Free-Lunch Saliency via Attention in Atari Agents

What it says
To interpret Deep RL agents, saliency maps are commonly used to highlight pixel areas that the agent deemed important. There are two ways to generate such map: post-hoc saliency method and built-in saliency method. Post-hoc saliency method reserves interpreting the agent after the training is complete, whereas built-in saliency methods use specific models that improve interpretability (Section 2). This work focuses on the built-in methods.
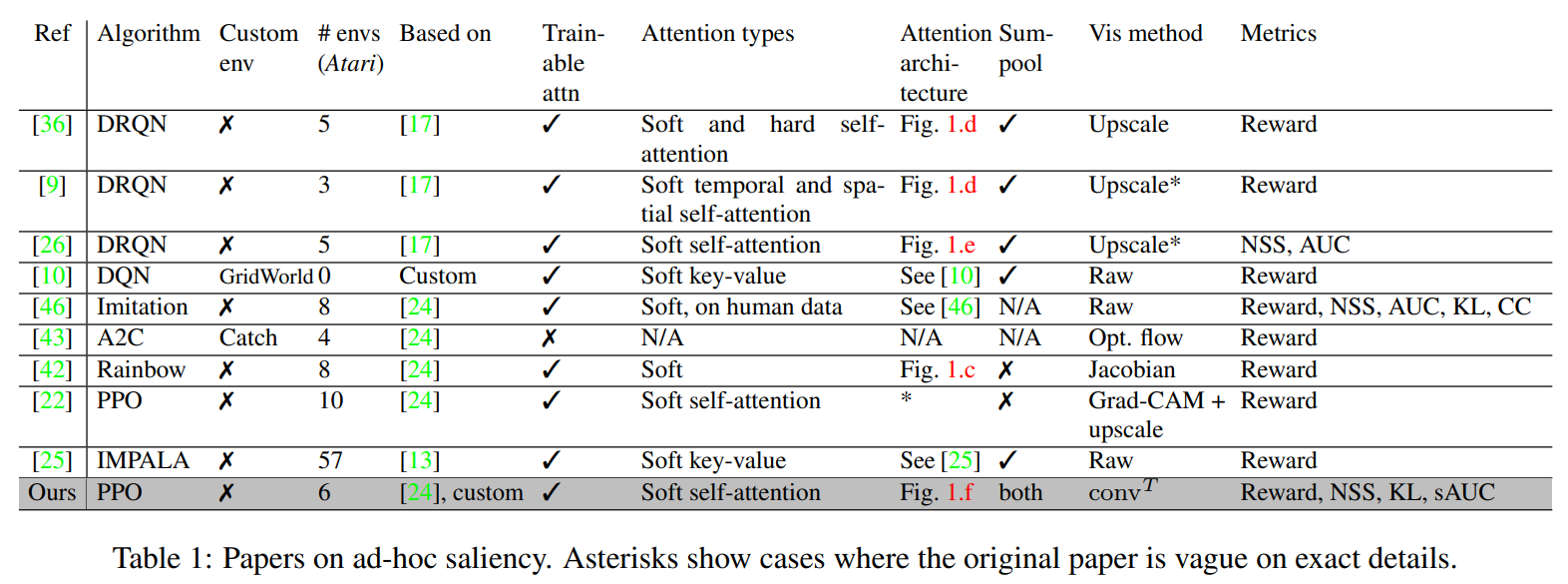
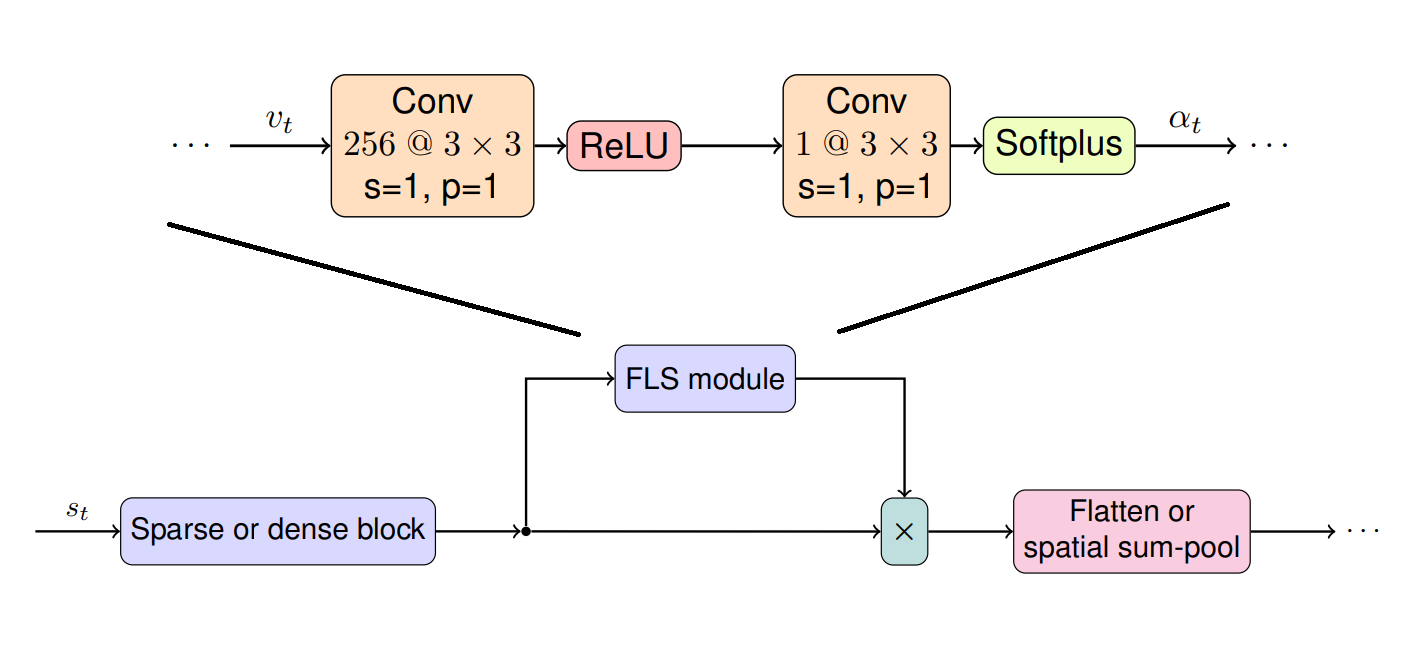
As shown in Table 1 above, there has been multiple works on built-in methods, but these methods have worse performance compared to their non-interpretable versions. The authors propose a new method named Free-Lunch Saliency, claiming that the interpretability comes “free” without the performance drop. The FLS module is situated between the convolutional layers and the fully connected layers.
For the performance, the authors run experiments on 6 Atari environments and verify that Sparse FLS does not lead to a performance drop (Section 4.2, Table 2). The authors show that having smaller receptive fields and strides allows for crisper saliency maps (Dense FLS). However, it also increases more memory and necessitates sum-pooling. The authors report this leads to a significantly worse performance.
For the quality of interpretability, the authors also compare the saliency maps generated by various built-in methods using the Atari-HEAD human dataset. The authors note that although no method clearly dominates others, they all perform better than random (Section 4.3).
Read more
- Free-Lunch Saliency via Attention in Atari Agents (ArXiv Preprint)
- Free-Lunch Saliency via Attention in Atari Agents (GitHub Repo)
- Free-Lunch Saliency: Breakout, MsPacman, SpaceInvaders, Enduro, Seaquest (YouTube Video)
External resources
- Learn to Interpret Atari Agents (ArXiv Preprint): Region Sensitive Rainbow (RS-Rainbow)
- Atari-HEAD: Atari Human Eye-Tracking and Demonstration Dataset (ArXiv Preprint)
Hierarchical RL with Behavior Cloning
What it says
Imitation learning methods learn to solve a task through demonstrations. Although it is efficient for learning short trajectories with limited variability, the agent struggles when it observes states not seen in the demonstration. Reinforcement learning is able to learn without such demonstration dataset and generalizes better. However, it is not sample efficient since it relies on exploration to generalize.
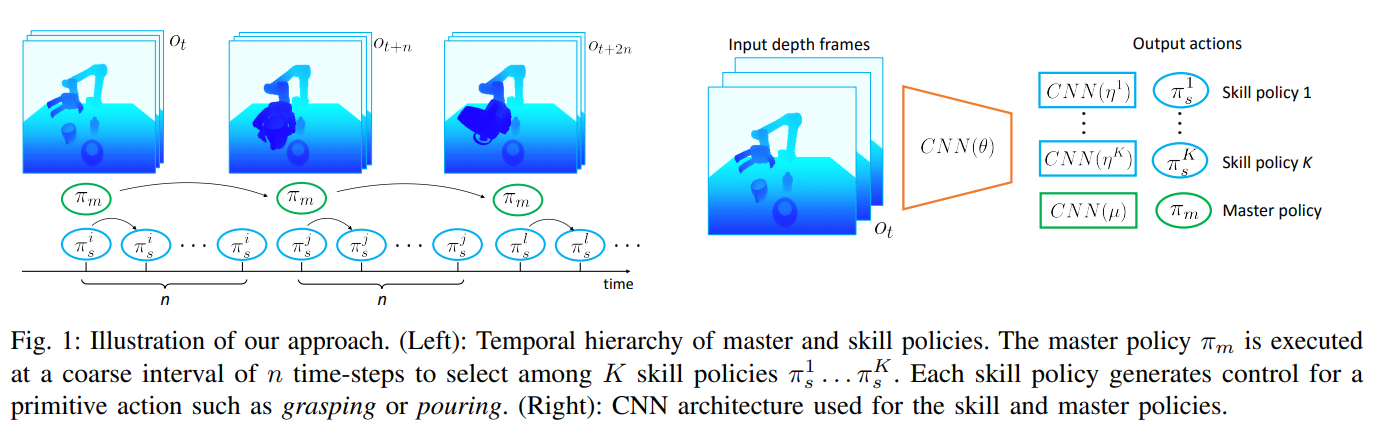
To get the best of both worlds, the authors propose HRL-BC, a method of combining imitation learning and reinforcement learning through hierarchical RL (HRL). First, the agent learns primitive skill policies through behavior cloning (BC) (Section 3.A). Afterwards, the agent trains a master policy through Proximal Policy Optimization (PPO) that selects actions at a slower rate (Section 3.B).
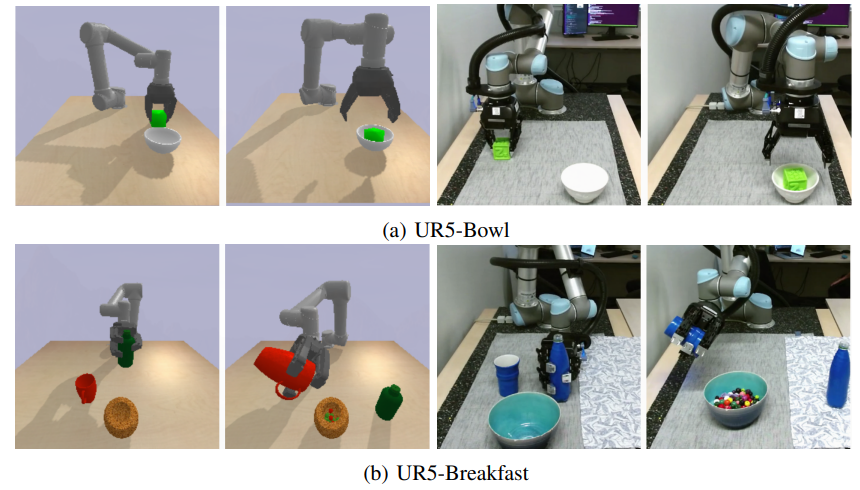
The authors test their HRL-BC approach on both simulated and real robot arms (UR5). The authors report that the agent was able to learn skills quickly through behavior cloning with ResNet architecture and data augmentation (Section 4). Furthermore, HRL-BC shows superior success rate to methods that use only imitation learning or reinforcement learning (Section 5.B).
Read more
One-line introductions to more exciting news in RL this week:
- Deep RL in System Optimization A paper studying the efficacy of deep RL methods in various system optimization problems!
- DoorGym A new robot control environment, where the agent needs to open a door!
- Weight Agnostic NN The code for Weight Agnostic Neural Network (WANN) was released on GitHub!
- Learn to Move: Walk Around This NeurIPS 2019 competition offers $200 Google Cloud credit to first 200 submissions!
- Genetically Generated Macro Actions: Make macro action construction independent by using genetic algorithms instead of past policy!