The Bitter Lesson
What it is
Richard S. Sutton, one of the founding fathers of modern reinforcement learning, wrote a new blog post titled “The Bitter Lesson.” In the post, he argues that “general methods that leverage computation are ultimately the most effective.” Because the computational resources increase as time passes (Moore’s Law), methods that withstand the challenge of time are ones that scales well and can utilize massive amounts of computation.
Thus, Sutton argues that researchers should be wary of seeking to leverage human knowledge into their research, as it often runs counter to leveraging computation. To further illustrate this, Sutton gives Chess, Go, speech recognition and computer vision as examples. Handcrafted evaluation methods and features were popular on early stages of AI in each of these fields, but today’s state of the art methods with superhuman results have discarded such complex methods. “We want AI agents that can discover like we can, not which contain what we have discovered.”
Why it matters
Reinforcement learning is a blooming field: dozens of labs publish new papers every week, claiming an improvement against previous papers. Many of these papers infuse human priors into their methods. This blog post is a nice reminder to researchers choosing research ideas and readers assessing the impact of research.
Renowned researchers also shared their own thoughts about the blog post, which provide further insight of the topic.
Read more
External Resources
- David Ha’s Response (Twitter Thread)
- Kyunghyun Cho’s Response (Twitter Thread)
- Shimon Whiteson’s Response (Twitter Thread)
- The Bitter Lesson (ML Subreddit)
- “The Bitter Lesson”: Compute Beats Clever (RL Subreddit)
- The Bitter Lesson (Hacker News)
The Promise of Hierarchical Reinforcement Learning
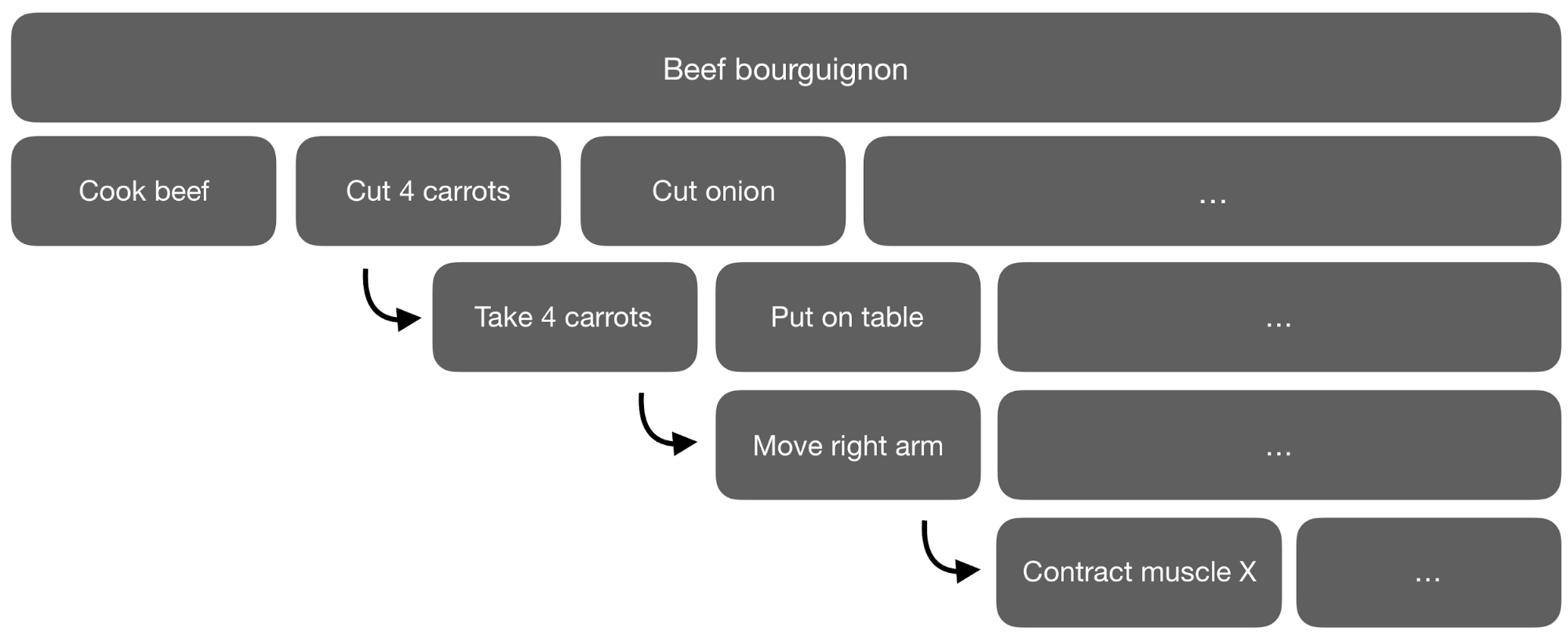
What it is
This post by Flet-Berliac summarizes hierarchical RL (HRL) and introduces recent advances in HRL. Hierchical RL uses a hierarchical structure to break down large problem into multiple small problems, allowing agents to solve problems to complex with “flat” RL. Existing HRL algorithms suffer from several defects, performing worse than “flat” RL algorithms in most settings. Still, HRL shows great promise in specific domains with greater sample efficiency and better generalization.
Read more
External Resources
- FeUdal Networks for Hierarchical Reinforcement Learning (ArXiv Preprint)
- The Option-Critic Architecture (ArXiv Preprint)
- Data-Efficient Hierarchical Reinforcement Learning (Arxiv Preprint)
- Learning Multi-Level Hierarchies with Hindsight (ArXiv Preprint)
- Learning and Transfer of Modulated Locomotor Controllers (ArXiv Preprint)
- On Reinforcement Learning for Full-length Game of StarCraft (ArXiv Preprint)
- Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation (ArXiv Preprint)
- Meta Learning Shared Hierarchies (ArXiv Preprint)
- Strategic Attentive Writer for Learning Macro-Actions (ArXiv Preprint)
- A Deep Hierarchical Approach to Lifelong Learning in Minecraft (ArXiv Preprint)
- Planning with Abstract Markov Decision Processes (AAAI Publications)
- Iterative Hierarchical Optimization for Misspecified Problems (IHOMP) (ArXiv Preprint)
- Learning Goal Embeddings via Self-Play for Hierarchical Reinforcement Learning (ArXiv Preprint)
- Learning Representations in Model-Free Hierarchical Reinforcement Learning (ArXiv Preprint)
Exploration with Human Feedback
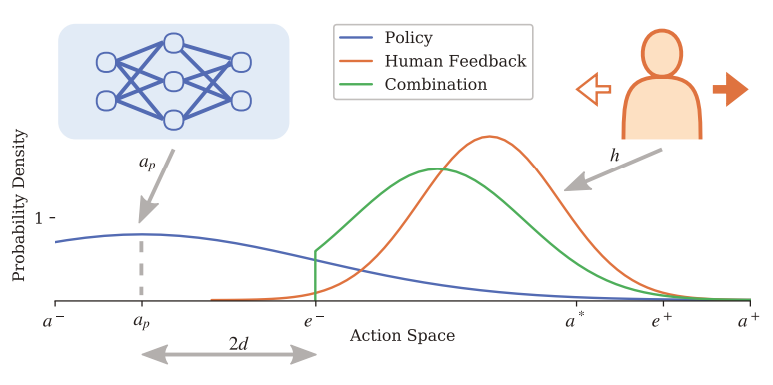
What it is
Researchers at Delft University of Technology developed Probabilistic Merging of Policies (PPMP) as a method to incorporate binary corrective feedback to actor critic algorithms to improve sample efficiency and performance. Environments with simple action space (Pendulum, Mountain Car, and Lunar Lander) is used, and human feedback is selected from three numbers: -1, 0, 1. When the actor’s action deviate a lot from optimal action, PPMP facilitates exploration aggressively, and when the selected action is near optimal, PPMP adds little stochasticity to the action. This allows for a natural curriculum learning setup, and allows the fully trained agent to run independently without human feedback.
Why it matters
Distilling human knowledge can be powerful to the efficiency, performance, and robustness of ML models and RL agents. Imitation learning can work well, but it requires precise trajectories that are hard to obtain. In environments where the action space is simple and optimal action is clear, such feedback-based methods could boost the agent considerably.
Read more
- Deep Reinforcement Learning with Feedback-based Exploration (ArXiv Preprint)
- Predictive Probabilistic Merging of Policies (GitHub Repo)
Some more exciting news in RL:
- DeepMind published a new post on AI safety named “Designing agent incentives to avoid side effects”.
- MicroRTS competition will occur at IEEE Conference on Games (CoG) 2019.