Notice
Thank you for reading RL Weekly. I created a Google Form to make it easier to leave feedback. Please feel free to leave any feedback!
Next week, I will be flying back to Princeton to finish my bachelor’s degree, so issue #31 could be delayed. I hope to bring you more exciting news in reinforcement learning in the future!
- Ryan
Dynamics-aware Embeddings
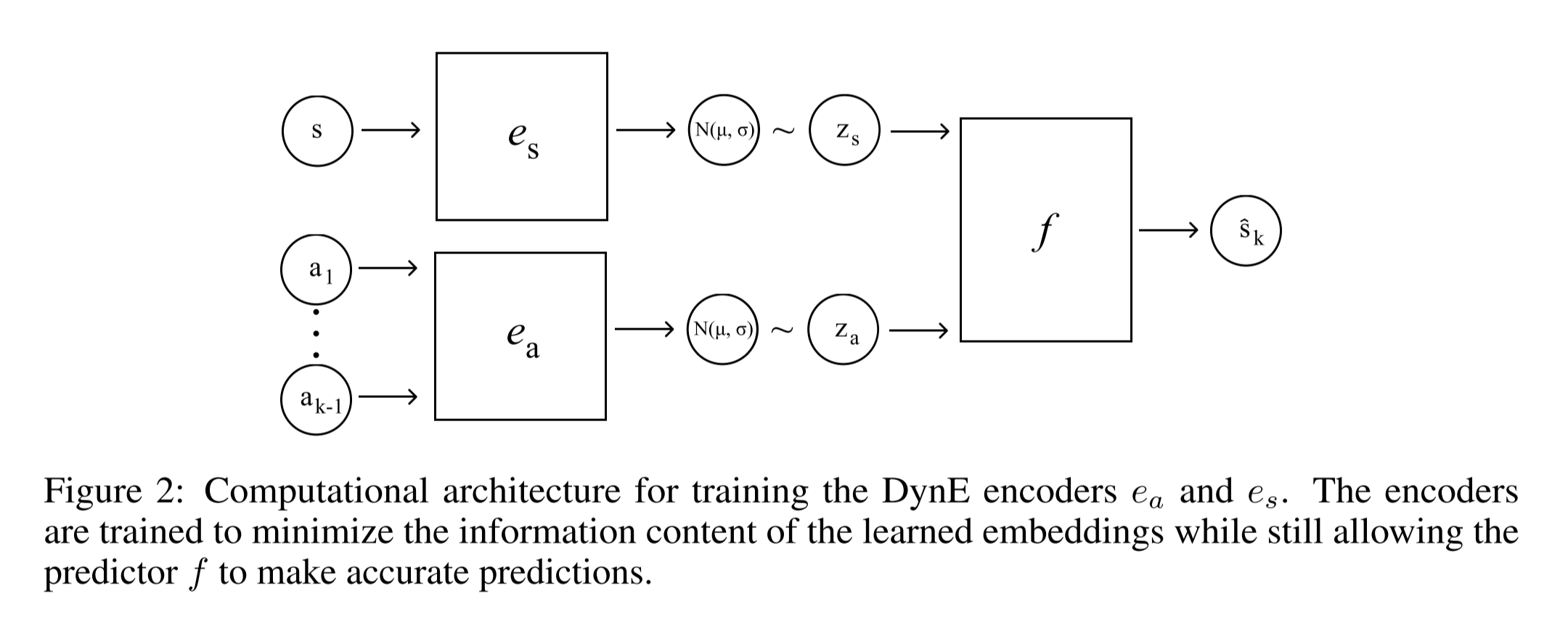
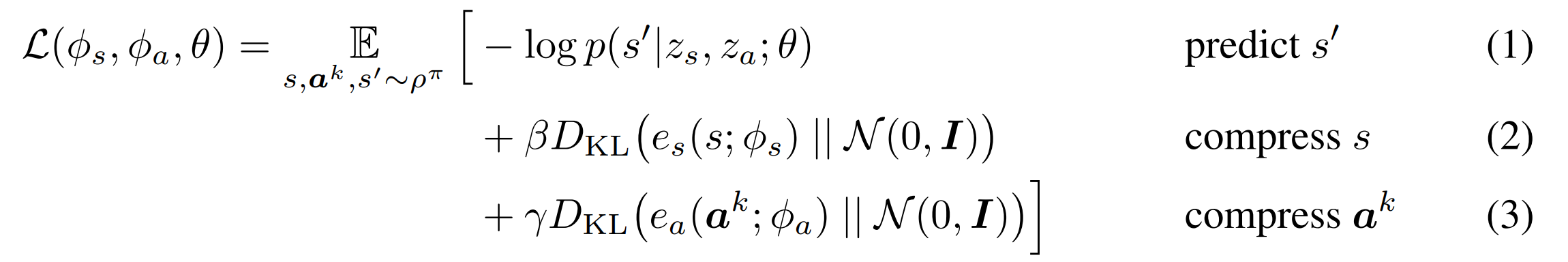
What it says
“The intuition is simple: preserve as much information as possible about the *outcomes* of a state or action while minimizing its description length. This leads to embeddings with smooth structure that make it easy to do RL.” - William Whitney, the first author.
Most popular RL algorithms are trained end-to-end: the convolutional layers that extract features are trained with the fully connected layers that choose action or estimate values. Instead of this end-to-end approach, the authors propose a new representation learning objective DynE (Dynamics-Aware Embedding). DynE learns a state encoder and an action encoder by maximizing a variational lower bound (Section 2.2), then learns an action decoder that produces low-level action sequence from a high-level action (Section 3.1). With a simple modification (Section 3.2), DynE can be used with TD3 (Twin-delayed DDPG).
DynE-TD3 is tested with Reacher and 7DoF tasks from MuJoCo. DynE-TD3 learns faster that other baselines (PPO, TD3, SAC, and SAC-LSP) and its action representations are transferable to similar environments (Page 8, Figure 4). The authors also compare using just the state embedding (S-Dyne-TD3) and using both embeddings (SA-Dyne-TD3). In simpler environments, both achieve similar performance, but SA-Dyne-TD3 shines in harder environment. Both perform better than TD3 and VAE-TD3 (Page 9, Figure 5).
Read more
External resources
- [PPO] Proximal Policy Optimization Algorithms
- [TD3] Addressing Function Approximation Error in Actor-Critic Methods
- [SAC] Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
- [SAC-LSP] Latent Space Policies for Hierarchical Reinforcement Learning
OpenSpiel: A Framework for Reinforcement Learning in Games
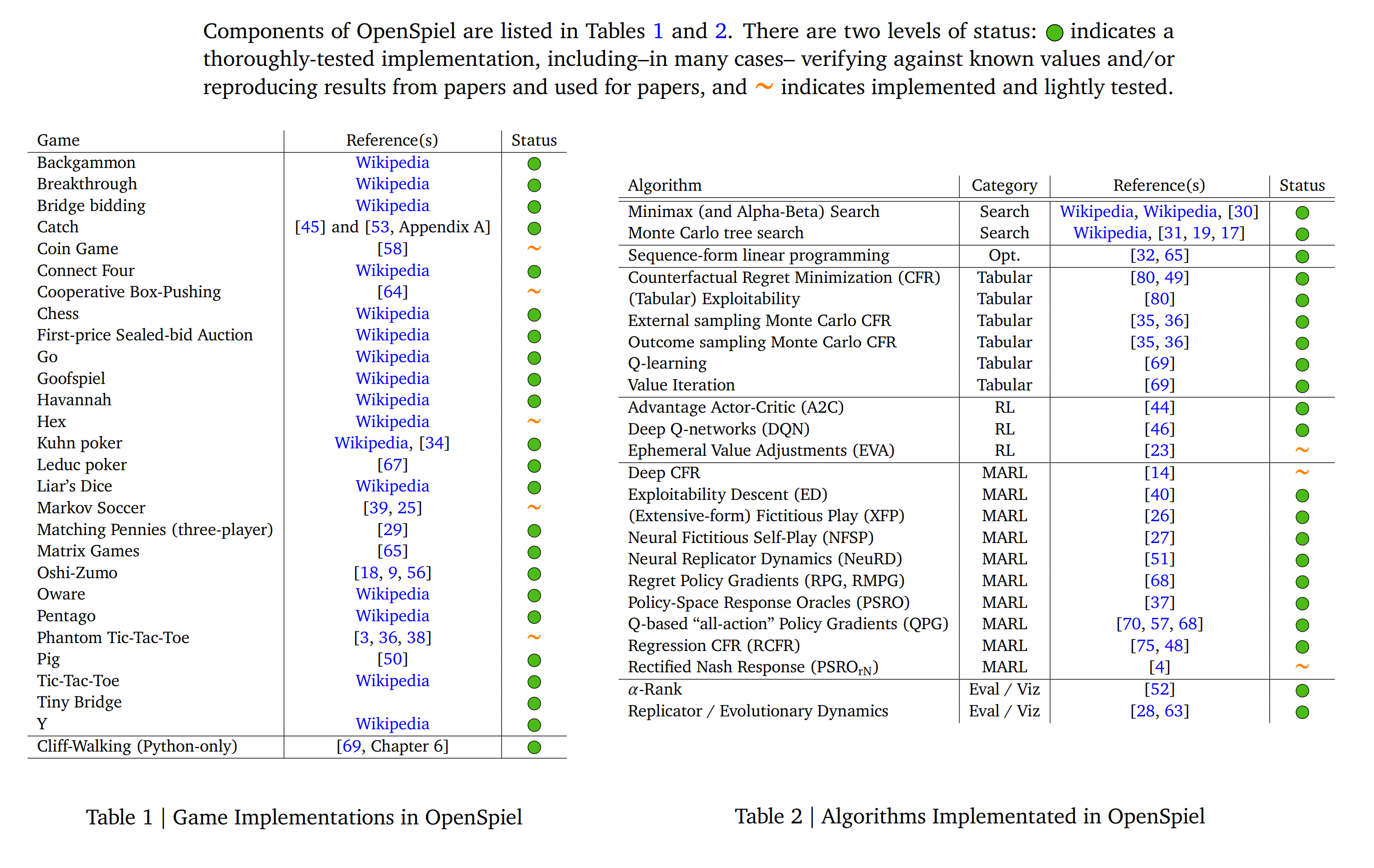
What it says
“OpenSpiel is a collection of environments and algorithms for research in general RL and search/planning in games.” It contains 28 environments (shown above) that have various different properties: perfect or imperfect information, single-agent or multi-agent, etc. It also contains 22 baseline algorithms that spans a wide field of RL such as tree search, tabular RL, deep RL, and multi-agent RL. The environments are implemented in C++ and wrapped in Python, and algorithms are implemented in either C++ or Python. For visualization and evaluation of multi-agent RL, OpenSpiel offers phase portraits (Section 3.3.1) and $\alpha$-Rank (Section 3.3.2).
Read more
- ArXiv Preprint
- GitHub Repository
- Reddit Discussion (r/reinforcementlearning)
- Twitter Thread by Marc Lanctot (First author)
External resources
Interactive Machine Reading Comprehension

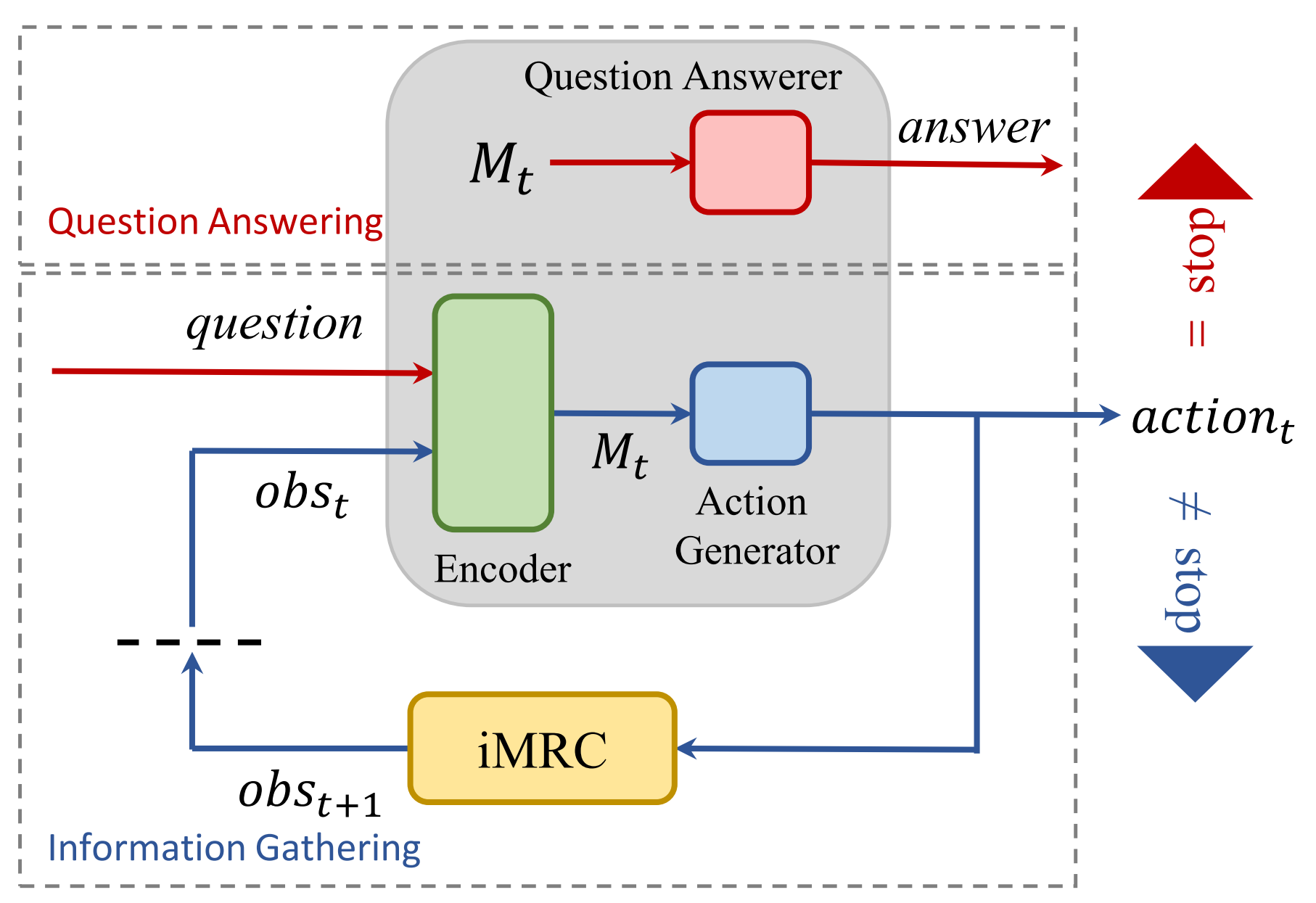
What it says
Question Answering (QA) is a problem where the model must output a correct answer given a question and a supporting paragraph containing the answer. In the web, the text to search the answer for could be very large, so the authors instead propose an “interactive” variant. Unlike the default “static” situation where the full text is given, in the interactive variant only a part of the text is given and the agent must select actions to discover sentences with relevant information. During this information gathering phase, the agent can choose to move to the previous or next sentence, to jump to a next occurrence of a token (i.e. Ctrl+F), or to stop. When a stop action is given, the agent enters the question answering phase in which it outputs the head and tail position of the answer in the supporting text.
The authors build interactive versions of SQuAD v1.1 and NewsQA and test their methods and report F1 scores of 0.666 for iSQuAD and 0.367 for iNewsQA (best numbers among variants, Table 4). The authors also report 0.716 and 0.632 for the “F1 info score,” which only tests whether the agent stopped at the correct segment of the text during the information gathering phase.
Read more
External resources
- SQuAD Leaderboard: XLNet F1 95.080, Human F1 91.221
- [SQuAD] ArXiv Preprint
- [NewsQA] ArXiv Preprint
More exciting news in RL this week:
Algorithms
- KNN-based Continuous Value Iteration with “Imaginary” Data Augmentation
- Transfer Learning in Text Adventure Games using Knowledge Graphs
Survey of…
Applying RL for: