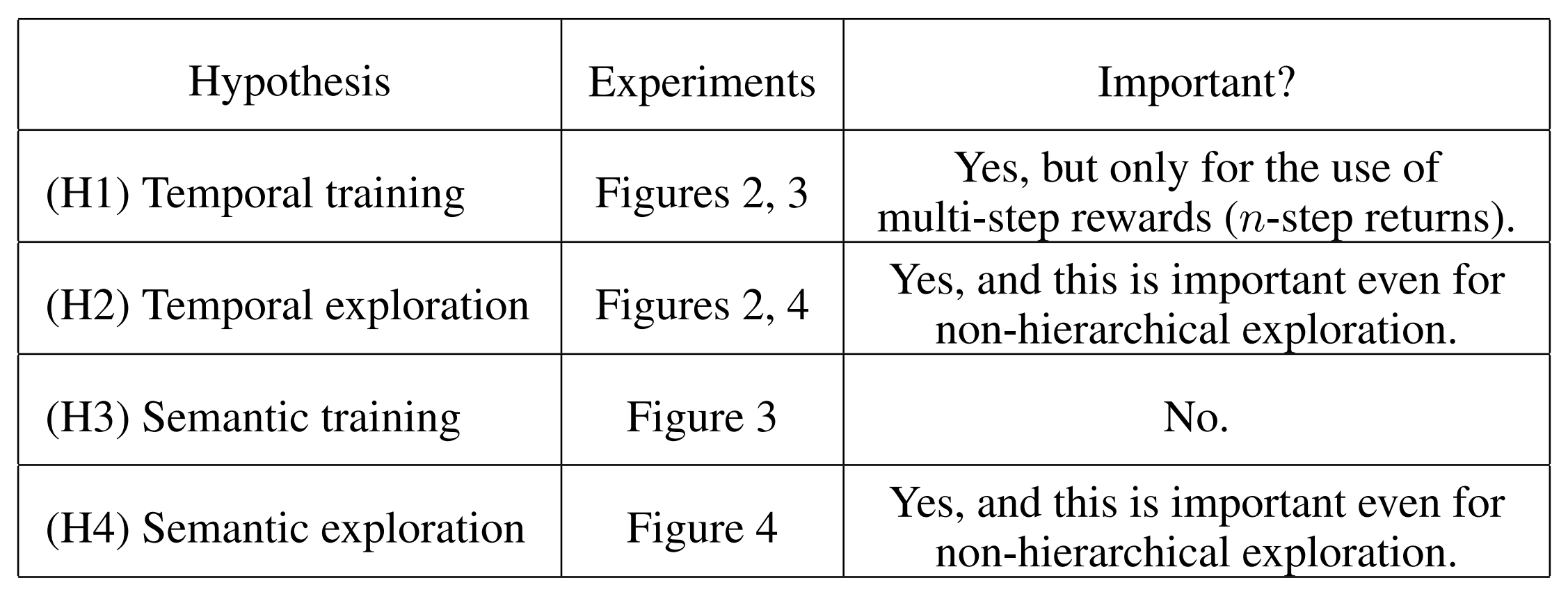
To analyze the benefits of HRL, the authors define 4 hypotheses for the benefits of HRL (shown above) and verify them on 4 simulation tasks of a quadrupedal robot. The results show that although temporally abstract training helps performance, it comes from multi-step rewards, and that the main benefit of HRL comes from exploration.
The authors also test how important it is to have separate high-level and low-level policies (modularity). Experiments show that agents with high-level and low-level policies using the same network with multiple heads performed consistently worse than those with separate networks, showing that modularity is important (Appendix B).
Read more
Here are some more exciting news in RL:
V-MPO: On-Policy Maximum a Posteriori Policy Optimization for Discrete and Continuous Control
An on-policy variant of Maximum a Posteriori Policy Optimization (MPO) that achieves state-of-the-art score in the multi-task setting of Atari-57 and DMLab-30.
Multiagent Evaluation under Incomplete Information
Introduces a multiagent evaluation method that does not assume noise-free game outcomes and with its theoretical guarantees and evaluation results.
Why Does Hierarchy (Sometimes) Work So Well in Reinforcement Learning?
Experimentally determines that hierarchical RL is better than standard RL for learning over temporally extended periods due to improved exploration. Presents two non-hierarchical exploration techniques motivated from hierarchical RL that achieve competitive performance.
RLBench: The Robot Learning Benchmark & Learning Environment
A collection of 100 robot learning tasks built around PyRep with expert algorithms for demonstration generation.
ROBEL: Robotics Benchmarks for Learning with Low-Cost Robots
Open-source platform for affordable RL robots for three-fingered hand robot (dexterous manipulation) and four-legged robot (locomotion).
Avoidance Learning Using Observational Reinforcement Learning
Learn to avoid a bad demonstrator policy to avoid dangerous behaviors through a pseudocount avoidance bonus.
Revisit Policy Optimization in Matrix Form
A Framework for Data-Driven Robotics
Using demonstrations of human teleoperating the robot with some reward annotations, learn a reward model and use it to train an agent with off-policy batch RL.
Leveraging Human Guidance for Deep Reinforcement Learning Tasks
A survey on different methods of using human guidance for reinforcement learning.
Harnessing Structures for Value-Based Planning and Reinforcement Learning Shows that Q-values of many Atari environments have low-rank structures and that recovering and using this structure allows for higher scores with Dueling DQN.