Behavior Suite for RL
What it says
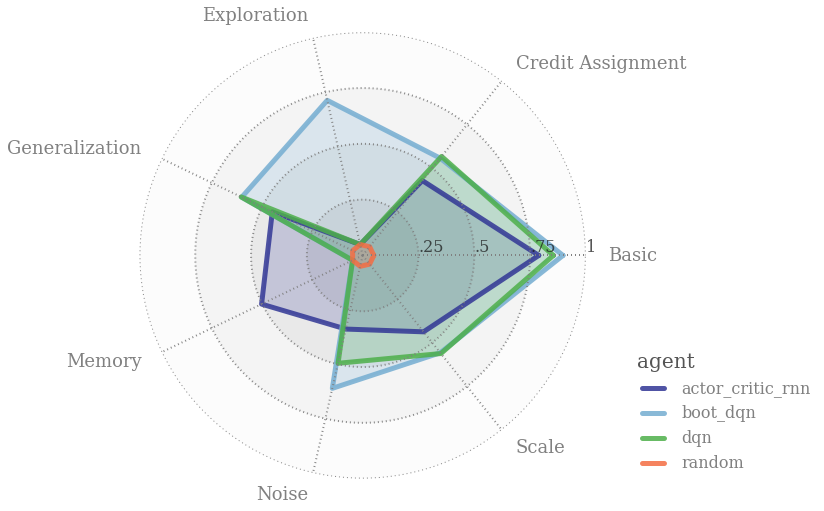
A “good” RL agent might not be the agent that simply has the best score on a certain environment. An efficient RL algorithm must handle the various challenges the RL framework gives:
- Generalization from collected data
- Eexploration-exploitation tradeoff
- Long-term planning
It is difficult to assess these features of an agent in a separated setting. For this reason, the authors created bsuite, a collection of diagnostic experiments to analyze the capabilities of RL agents and provide insight.
In bsuite, Each environment is designed to measure the agent’s capabilities on a certain issue. It is designed to be challenging enough to push agents beyond their capabilities, while being simple enough to be able to focus on key issues. As a benchmark, these environments are also fast and scalable.
The authors emphasize that bsuite will be continuously developed, with new experiments added from the research community.
Read more
- Behaviour Suite for Reinforcement Learning (ArXiv Preprint)
- bsuite - Behaviour Suite for Reinforcement Learning (GitHub Repo)
“Superstition” in the Network
What it says
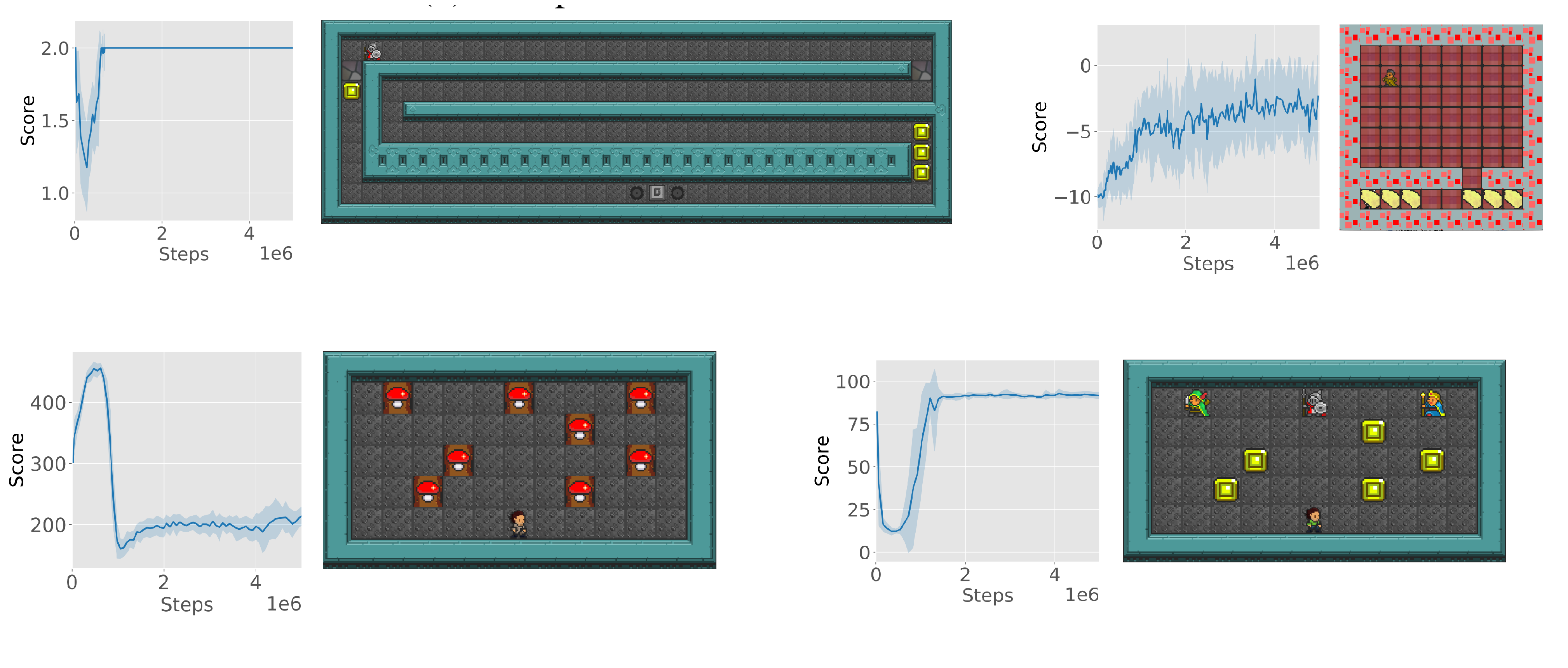
Deep RL agents have been successful in a lot of games, yet it still fails on many games. To characterize the environments that “trick” the agent well, the authors present four “deceptive” games, each with a different type of deception.
The first is DeceptiCoins (Top left). The agent can choose between two paths: left and right. The left path has an earlier but smaller reward, and the right path has delayed but greater reward. This is the classical exploration vs. exploitation problem.
The second is WaferThinMints (Top right), the “Subverted Generalization” problem. The agent is rewarded for collecting mints, but after collecting 9 mints, the agent is penalized for collecting mints. The agent can check the number of mints collected through a small green bar that follows the agent. The agent is deceived to conclude that collecting mints are good, but the expectation is betrayed on the 10th mint.
The third is Flower (Bottom left), the “Delayed Reward” problem. The agent supervises a field with flower seeds that grow into flowers, and the agent is given higher reward for flowers than seeds. The optimal agent should wait until the flower is fully grown, then harvest it quickly.
The fourth is Invest (Bottom right), the “Delayed Gratification” problem. The agent can invest their reward, incurring a penalty, to receive greater reward after some time.
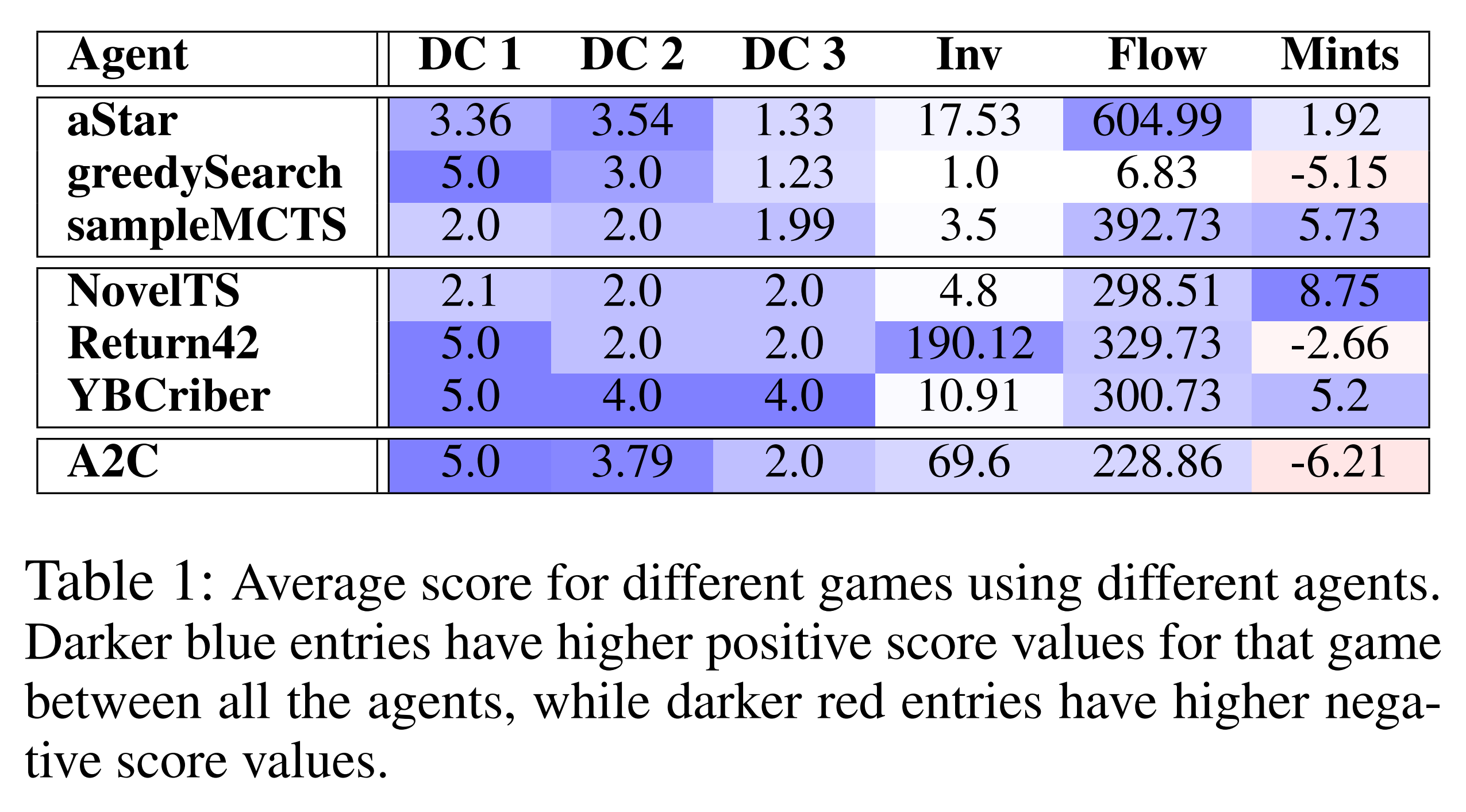
As shown in the table above, the A2C agent fails to learn optimal behavior in many environments.
(The authors examine in great detail how an A2C agent and various planning agents act throughout training. Try formulating a hypothesis about each learning curve, and read their explanation to see if you are correct!)
Read more
External resources
Is Deep RL Really Superhuman on Atari?
What it says
Since Deep Q-Networks (DQN) and its various improvements (namely Rainbow and IQN), the Atari environments provided via the Arcade Learning Environment (ALE) has been labeled as “solved,” with the agents performing in “superhuman” levels in most. The authors propose a benchmark SABER (Standardized Atari BEnchmark for RL) following the advice of Machado et al. about evaluations in ALE (2017). The recommendations are (1) adding stochasticity through “sticky actions,” (2) ignoring the loss of life signal, (3) using the full action space of 18, and (4) averaging performances over 100 episodes.
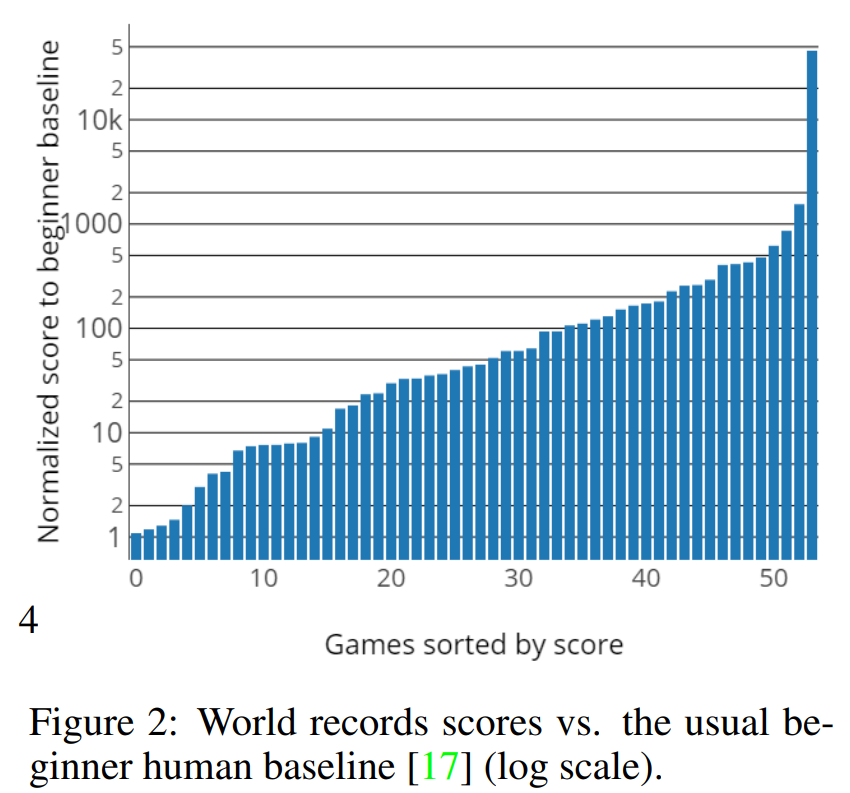
The authors also argue that following other RL works such as AlphaGo, AlphaStar, and OpenAI Five, the Atari agents should be compared against the world’s best humans. Thus, the authors compile a human world records baseline. With Rainbow and their own Rainbow-IQN, they show that RL agents only outperform the best human scores in only 3 or 4 games.
Read more
External resources
One-line introductions to more exciting news in RL this week:
- Review of Cooperative MARL: A review of cooperative multi-agent deep RL.
- Review on Deep RL for Fluid Mechanics: What deep RL algorithms have been used in fluid mechanics?
- Reward Function Tampering: How can we assure that the agent reward corresponds to user utility? In other words, how can we prevent agents achieving high rewards without performing wanted tasks?
- Manipulation via Locomotion: Train hierarchical RL where low-level locomotive skills are used for high-level object manipulation. This policy can then be transferred to the real world with zero real world training.