Obstacle Tower Environment

What it is
Obstacle Tower is a new RL environment created by Unity. In Obstacle Tower, the agent must clear floors with multiple rooms, where each room can contain obstacles, puzzles, and enemies. Both the room layout and the floor plan are procedurally generated, and the visual effects such as texture and lighting are also randomly selected on each floor. Because rewards are only given after completing a floor or a difficult subtask, Obstacle Tower is a sparse-reward environment.
Obstacle Tower is more challenging than existing test suite environments such as Arcade Learning Environment (ALE), MuJoCo, or DeepMind Lab (DM-Lab). Unlike deterministic ALE environments, in this environment the agent must be able to generalize different visual effects and to procedurally generated room layout and floor plans. The agent must also be able to plan for long time horizons and be intrinsically motivated to explore as the environment.
Unity will be launching a competition using the Obstacle Tower environment called the Obstacle Tower Challenge. The challenge will begin a minute after this newsletter is sent, so if you are reading this, the competition has started!
Why it matters
Having a good testbed can enable rapid progress in the field. In reinforcement learning, the Arcade Learning Environment has been the most widely accepted benchmark: environments could easily be installed through OpenAI Gym, and the results could be compared to human performance.
However, due to the rapid progress, most environments in the Arcade Learning Environment have algorithms that can reliably obtain superhuman performance. The Obstacle Tower environment is an effort to create a new test suite that can show both the improvements and the limitations of new algorithms.
Read more
- Obstacle Tower Challenge: Test the limits of intelligence systems (Unity Blog)
- Obstacle Tower Environment (GitHub)
- The Obstacle Tower: A Generalization Challenge in Vision, Control, and Planning (Paper)
External Resources
Hanabi Learning Environment
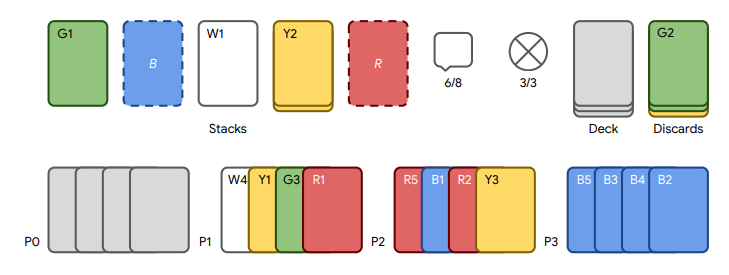
What it is
Hanabi is a cooperative card game for 2 to 5 people. There are five suits (white, yellow, green, blue, red), with each suit having 10 cards with numbers (1, 1, 1, 2, 2, 3, 3, 4, 4, 5). All players are dealt 4 or 5 cards each, and they can see others’ cards but cannot see their own. On each turn, the player can either play a card, discard a card, or give information to another player about that person’s cards. The goal of the game is to cooperatively play the cards in correct order (1, 2, 3, 4, 5) for each suit without playing the wrong cards.
Why it matters
Just like Arcade Learning Environment (ALE) and Obstacle Tower (mentioned above), a good testbed allows for a sophisticated analysis. Most existing RL environments are restricted to single-player games. In contrast, Hanabi is a multi-agent environment which brings unique challenges. To determine the optimal action, the agent must also consider how other agents must behave. (This is different from two-player zero sum games such as Go or Chess, where the agent can achieve a meaningful worst-case guarantee.) Overall, the environment could be an excellent test suite for multi-agent RL algorithms.
Read more
- The Hanabi Challenge: A New Frontier for AI Research (arXiv)
- Hanabi Learning Environment Release (Twitter)
- Hanabi Learning Environment (GitHub)
External Resources
Spinning Up in Deep RL Workshop

What it is
Spinning Up is an educational resource created by OpenAI, primarily by Joshua Achiam. It contains a variety of resources that could be helpful for both beginners and experienced researchers. As part of this project, a workshop was held in San Francisco on February 2nd, 2019. It consisted of 3 hours of lecture and 5 hours of “semi-structured hacking, project-development, and breakout sessions.” The lecture component was streamed live on YouTube. For the first two hours, Joshua Achiam gave an introduction to RL. Then, Matthias Plappert talked about robotics in OpenAI, focusing on learning dexterity. Finally, Dario Amodei gave a talk about AI Safety, focusing on learning from human preferences.
Read more
- Welcome to Spinning Up in Deep RL! (Docs)
- OpenAI - Spinning Up in Deep RL Workshop (YouTube)
- Spinning Up (GitHub)
- Spinning Up Workshop Slides (GitHub)
- Learning Dexterity (OpenAI Blog)
- Learning Dexterity (arXiv)
- Learning from Human Preferences (OpenAI Blog)
- Deep reinforcement learning from human preferences (arXiv)
- Reward learning from human preferences and demonstrations in Atari (arXiv)
Here are some additional news you might be interested in:
- Google released Dopamine 2.0 with compatibility with OpenAI Gym.
- Uber released source code for their Go-Explore.
- Kai Arulkumaran, Antoine Cully, and Julian Togelius analyzed AlphaStar with an evolutionary computation perspective.