SimPLe: Sample-efficient Near-SOTA Model-based RL
What it is
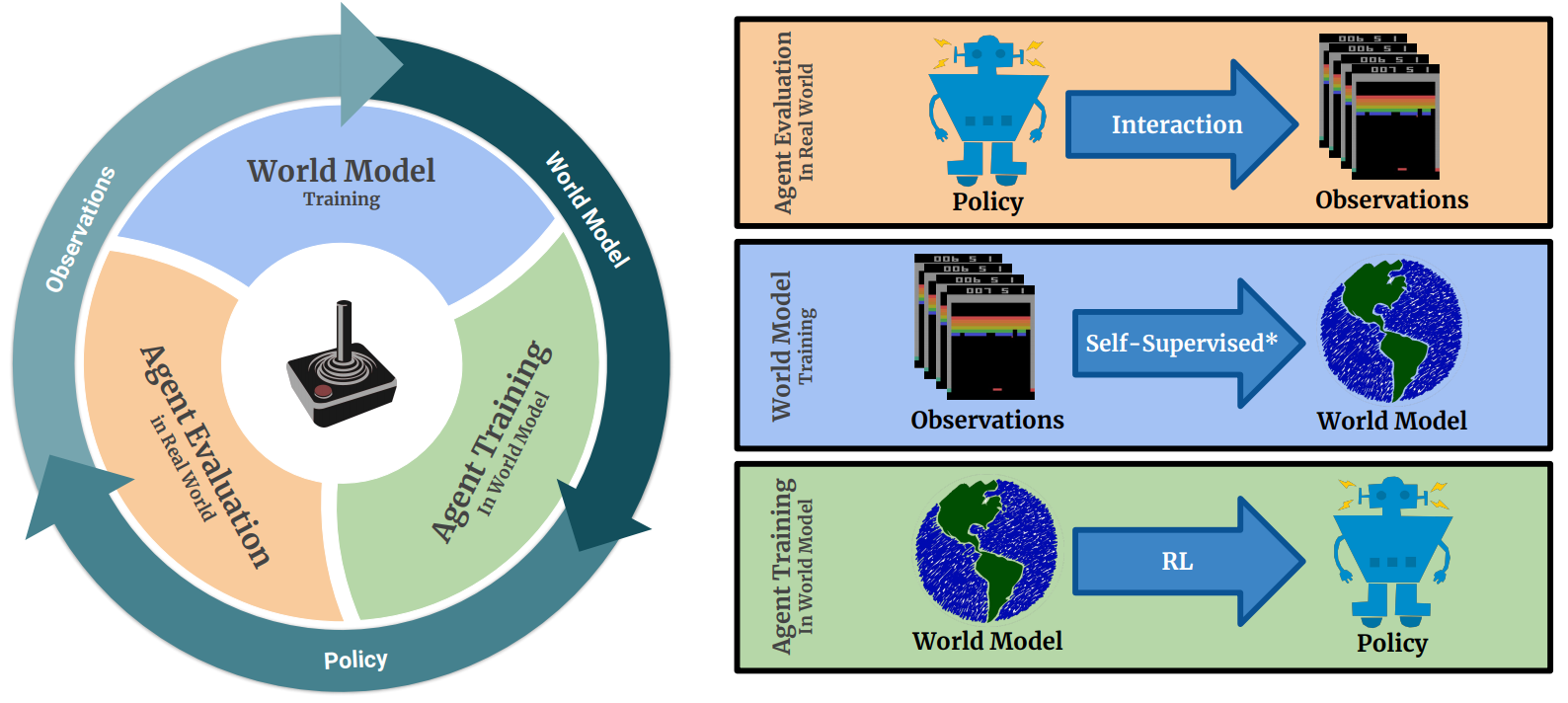
Researchers at Google Brain, UIUC, University of Warsaw, and deepsense.ai proposed a model-based deep RL algorithm called SimPLe (Simulated Policy Learning) and a novel world model architecture that achieves competitive results to Rainbow (Hessel et al., 2017) and PPO (Schulman et al., 2017) while being drastically more sample-efficient. SimPLe has a main loop that consists of three phases: agent evaluation, model training, and agent training. In the Agent Evaluation phase, the agent interacts with the real environment through its policy, aggregating data about the environment. In the Model Training phase, the model is improved using the aggregated data. Finally, in the Agent Training phase, the agent improves its policy by interacting with the model. The researchers also designed a novel neural network architecture with variational autoencoder (VAE) and discrete latent variable to include stochasticity to the world model.
Why it matters
Model-based RL has been a hot topic of research due to its sample efficiency. However, existing model-based algorithms failed to achieve state-of-the-art results by model-free RL algorithms. This paper shows that by designing the world model carefully, model-based RL can achieve competitive results.
Read more
- Model-Based Reinforcement Learning for Atari (ArXiv Preprint)
- Model-Based Reinforcement Learning for Atari (Google Sites)
External Resources
- Rainbow: Combining Improvements in Deep Reinforcement Learning (ArXiv Preprint; Rainbow)
- Proximal Policy Optimization Algorithms (ArXiv Preprint; PPO)
Neural MMO: MMO Multiagent Environment

What it is
Researchers at OpenAI showcased a new multiagent environment motivated by MMORPG (Massively Multiplayer Online Role-Playing Games) genre. In this Neural MMO environment, the agent must learn robust combat and navigation policies in the presence of numerous other agents with the same goal. The authors found that as the number of concurrent agent increases, the overall exploration increases, and the agents “specialize” on one aspect to avoid competition.
Why it matters
The emergence of complex life in the real world can be attributed to various life forms competing for finite amount of resources. The aim of Neural MMO is “to develop a simulation platform that captures important properties of life on Earth while also borrowing from the interpretability and abstractions of human-designed games.” It is interesting to see how the behavior of the trained agents resemble that of humans.
Read more
- Neural MMO: A Massively Multiagent Game Environment for Training and Evaluating Intelligent Agents (Paper)
- Neural MMO - A Massively Multiagent Game Environment (OpenAI Blog)
- Neural MMO (GitHub Repo)
- Neural MMO Client (GitHub Repo)
Diagnosing Bottlenecks in Deep Q-Learning Algorithms
What it is
Researchers at BAIR devised a “unit testing” framework to disentangle sources of error in Deep Q-learning algorithms to perform a “controlled analysis of different sources of error.” For analysis, they use variants of Fitted Q-Iteration (FQI) - Exact-FQI, Sampled-FQI, and Replay-FQI - and different weighting distributions for the Bellman error.
The authors conclude that divergence rarely happens in practice but that large architectures are crucial (Section 4.2). Large architectures suffer from more overfitting, which significantly affects the learning process, but they still perform better than small architectures where the bias introduced by the small architecture dominates (Section 5.2). Large architectures are also more stable under fast-changing targets (Section 6.2).
Why it matters
Although tabular Q-learning is well-understood, Q-learning with nonlinear function approximators such as deep neural networks is not well-understood. By classifying possible sources of error, future research can be targeted to mitigate issues that affect performance the most. For example, the authors identify overfitting as a key problem and show that replay buffers and early stopping somewhat reduces overfitting.
Read more
External Resources
Some more exciting news in RL:
- Gu, Ghiassian, and Sutton from University of Alberta showed that Emphatic TD learning converges on on-policy experiments where classic TD diverges or performs poorly.
- Researchers at Google Brain Robotics unveiled PRM-RL, a hierarchical robot navigation method to teach its robots to drive for long ranges while being hindered by noise and obstacles.