Benchmarking Model-based Reinforcement Learning
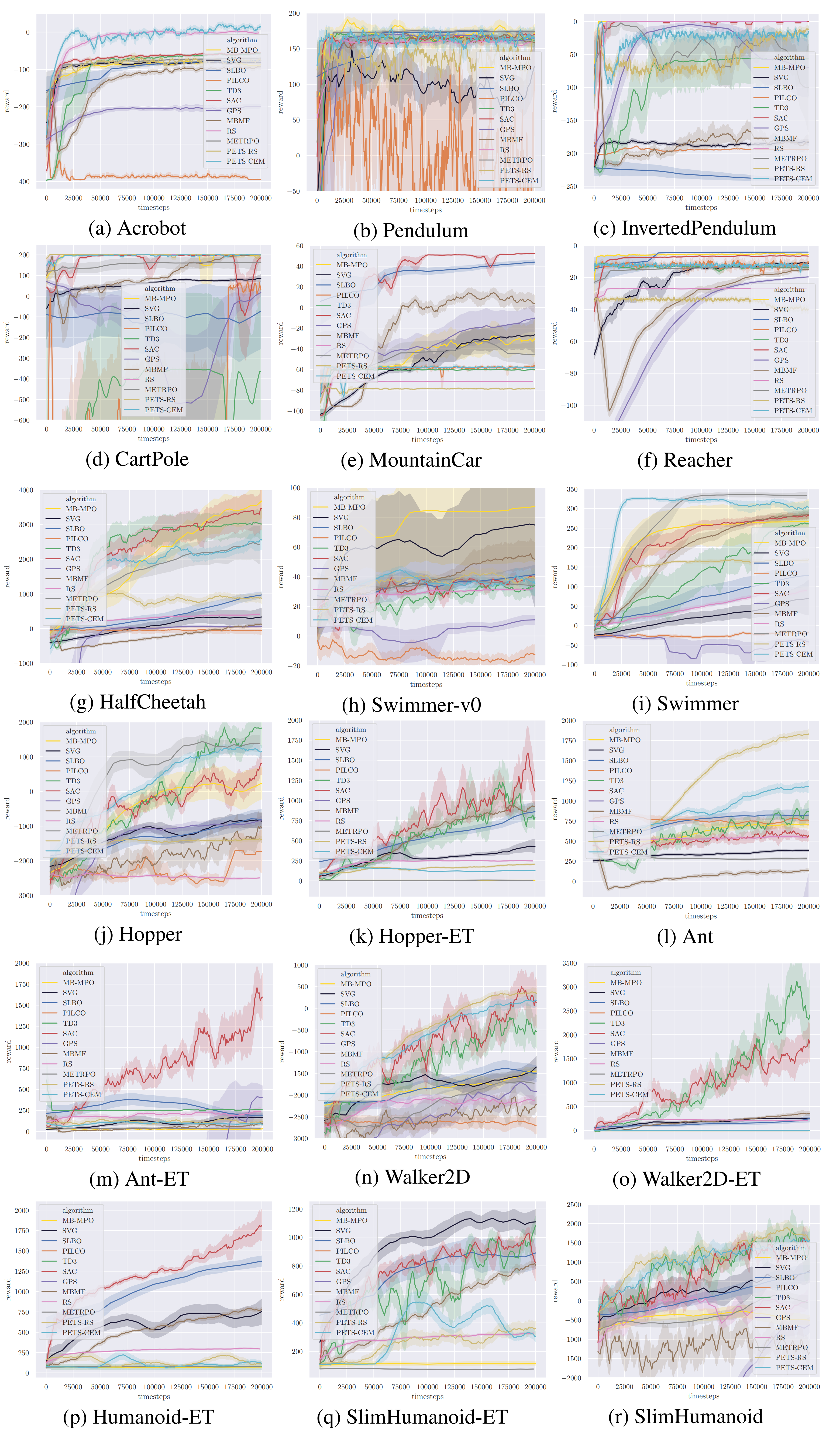
What it says
Reinforcement learning algorithms are often partitioned into two categories: model-free RL and model-based RL. Model-free algorithms such as Rainbow or Soft Actor Critic (SAC) can achieve great performance in diverse tasks, but only at the expense of high sample complexity. Model-based algorithms use a model of the environment to lower sample complexity but suffers in performance due to “model-bias”, a phenomenon where policies are trained to exploit the inaccuracies of the environment model. Various methods have been proposed to mitigate this model-bias phenomenon, and recent model-based algorithms yielded results competitive to their model-free counterparts. Yet, it is difficult to measure progress in the field of model-based RL due to the lack of standardization of results. Different papers use different environments, different preprocessing techniques, and different rewards, making it impossible to compare them directly.
Thus, the authors benchmark 11 model-based algorithms and 4 model-free algorithms across 18 environments. The authors categorize the model-based algorithms into three categories: Dyna-style algorithms (Section 3.1), Policy Search with backpropagation through time (Section 3.2), and Shooting algorithms (Section 3.3). For each algorithm, the authors analyze its performance (Section 4.3) and its robustness to noisy observations or actions (Section 4.4). The authors come to a conclusion that there is no clear winner yet in the field of model-based RL (Table 5).
The authors also hypothesize three main causes of performance degradation: dynamics bottleneck, planning horizon dilemma, and early termination dilemma. Dynamics bottleneck is a problem where model-based RL are more prone to plateau in local minimas that their model-free counterparts (Section 4.5). Planning horizon dilemma is a dilemma where increasing the horizon in one hand allows for better reward estimation, but on the other hand decreases performance due to the curse of dimensionality (Section 4.6, Appendix F). Finally, the early termination dilemma is a problem that most early termination cannot be used successfully with model-based RL methods (Section 4.7, Appendix G).
Read more
- Benchmarking Model-Based Reinforcement Learning (Website)
- Benchmarking Model-Based Reinforcement Learning (ArXiv Preprint)
External resources
- Dyna-Style Algorithms
- Policy Search with Backpropagation through Time
- PILCO: A Model-Based and Data-Efficient Approach to Policy Search (PDF): PILCO
- Synthesis and Stabilization of Complex Behaviors through Online Trajectory Optimization (PDF): iLQG
- End-to-End Training of Deep Visuomotor Policies (ArXiv Preprint): GPS
- Learning Continuous Control Policies by Stochastic Value Gradients (ArXiv Preprint): SVG
- Shooting Algorithms
- A Survey of Numerical Methods for Optimal Control (PDF): RS
- Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning (ArXiv Preprint): MB-MF
- Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models (ArXiv Preprint): PETS-RS, PETS-CEM
- Model-free Baselines
- Trust Region Policy Optimization (ArXiv Preprint): TRPO
- Proximal Policy Optimization Algorithms (ArXiv Preprint): PPO
- Addressing Function Approximation Error in Actor-Critic Methods (ArXiv Preprint): TD3
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor (ArXiv Preprint): SAC
Benchmarking Bonus-Based Exploration Methods on the Arcade Learning Environment
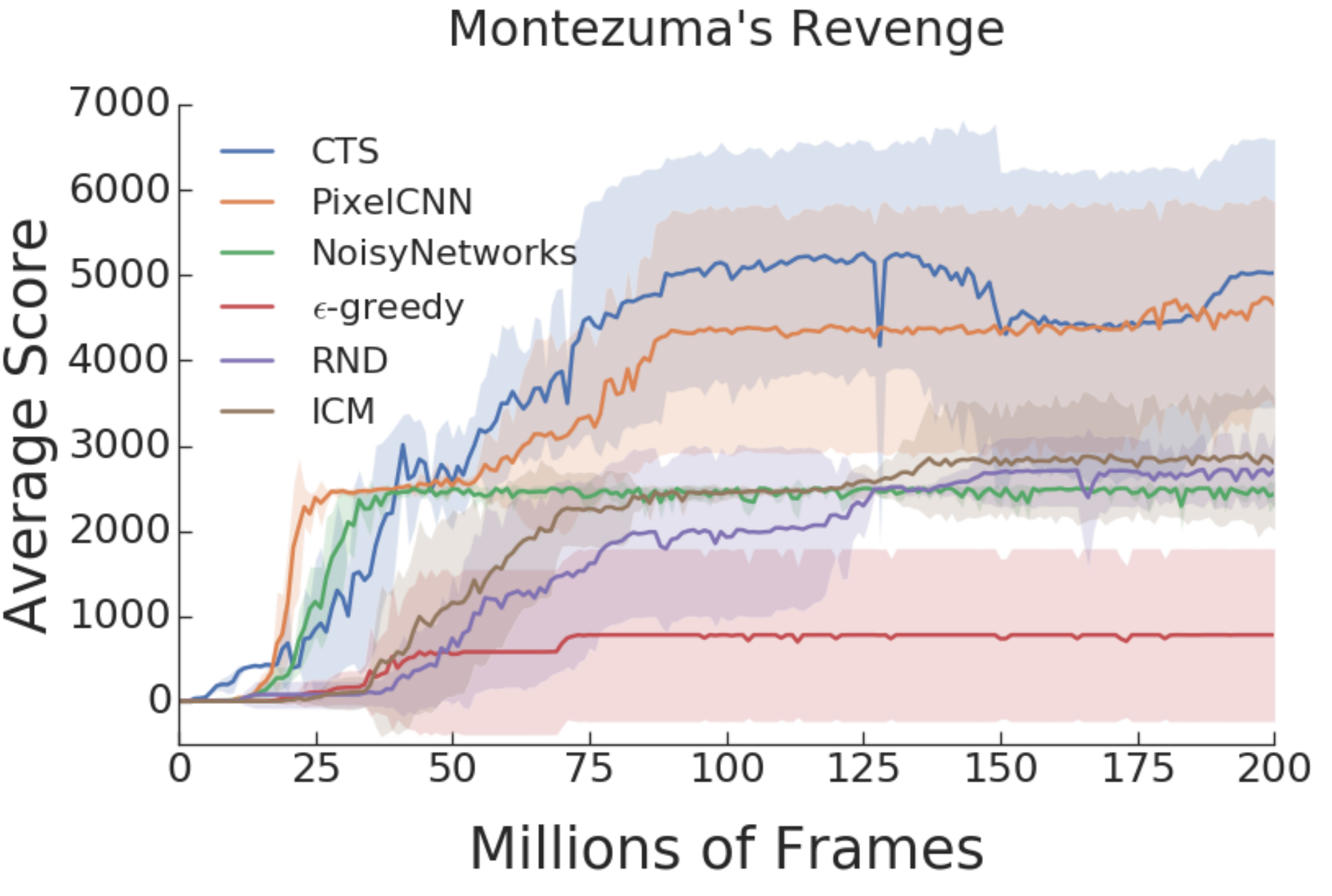
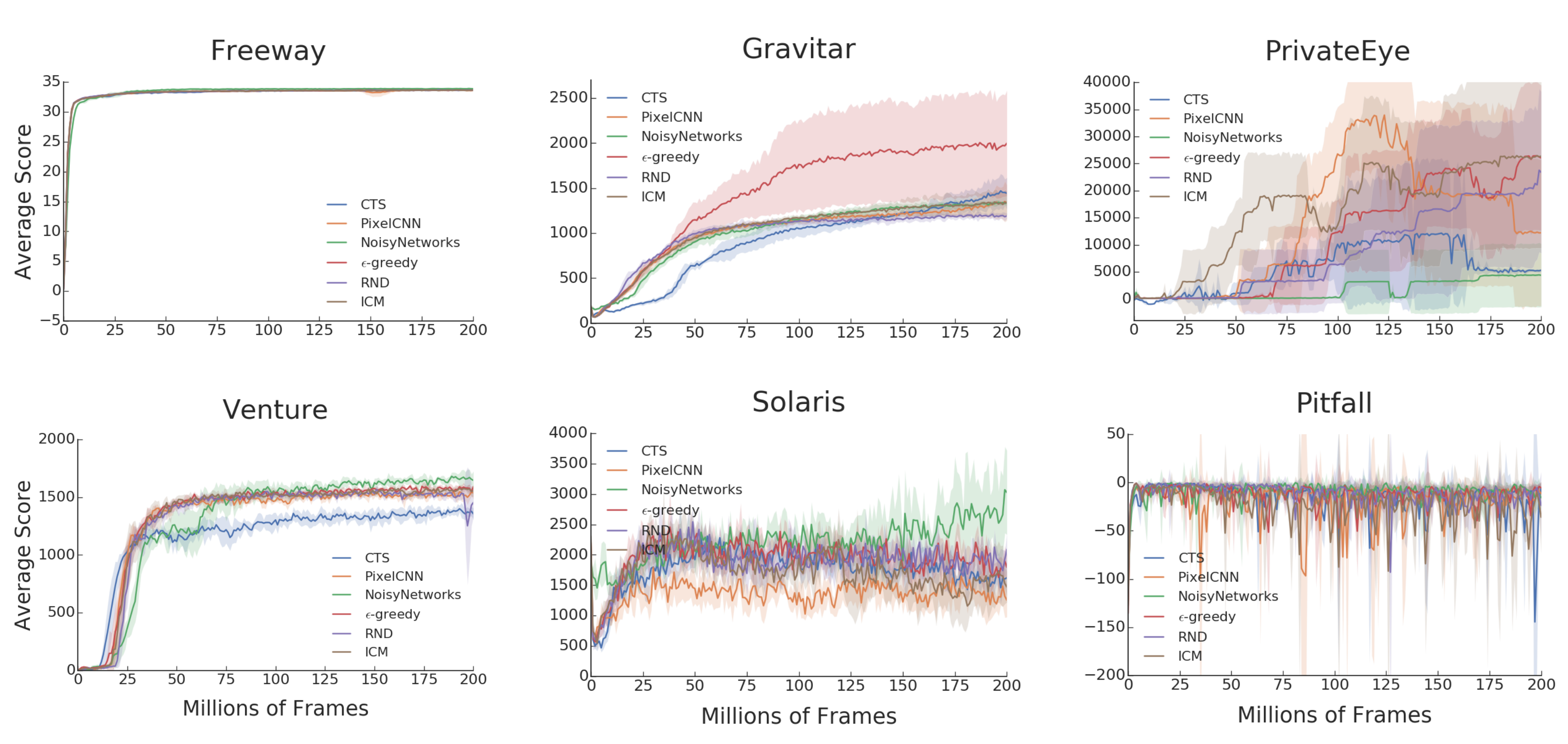
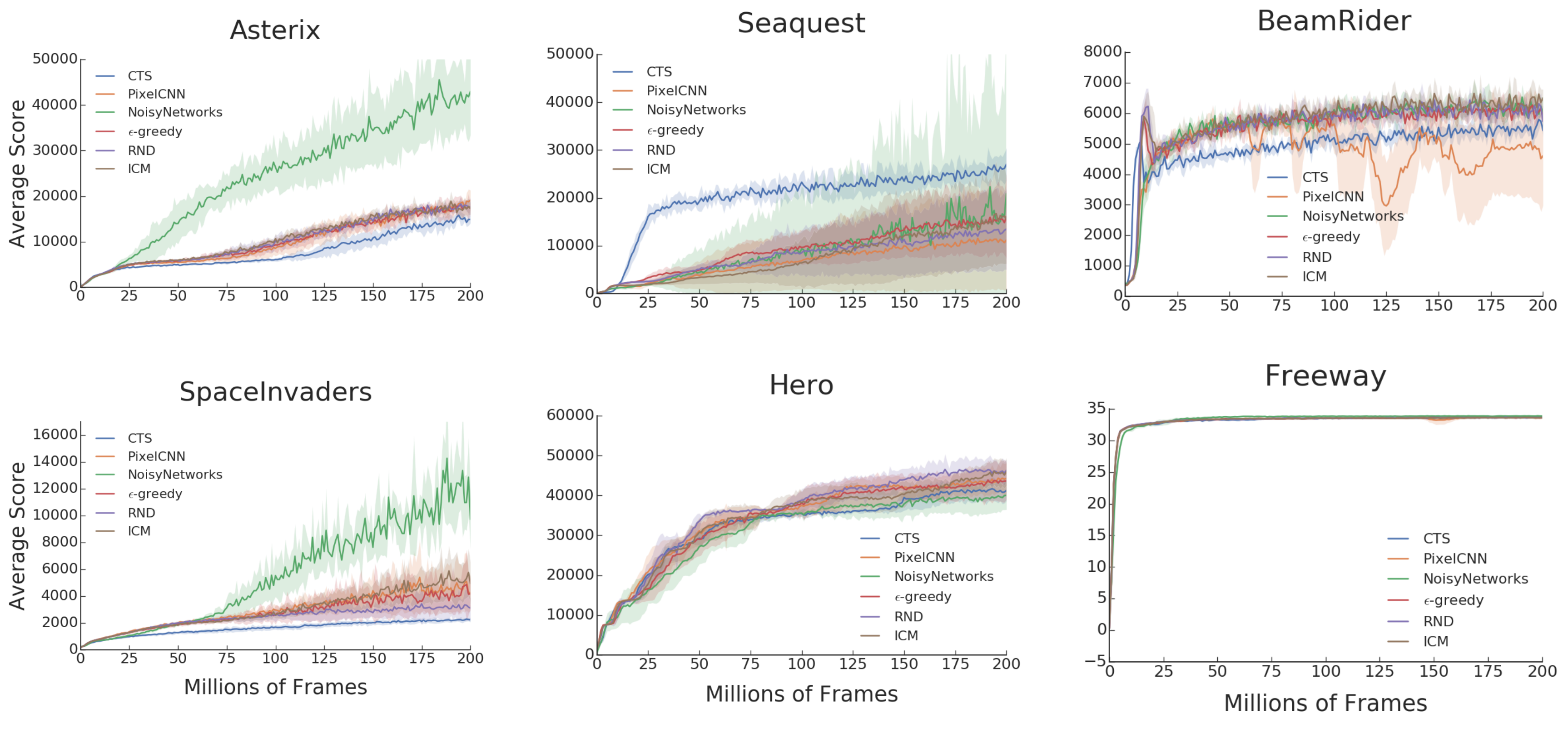
What it says
Recently, various exploration methods have been proposed to help reinforcement learning agents perform well in “hard exploration games” such as Montezuma’s Revenge. Among them are bonus-based methods, where the “extrinsic” reward given by the environment is augmented by an “intrinsic” reward computed by the agent. In recent years, various intrinsic rewards have been proposed, including pseudo-counts through density models (CTS, Bellemare et al. 2016; PixelCNN, Van den Oord et al., 2016), Intrinsic Curiosity Module (ICM, Pathak et al., 2017), and Random Network Distillation (RND, Burda et al., 2019).
Although these papers report their performances, it is difficult to compare them due to several discrepancies. Pseudo-count-based intrinsic rewards were tested with Deep Q-Networks (DQNs), whereas ICM and RND were tested with Proximal Policy Optimization (PPO). They also use different hyperparameters such as the number of frames, the number of random seeds, or discount factors.
Thus, to allow for direct comparison, the authors fixed these discrepancies and trained these methods. The authors used Dopamine-style Rainbow, which is an upgraded version of DQN with prioritized experience replay, n-step learning, and distributional RL. The authors also recorded the performance of an epsilon-greedy agent and NoisyNet agent to serve as baseline methods.
The authors report that on Montezuma’s Revenge (top figure), pseudo-counts (CTS, PixelCNN) outperformed newer algorithms (ICM, RND). Surprisingly, the authors also report that for other Atari games, no bonus-based methods outperform the baselines methods: epsilon-greedy and NoisyNet. This is both the case for games labelled as “hard exploration games” (next six figures) and “easy exploration games” (last six figures).
Read more
External resources
- Dopamine (GitHub Repo)
- Noisy Networks for Exploration (ArXiv Preprint): NoisyNet
- Unifying Count-Based Exploration and Intrinsic Motivation (ArXiv Preprint): CTS
- Count-Based Exploration with Neural Density Models (ArXiv Preprint): PixelCNN
- Curiosity-driven Exploration by Self-supervised Prediction (ArXiv Preprint): ICM
- Exploration by Random Network Distillation (ArXiv Preprint): RND
One-line introductions to some more exciting news in RL this week:
- SLAC: By learning a compact latent representation space and learn a critic model in this latent space, this model-free algorithm can achieve sample efficiency competitive to model-based algorithm!
- DADS: An agent can discover diverse skills without any extrinsic reward, and model predictive control can compose these skills to solve downstream tasks without additional training!
- MULEX: Using multiple Q-networks for each extrinsic or intrinsic reward to disentangle exploration and exploitation gives better performance than using a single Q-network in Montezuminha, a grid world version of Montezuma’s Revenge!
- MoPPO: Combining Modified Policy Iteration (MPI) with PPO soft greediness for performance competitive to state-of-the-art (Soft Actor Critic)!
- QRDRL: Quantile Regression can be used in environments with continuous action-spaces too, and is competitive to PPO and N-TRPO on MuJoCo environments!