Learning Latent Plans from Play

What it is
“Playing” is crucial to human learning: without a specific goal, babies try different behaviors and strategies and learns about the environment. Motivated by such behavior, researchers at Google Brain and Google X proposed learning from play (LfP) data for multi-task robotic skill learning, collecting the play data by having a human user to teleoperate the robot in a playground environment.
With this unbounded sequence of states and actions called “play data,” the authors introduce Play-LMP (Play-supervised Latent Motor Plans), a hierarchical latent variable model. Play-LMP can learn a “latent plan representation space,” where local regions of the space contain different solutions of the same task, allowing for multitask learning. Without being trained on task-specific data, Quantitatively, Play-LMP generalizes to 18 manipulation tasks with an average success rate of 85.5%, showing better performance than task-specific behavior cloning (BC), Qualitatively, Play-LMP is robust to perturbations and exhibit failure recovery behavior.
Why it matters
Play data can be collected with intrinsic motivated agents, but developing such agent is by itself a difficult problem. By using human teleoperated data as play data, the authors were able to remove the “how to play” part of the question and focus on the “what can be learned from play.” Furthermore, such play data is cheap (minimal setup required), general (not specific to particular task), and rich (covers diverse behaviors). A successful use of play data as a replacement to expensive expert demonstration could enable agents to perform much more challenging tasks.
Read more
- Learning Latent Plans from Play (Interactive Paper)
- Learning Latent Plans from Play (ArXiv Preprint)
External Resources
A Manifesto for Multi-Agent Intelligence Research
What it is
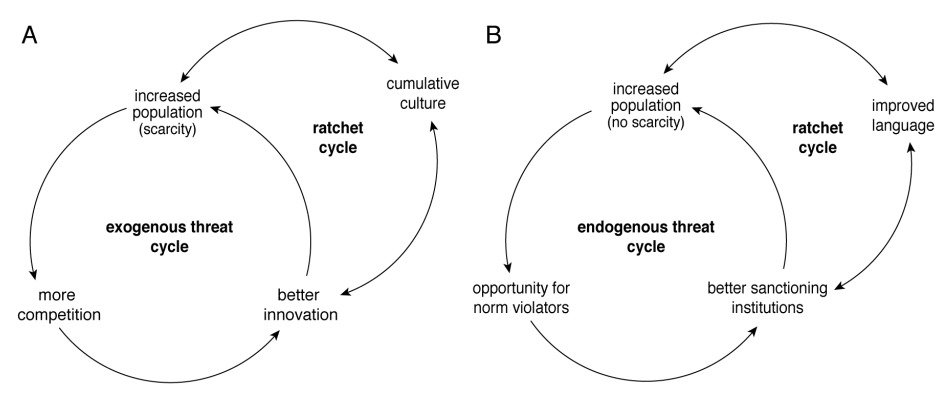
Researchers at DeepMind analyzed the “autocurricula” that emerge in multi-agent settings. The authors argue that in single-agent settings, the agent’s intelligence can only be improved by providing more diverse and complex environments. Such environments is laborsome, and thus it is dubbed the Problem Problem. Instead, in multi-agent settings, a curriculum is generated automatically as the agents are challenged to explore different policies. The authors categorize challenges into two categories: exogenous (external factors) and endogenous (internal factors). Exogenous challenges originate from different agents shifting strategies, changing the game landscape. Endogenous challenges originate from internal changes, which appear because the agent is made up of subunits that compete against each other.
Why it matters
DeepMind has recently released multiple multi-agent RL environments and algorithms, so the paper could be a good introduction to understand the reasoning behind their focus on multi-agent RL.
Read more
External Resources
- AlphaStar: Mastering the Real-Time Strategy Game StarCraft II (DeepMind Blog Post)
- Capture the Flag: the emergence of complex cooperative agents (DeepMind Blog)
- The Hanabi Challenge: A New Frontier for AI Research (ArXiv Preprint)
- Emergent Coordination Through Competition (ArXiv Preprint)
The StreetLearn Environment and Dataset
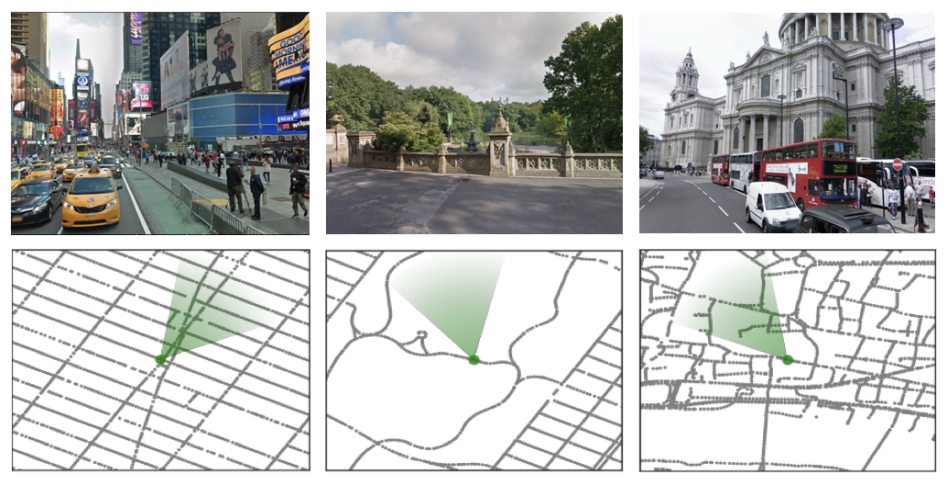
What it is
StreetLearn is a navigation environment developed using Google Street View. The environment provides a standard 84x84 visual observation and five discrete actions: slow rotate left/right, rotate left/right, or move forward. Additionally, StreetLearn provides a “goal descriptor” as an observation, which is a represented with a latitude-longitude coordinates. The agent starts from a randomly sampled position from the map of the NYC and Pittsburgh area and is rewarded when it reaches the goal descriptor successfully, with episode ending after 1000 steps.
Why it matters
Google Street View has high-resolution image data collected worldwide and is a valuable resource for navigation. Long-range navigation is a challenging task that requires good representation of space and good visual processing. Furthermore, as Jack Clark noted, navigation is a basis of many tasks, so a robust navigation algorithm allows agents to perform more complex tasks.
Read more
- The StreetLearn Environment and Dataset (ArXiv Preprint)
- Learning to Navigate in Cities without a Map (Google Sites)
- StreetLearn (GitHub Repo)
External Resources
Some more exciting news in RL:
- TensorFlow showcased early version of TF-Agents, a library for Reinforcement Learning in TensorFlow.
- Researchers at Facebook, LORIA, and UCL developed a new text-based adventure game framework called Learning in Interactive Games with Humans and Text (LIGHT).
- Researchers at Mila, FAIR, Polytechnique Montreal, CIFAR, and Georgia Institute of Technology show that an auxilary loss predicting long-term future helps in faster imitation learning, better model planning, and better performance.