Learning Agile and Dynamic Motor Skills for Legged Robots
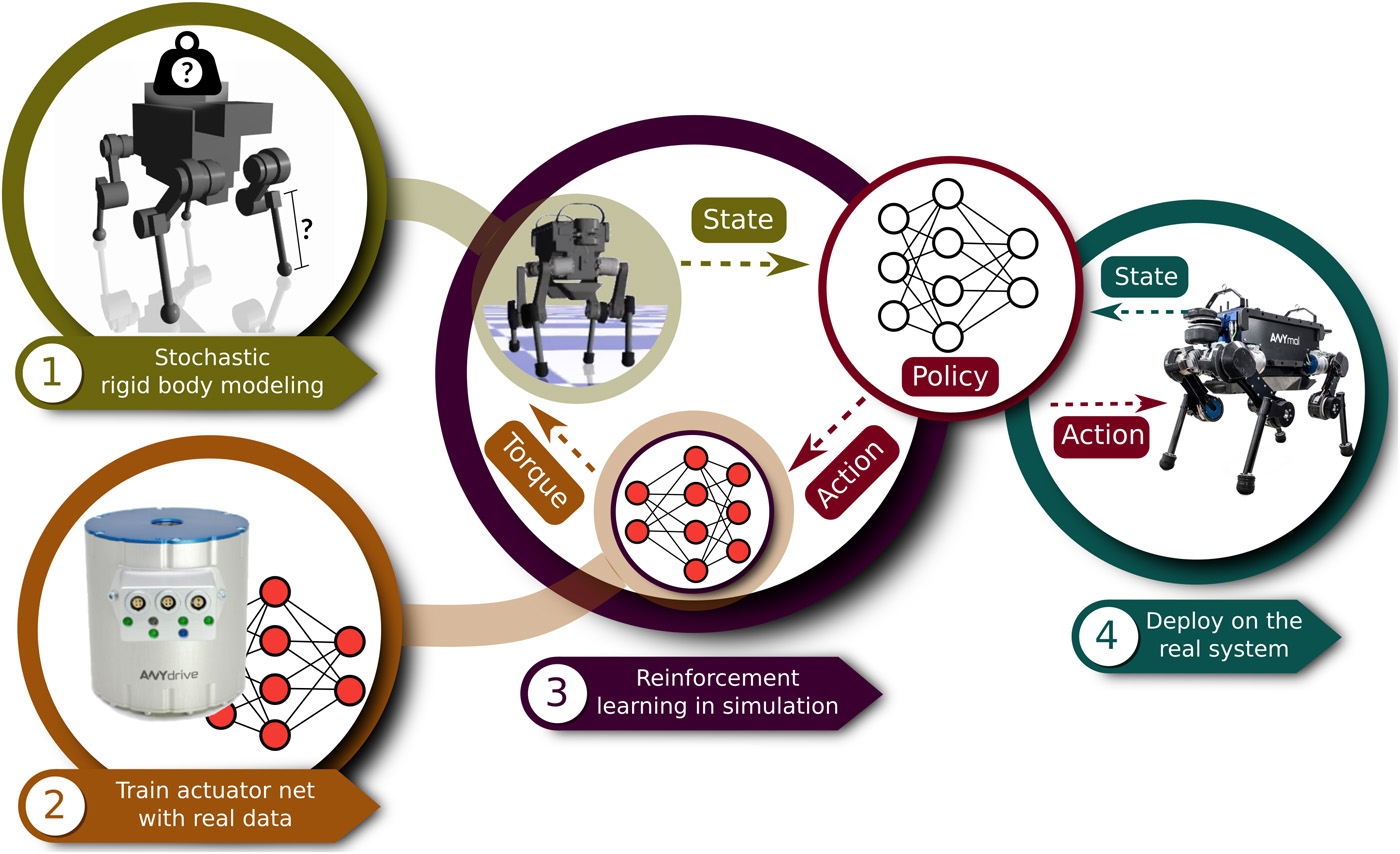
What it is
Researchers at ETH Zurich and Intel showed that deep reinforcement learning methods are capable of training robust policy for a four-legged robot on a simulated environment. To handle simulation inaccuracies from actuator dynamics, joint damping, or signal delays, they propose learning an “actuator network” that maps commanded actions to resulting torques in an end-to-end manner. Thanks to their efficient software implementation, the agent can learn a robust control policy in just 4-11 hours on a normal desktop machine with 1 CPU and GPU. The agent can recover from various fallen positions and maintain balance when kicked.
Why it matters
Previous results of robotic control using reinforcement learning have been disappointing: policies trained with reinforcement learning were neither robust nor data efficient. Thus, some companies have focused on classic control methods instead of reinforcement learning. This result is very impressive in both its efficiency and its robustness. 4-11 hours on a normal desktop machine is a minute amount of computation compared to most reinforcement learning methods (For reference, training a DQN on a single Atari 2600 games would take longer). Furthermore, the trained agent is extremely robust, maintaining balance after being kicked numerous times. We invite the readers to watch the YouTube video in the link below.
Read more
- Learning Agile and Dynamic Motor Skills for Legged Robots (Science Robotics)
- Learning Agile and Dynamic Motor Skills for Legged Robots (PowerPoint slides)
- Learning Agile and Dynamic Motor Skills for Legged Robots (YouTube Video)
External Resources
AutoPhase: Compiler Phase-Ordering with Deep RL
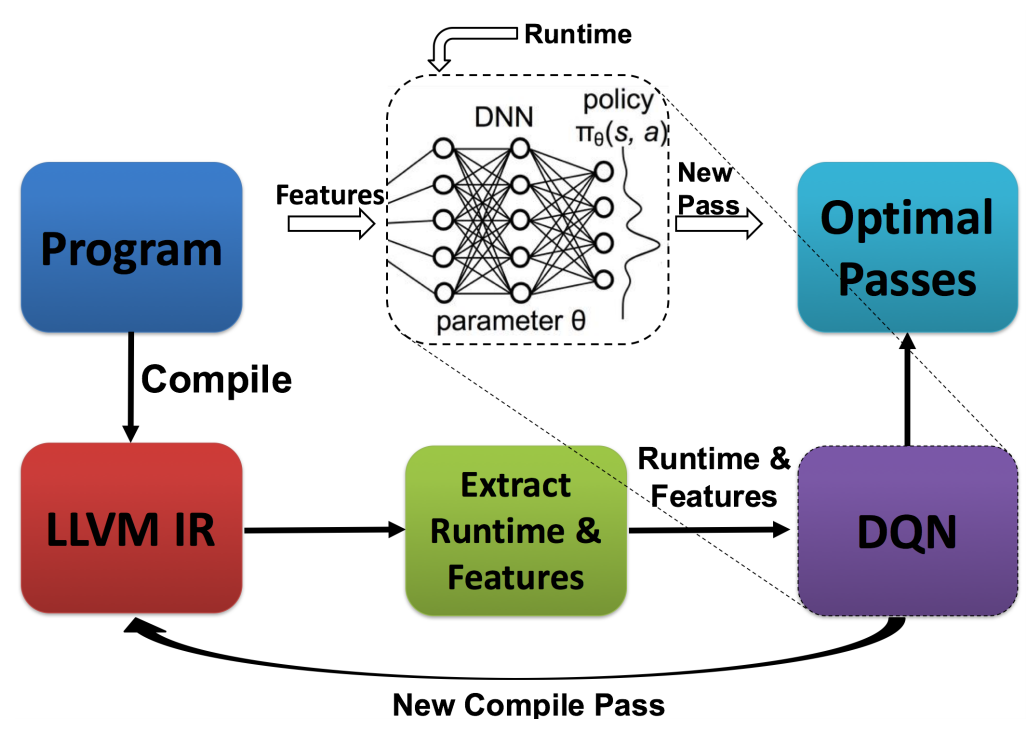
What it is
There are numerous methods for optimizing the compiler. Unfortunately, it is known that the order of optimizations performed significantly impacts the performance. This “phase-ordering problem” is an NP-hard problem, so most existing “solutions” use heuristic search algorithms, with few using machine learning or neuroevolution methods. Instead, researchers at UC Berkeley and MIT propose using deep reinforcement learning algorithm to find a sequence of passes to optimize the performance of these programs. The authors report 16% improvement over -O3 compiler flag while being one or two orders of magnitude faster.
Why it matters
Most previous approaches of compiler phase-ordering problem relied on handcrafted heuristic search. The authors show that using DQN or PG outperforms the traditional -O3 compiler flag and has similar results as genetic algorithms. Because they used “vanilla” reinforcement learning algorithms, we can expect better results with more complex reinforcement learning algorithms. Also, it would be interesting to if similar enhancements would occur for related compiler optimization tasks. Overall, it is exciting to see another possible use case of deep reinforcement learning.
Read more
Go Explore on Sonic the Hedgehog

What it is
Go Explore was presented by Uber last November that showed state of the art performance in hard exploration games given domain knowledge (72543 on Montezuma’s Revenge, 4655 on Pitfall). Unfortunately, Uber has yet to release either a paper or a source code of Go Explore, perhaps due to the amount of community feedback after the blog post. “R-McHenry” (GitHub username) partially implemented this algorithm and test it on Sonic the Hedgehog.
Why it matters
Despite its state of the art performance, Go Explore is still a mystery in large. The author of the code says that “the code is currently a pretty dirty/embarrassing python notebook”, but it is certainly a worthwhile step towards verifying the reproducibility of Go Explore.
Read more
- [D] Go Explore VS Sonic the Hedgehog (Reddit /r/MachineLearning)
- [P] Parallelized Go Explore (Reddit /r/MachineLearning)
- SynchronousGoExplore (GitHub Repository)
External Resources